Yesterday, Microsoft released SQL Server 2005 Service Pack 3. Reporting Services Report Builder added support with Teradata. Note that some manual configuration is required to turn things ‘on’ as well as you need to install the .Net provider from Teradata.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2008-12-18 13:03:022016-02-17 10:38:11SQL Server 2005 Service Pack 3 is Out
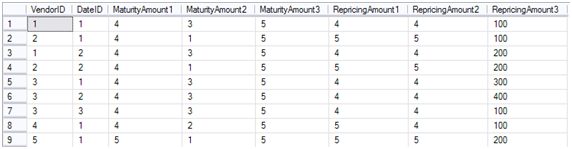
Let’s say you need a way to unpivot the results in the following format which is more suitable for OLAP:
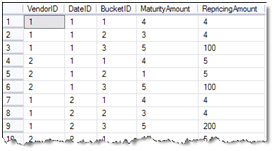
In this way, you eliminate the repeating measure columns with a single column. Here, the BucketID column is introduced so you could join the results to a dimension to let the user cross-tab the results on columns.
Solution
Usually, ETL processes would take care of transforming data in format suitable for analysis especially with large data volumes. However, with smaller fact tables and an OLAP layer directly on top of the operational database, such as having SQL views directly on top of the source database, you may need an ad-hoc approach to unpivot the results. Assuming you are fortunate to have SQL Server 2005 or above, you can use the SQL Server UNPIVOT function to unpivot on multiple columns. The following query does the trick:
SELECT VendorID, DateID, CAST(REPLACE(Maturity, ‘MaturityAmount’, ”) as int) as BucketID,
RepricingAmount1, RepricingAmount2, RepricingAmount3 FROM pvt) p
UNPIVOT
(MaturityAmount FOR Maturity IN (MaturityAmount1, MaturityAmount2, MaturityAmount3)) AS UnPivotedMaturity
UNPIVOT
(RepricingAmount FOR Repricing IN (RepricingAmount1, RepricingAmount2, RepricingAmount3)) AS UnPivotedRepricing
WHERE REPLACE(Maturity, ‘Maturity’, ”) = REPLACE(Repricing, ‘Repricing’, ”)
Notice that a WHERE clause is needed to join the two unpivoted sets so you don’t end up with a Cartesian set. The net result is that the number of rows in the unpivoted dataset is:
Number of Rows in Pivoted (original) Table * Number of Repeated Columns
So, in our case, the dataset will have 9 * 3 = 27 rows.