Happy New Year 2012!
As 2011 is winding down, it’s time to reflect on the past and plan for the future. 2011 has been a very exciting year for Microsoft BI and me.
- Gartner positioned Microsoft as a leader in the 2011 Magic Quadrant for Business Intelligence Platforms.
- Although SQL Server 2012 will technically ship early next year, we can say it’s a done deal as it’s currently in a release candidate phase. The most important news from a BI perspective is the evolution of the Business Intelligence Semantic Model (BISM), which an umbrella name for both Multidimensional and Tabular models.
- The Tabular model provides us with a nice personal (PowerPivot for Excel)-team (PowerPivot for SharePoint)-organizational (Analysis Services Tabular) continuum on a single platform.
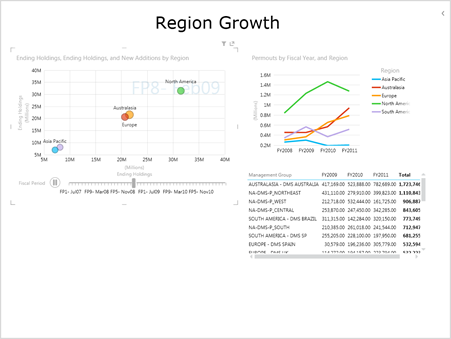
- Power View extends the BI reporting toolset with a sleek web-based reporting tool for authoring highly interactive and presentation-ready reports.
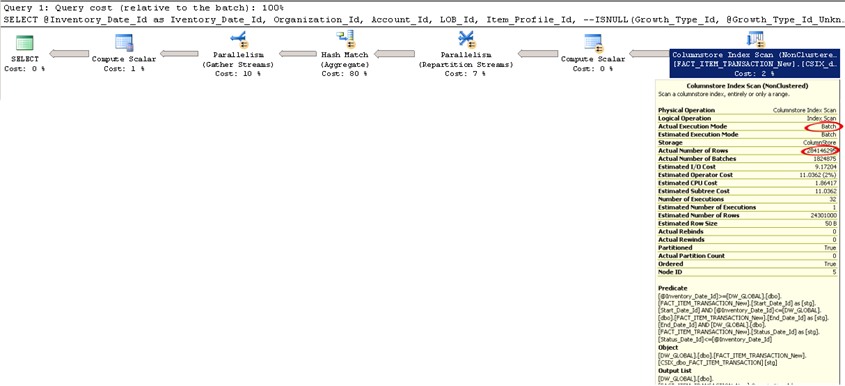
- In its second release, Master Data Services (MDS) comes out of age and now allows end users to use Excel to manage master data. The newcomer, Data Quality Services (DQS), complements MDS nicely in the never-ending pursuit for clean and trusted data. Integration Services has also nice enhancements. Finally, columnstore indexes will help to aggregate large datasets, such as the scenario I mentioned in this blog.
Looking forward to 2012 and beyond, here is my top 5 BI wish list:
- Extending the Tabular capabilities with more professional features, such as scope assignments, role-playing dimensions, MDX query support, and so on, to enhance its reach further in the corporate space. Ideally, I expect at some point in future unification of Multidimensional and Tabular so BI pros don’t have to choose a model.
- Extending Power View to support multidimensional cubes. Further, in the reporting area, I expect an embeddable web-based OLAP browser (it’s time for Dundas Chart to come back to live) and an improved MDX query designer (no, I haven’t lost hope for this one).
- Enhanced Excel BI capabilities so Excel becomes the BI tool of choice. This includes supporting PowerPivot natively and overhauling the reporting capabilities beyond the venerable PivotTable and PivotChart. Ideally, what I am hoping for is decoupling Power View from SharePoint and integrating it with Excel and custom web applications. Power View is too cool to be confined onlyin SharePoint.
- Extending Microsoft Azure with BI capabilities to let solution providers host BI models in the cloud.
- Bringing BI to mobile devices.
On the personal side of things, I’ve been fortunate to stay healthy and busy (very busy). The Atlanta BI group, which I am leading, has grown in size and we now enjoy having 40-50 people attending our monthly meetings. For the past few months, I’ve been working on my next book, Applied Microsoft SQL Server 2012 Analysis Services (Tabular Modeling), which I expect to get published in March. And, my consulting business has been great!
I wish you a healthy and prosperous year! I hope to meet many of you in 2012. Meanwhile, you can find me online at the usual places: www.prologika.com | blog | linkedin | twitter.
Happy New Year!
 Well, rules have changed. As Jaime Tarquino from the SSRS team explained in his blog, “SQL Server 2012 Reporting Services SharePoint Integrated Mode”, there is no rsreportserver.config file anymore moving to Reporting Services 2012 in SharePoint integration mode (there are no configuration changes with native mode). Instead, the configurations sections are now saved in the SharePoint configuration database.
Well, rules have changed. As Jaime Tarquino from the SSRS team explained in his blog, “SQL Server 2012 Reporting Services SharePoint Integrated Mode”, there is no rsreportserver.config file anymore moving to Reporting Services 2012 in SharePoint integration mode (there are no configuration changes with native mode). Instead, the configurations sections are now saved in the SharePoint configuration database.