Programming MapReduce Jobs with HDInsight Server for Windows
In a previous blog “Installing HDInsight Server for Windows”, I introduced you to the Microsoft HDInsight Server for Windows. Recall that HDInsight Server for Windows is a Windows-based Hadoop distribution that offers two main benefits for Big Data customers:
- An officially supported Hadoop distribution on Windows server – Previously, you can set up Hadoop on Windows as an unsupported installation (via Cygwin) for development purposes. What this means for you is that you can now set up a Hadoop cluster on servers running Windows Server OS.
- Extends the reach of the Hadoop ecosystem to .NET developers by allowing them to write MapReduce jobs in .NET code, such as C#.
And, in previous blogs, I’ve introduced you to Hadoop. Recall that there are two main reasons for using Hadoop for storing and processing Big Data:
- Storage – You can store massive files in a distributed and fault-tolerant file system (HDFS) without worrying that hardware failure will result in a loss of data.
- Distributed processing – When you outgrows the limitations of a single server, you can distribute job processing across the nodes in a Hadoop cluster. This allows you to perform crude data analysis directly on files stored in HDFS or execute any other type of jobs that can benefit from a parallel execution.
This blog continues the HDInsight Server for Windows journey. As many of you probably don’t have experience in Unix or Java, I’ll show you how HDInsight makes it easy to write MapReduce jobs on a Windows machine.
Note Writing MapReduce jobs can be complex. If all you need is performing some crude data analysis, you should consider an abstraction layer, such as Hive, which is capable for deriving the schema and generating the MapReduce jobs for you. This doesn’t mean that experience in MapReduce is not useful. When processing the files go beyond just imposing a schema on the data and querying the results , you might need programming logic, such as in The New York Times Archive case.
As a prerequisite, I installed HDInsight on my Windows 8 laptop. Because of its prerelease status, the CTP of HDInsight Server for Windows currently supports a single node only which is fine for development and testing. My task is to analyze the same dataset that I used in the MS BI Guy Does Hadoop (Part 2 – Taking Hadoop for a Spin) blog. The dataset (temp.txt) contains temperature readings from weather stations around the world and it represents the weather datasets kept by National Climatic Data Center (NCDC). You will find the sample dataset in the source code attached to this blog. It has the following content (the most important parts are highlighted in red: the year found in offset 15 and temperature found in offset 88).
0067011990999991950051507004+68750+023550FM-12+038299999V0203301N00671220001CN9999999N9+00001+99999999999
0043011990999991950051512004+68750+023550FM-12+038299999V0203201N00671220001CN9999999N9+00221+99999999999
0043011990999991950051518004+68750+023550FM-12+038299999V0203201N00261220001CN9999999N9-00111+99999999999
0043012650999991949032412004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+01111+99999999999
0043012650999991949032418004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+00781+99999999999
Note that the data is stored in its raw format and no schema was imposed on the data. The schema will be derived at runtime by parsing the file content.
Installing Microsoft .NET SDK for Hadoop
The Microsoft .NET SDK for Hadoop facilitates the programming effort required to code MapReduce jobs in .NET. To install it:
- Install NuGet first. NuGet is a Visual Studio extension that makes it easy to add, remove, and update libraries and tools in Visual Studio projects that use the .NET Framework.
- Open Visual Studio (2010 or 2012) and create a new C# Class Library project.
- Go to Tools ð Library Package Manager ð Package Manager Console.
- In the Package Manager Console window that opens in the bottom of the screen, enter:
install-package Microsoft.Hadoop.MapReduce –preThis command will download the required Hadoop binaries and add them as references in your project.
Coding the Map Job
The Map job is responsible for parsing the input (the weather dataset), deriving the schema from it, and generating a key-value pair for the data that we’re interested in. In our case, the key will be the year and the value will be the temperature measure for that year. The Map class derives from the MapperBase class defined in Microsoft.Hadoop.MapReduce.dll.
