How do you start a data warehousing project? Not much different than any complex software project. You break it down to small iterations, e.g. by subject area, design and implement each iteration from beginning to end, and deploy to deliver incremental value. Agile? Perhaps. In my career I’ve seen software methodologies come and go so I’d abstain from applying a label. The main goal is to break complex tasks in smaller increments. You can call it agile if you want. But if I must meet every day for 15 minutes and hold hands (I had to do this a while back because my employer was agile, believe me), or deliver some crappy code in some predefined timeframes (sprints), then agile I am not.
So you stated your first iteration (typically Sales as revenue is an important metric to track). Now what? Next, we identify metrics, aka measures. Should you reverse engineer hundreds of reports that you’ve accumulated over decades to come up with these metrics? I’m too lazy to do this and frankly this very well might be a dead-end road. Instead, I suggest you go to the subject matter expert overseeing this iteration and ask him to a list of metrics (aka measures or facts) that he’d use to analyze his business subject area. He should be able to produce this in minutes. Then you ask him what perspectives he’d like to analyze these metrics and you now have dimensions. Then, you follow the dimensional modeling to come up with the design.
The important thing to remember is your iteration won’t be perfect. Nothing is. There will be gaps and misunderstandings, aka bugs. And that’s fine. That’s life. You keep on refining, extending and building… and you’re never done. Because business evolves and so does BI.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2017-09-27 19:31:252017-09-27 19:31:25How Do We Start?
MS BI fans, join me for the next Atlanta MS BI and Power BI Group meeting on September 25th at 6:30 PM. Carlos Rodriquez and Daniel Granadillo from Brightstar will share their experience with Power BI and QlikView. Accelebrate will sponsor the meeting. And your humble correspondent will show you two new cool Power BI features: drillthrough to page and explain increase/decrease.
Presentation:
Did Qlik run out of BI Power?
Level: Intermediate
Date:
September 25, 2017
Time
6:30 – 8:30 PM ET
Place:
South Terraces Building (Auditorium Room)
115 Perimeter Center Place
Atlanta, GA 30346
Overview:
Haters are gonna hate. Lovers are gonna love. What about you? Come decide by yourself whether you are a Qlik or a PBI guy/gal. This presentation is intended for anyone who wants to see these two BI tools in action. Carlos and Daniel will show the differences and similarities between QlikView and Power BI. They will perform side-by-side the following:
Extract and transform data
Create a data model (so to allow cross filtering)
Compare features side by side, including hiding/displaying visuals, creating linked objects, role-playing dimensions, what-if scenarios
Create a nice dashboard (which tool can actually do it?)
Speaker:
Carlos Rodrigues has more than 18 years’ experience as an IT professional and has successfully proven that he is especially adept at translating complex business needs into flawlessly Business Intelligence solutions. In his current role, Director- IT with Brightstar Device Protection, he holds the responsibility of defining the strategic roadmap and overseeing the implementation of the company’s Business Intelligence. He is a recent Georgia Tech MBA graduate (go Jackets 🐝). He enjoys traveling to different places around the world, appreciating the local culture, savoring local culinary styles and mainly, taking thousands of photos using his Nikon gear.
Daniel Granadillo is a Business Intelligence Architect / Developer with more than 10 years of experience around Data Warehouse and Analytics projects. Advocate of the Microsoft BI stack and discovered love at first sight with SSIS. You can find me enjoying the outdoors when not embraced with SQL Server
Sponsor:
Accelebrate is an IT training firm headquartered in Atlanta, Georgia, USA that provides on-site and online training on a wide variety of technologies for clients in North America, Europe, and worldwide. Accelebrate is a Prime Sponsor of the Atlanta Microsoft BI and Power BI Group.
Prototype with Pizza
“Power BI Page Drillthrough and Explain Increase/Decrease” by Teo Lachev
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2017-09-24 13:09:582017-09-24 13:09:58Atlanta MS BI Group Meeting on September 25th
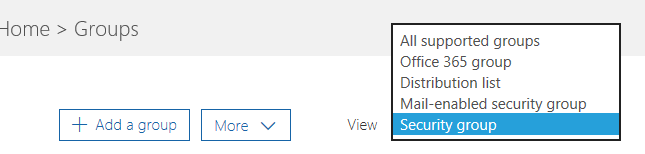
Power BI security is interwoven with Azure and O365 security. Sure, granting individual users access by entering emails works everywhere but it quickly becomes counterproductive with many users. For example, a large insurance company would like grant report access to 250 users and integrate this report with Dynamics 365. If you secure individually, this will require entering 250 emails three times: Dynamics 365, Power BI, and Row-level Security (RLS). As in the old days, we want to use groups to reduce the maintenance effort because all these users are added to a security group, we can just grant access to the group. And, when users come and leave, we make changes to one place only: the group and everything will work magically. However, nothing is simple and security is no exception. In fact, Office 365 has various group types, as you can see below.
To make things even more interesting, all groups are not created equal and currently Power BI supports has a varying degree of supporting them. Things will undoubtedly become more unified in time but for now the following table is meant to help you understand what’s supported and where.