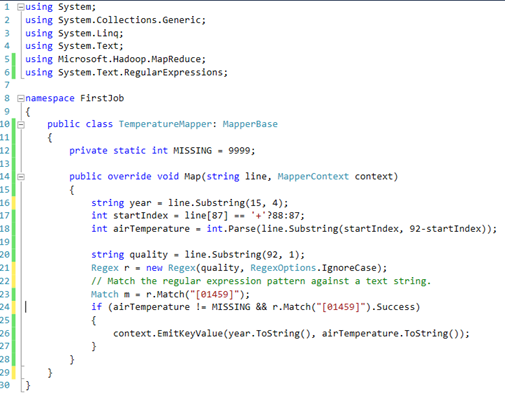
At runtime, HDInsight will parse the file content and invoke the Map method once for each line in the file. In our case, the Map job is simple. We parse the input and extract the temperature and year. If the parsing operation is successful, we return the key-value pair. The end result will look like this:
(1950, 0)
(1950, 22)
(1950, −11)
(1949, 111)
(1949, 78)
Coding the Reduce Job
Suppose that we want to get the maximum temperature for each year. Because each weather station might have multiple readings (lines in the input file) for the same year, we need to combine the results and find the maximum year. This is analogous to GROUP BY in SQL. The following Reduce job gets the work done:
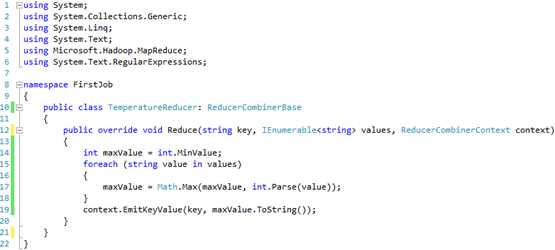
The Reduce job is even simpler. The Hadoop framework pre-processed the output of the Map jobs before it’s sent to the Reduce function. This processing sorts and groups the key-value pairs by key, so the input to the Reduce job will look like this:
(1949, [111, 78])
(1950, [0, 22, −11])
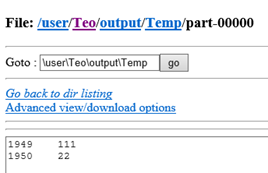
In our case, the only thing left for the Reduce job is to loop through the values for a given key (year) and return the maximum value, so the final output will be:
(1949, 111)
(1950, 22)
Testing MapReduce
Instead of deploying to Hadoop each time you make a change during the development and testing lifecycle, you can add another project, such as a Console Application, and use it as a test harness to test the MapReduce code. For your convenience, Microsoft provides a StreamingUnit class in Microsoft.Hadoop.MapReduce.dll. Here is what our test harness code looks like:
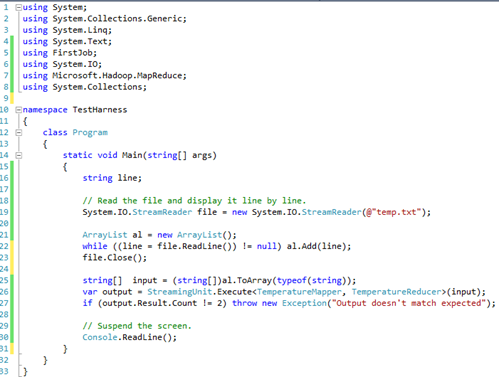
The code uses a test input file. It reads the content of the file one line at the time and adds each line as a new element to an instance of ArrayList. Then, the code calls the StreamInsight.Execute method to initiate the MapReduce job.
Deploying to Hadoop
Once the code is tested, it’s time to deploy the dataset and MapReduce jobs to Hadoop.
- Deploy the file to the Hadoop HDFS file system.
C:\Hadoop\hadoop-1.1.0-SNAPSHOT\bin>hadoop fs -copyFromLocal D:\MyApp\Hadoop\MapReduce\temp.txt input/Temp/input.txt
Note When you execute the hadoop command shell in the previous step, the file will be uploaded to your folder. However, if you use the JavaScript interactive console found in the HDInsight Dashboard, the file will be uploaded to the Hadoop folder in HDFS because the console runs under the hadoop user. Consequently, the MapReduce job won’t be able to find the file. So, you use the hadoop command prompt.
2. Browse the file system using the web interface (http://localhost:50070) to see that the file is in your folder.
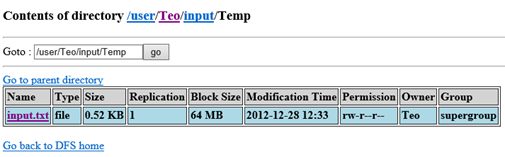
3. Finally, we need to execute the job with HadoopJobExecutor, which be called in various ways. The easiest way is to use MRRunner
D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug>.\mrlib\mrrunner -dll FirstJob.dll
D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug>.\mrlib\mrrunner -dll FirstJob.dll
File dependencies to include with job:[Auto-detected] D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\FirstJob.dll
[Auto-detected] D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\Microsoft.Hadoop.MapReduce.dll
[Auto-detected] D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\Newtonsoft.Json.dll
>>CMD: c:\hadoop\hadoop-1.1.0-SNAPSHOT\bin\hadoop.cmd jar c:\hadoop\hadoop-1.1.0-SNAPSHOT\lib\hadoop-streaming.jar -D “mapred.map.max.attempts=1” -D “mapred.reduce.max.attempts=1” -input inpu
emp -mapper ..\..\jars\Microsoft.Hadoop.MapDriver.exe -reducer ..\..\jars\Microsoft.Hadoop.ReduceDriver.exe -file D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\MRLib\Microsoft.Hadoop.MapDriver.e
p\MapReduce\FirstJob\bin\Debug\MRLib\Microsoft.Hadoop.ReduceDriver.exe -file D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\MRLib\Microsoft.Hadoop.CombineDriver.exe -file “D:\MyApp\Hadoop\MapRedu
irstJob.dll” -file “D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\Microsoft.Hadoop.MapReduce.dll” -file “D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\Newtonsoft.Json.dll” -cmdenv “MSFT_HADOOP_MA
-cmdenv “MSFT_HADOOP_MAPPER_TYPE=FirstJob.TemperatureMapper” -cmdenv “MSFT_HADOOP_REDUCER_DLL=FirstJob.dll” -cmdenv “MSFT_HADOOP_REDUCER_TYPE=FirstJob.TemperatureReducer”
packageJobJar: [D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\MRLib\Microsoft.Hadoop.MapDriver.exe, D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\MRLib\Microsoft.Hadoop.ReduceDriver.exe, D:\MyApp
Job\bin\Debug\MRLib\Microsoft.Hadoop.CombineDriver.exe, D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\FirstJob.dll, D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\Microsoft.Hadoop.MapReduce.dll, D
e\FirstJob\bin\Debug\Newtonsoft.Json.dll] [/C:/Hadoop/hadoop-1.1.0-SNAPSHOT/lib/hadoop-streaming.jar] C:\Users\Teo\AppData\Local\Temp\streamjob7017247708817804198.jar tmpDir=null
12/12/28 12:35:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
log4j:ERROR Failed to rename [C:\Hadoop\hadoop-1.1.0-SNAPSHOT\logs/hadoop.log] to [C:\Hadoop\hadoop-1.1.0-SNAPSHOT\logs/hadoop.log.2012-12-27].
12/12/28 12:35:20 WARN snappy.LoadSnappy: Snappy native library not loaded
12/12/28 12:35:20 INFO mapred.FileInputFormat: Total input paths to process : 1
12/12/28 12:35:20 INFO streaming.StreamJob: getLocalDirs(): [c:\hadoop\hdfs\mapred\local]
12/12/28 12:35:20 INFO streaming.StreamJob: Running job: job_201212271510_0010
12/12/28 12:35:20 INFO streaming.StreamJob: To kill this job, run:
12/12/28 12:35:20 INFO streaming.StreamJob: C:\Hadoop\hadoop-1.1.0-SNAPSHOT/bin/hadoop job -Dmapred.job.tracker=localhost:50300 -kill job_201212271510_0010
12/12/28 12:35:20 INFO streaming.StreamJob: Tracking URL: http://127.0.0.1:50030/jobdetails.jsp?jobid=job_201212271510_0010
12/12/28 12:35:21 INFO streaming.StreamJob: map 0% reduce 0%
12/12/28 12:35:38 INFO streaming.StreamJob: map 100% reduce 0%
12/12/28 12:35:50 INFO streaming.StreamJob: map 100% reduce 100%
12/12/28 12:35:56 INFO streaming.StreamJob: Job complete: job_201212271510_0010
12/12/28 12:35:56 INFO streaming.StreamJob: Output: output/Temp
4. Using the web interface or the JavaScript console, go to the output folder and view the part-00000 file to see the output (should match your testing results).