Feature
O365 Group
O365 Distribution List
O365 Security Group
Exchange Dynamic Distribution List
App workspace
Yes
No
No
No
App distribution
No
Yes
Yes (with email)
No
Dashboard/report sharing
No
Yes
Yes (with email)
No
RLS
No
Yes
Yes
No
Let’s start with the features. “App workspace content” means adding group members to a shared app workspace. “App distribution” means publishing an app for a wider distribution, e.g. to the entire organization, as you can do previously with organizational content packs. “Dashboard sharing” means sharing a dashboard by email (the first sharing option in Power BI before workspaces and content packs were introduced). RLS means row-level security, i.e. adding groups as members of an RLS role so that they gain different access to data. Moving to group types, “O365 Group” is the group you’d get when you create a workspace. This type of group is supported by many O365 applications, such as Yammer, SharePoint, Teams, etc. “O365 distribution list” is meant for sending email to multiple users in Outlook Web Access. “O365 Security Group” is Azure Active Directory group (if you sync your on-premises AD to Azure, you’d get O365 security groups too). “Exchange Dynamic Distribution List” allows you to create condition-like groups, e.g. for sending email to everyone.
Are you still with me? One more twist. Due to a bug, app distribution and dashboard sharing requires the O365 security group to have an email assigned. A few more notes:
Creation of content: App workspaces in Power BI are meant for authors to collaborate and create content. You need a Power BI Pro license for accessing these workspaces and you cannot yet add AD security groups as members/admins to app workspaces
Distribution of content: Once content is created in an app workspace, you can distribute it in two ways:
Share out individual dashboards and reports. If the original app workspace is in premium, recipients just need a free license. If not, they need Pro licenses. Also, you can share dashboards to security groups but not O365 groups.
Publish out an app from the workspace. If the original app workspace is in Premium capacity, recipients just need a free license. If not, they need Pro licenses. Also, you can publish an app to AAD security groups but not O365 groups.
TIP: If you have Power BI Premium, you can share a dashboard or report from a Premium workspace to other users. You don’t have to publish an app. This is explained in more details here.
Clear as mud? As I said, I hope that table would become obsolete in a few months when Power BI would support all group types everywhere.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2017-09-20 18:49:492018-05-21 14:07:51Power BI Group Security
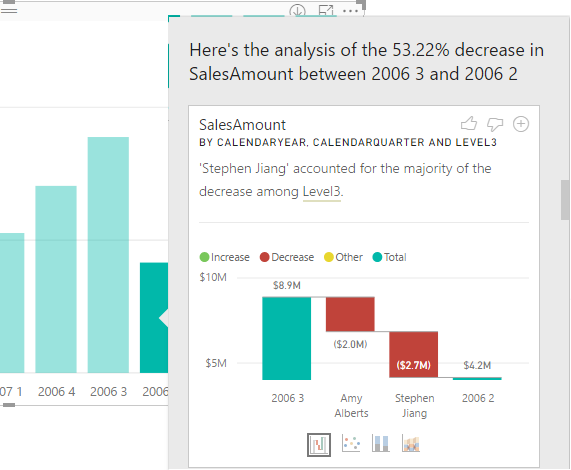
The September release of Power BI Desktop brings Quick Insights in the form of the very nice Explain Increase/Decrease feature (in preview). Suppose you have a column chart and you see a sudden increase or decrease in the chart series. You can now right-click on the bar and then click Analyze, Explain the Decrease menu. This runs the Quick Insights machine learning algorithms to predict what caused the anomaly. As in Power BI Service, Quick Insights produces several reports.
In this case, one of the Quick Insights visuals informs me that most of the decrease is contributed to the bad performance of one of the sales reps (Stephen Jiang). I could have sliced and diced all day long but I could have found this myself. If I find a particular Quick Insight visual useful, I can add it to the report. From that point, I can use just like any other visual on the report.
The Power BI Desktop Explain Increase/Decrease helps you performing root cause analysis in a blink of an eye.
Currently in the preview, the feature is rough around the edges. For example, I was able to get it to work only if I add a field from a Date table, such as Calendar Year, to the chart. Other limitations include:
You can’t use it if your visual includes:
TopN filters
Include/exclude filters
Measure filters
Non-additive measures and aggregates
Show value as
Filtered measures (it’s the new thing we use for scatter chart in insights)
Categorical columns on X-axis unless it defines a sort by column that is scalar. If using a hierarchy, then every column in the active hierarchy has to match this condition
Non-numeric measures: Model measure support is limited to sum and count only right now.
The September release of Power BI Desktop adds two very useful features: drilling through another page and explain increase/decrease. SSRS practitioners might find “page drillthrough” similar to SSRS actions. However, instead of navigating to another report, it allows the user to navigate to another page within the same report (at least for now cross-report drillthrough is not supported). Although not as flexible as SSRS actions, PBI page drillthrough expands the Power BI data exploration capabilities. Previously, you had the following drillthrough options:
Dashboard drillthrough – Clicking on a dashboard tile navigates you to the underlying report assuming the tile was produced by pinning a report visual.
See records – This chart-level features allows you to right click a bar and see the data behind it.
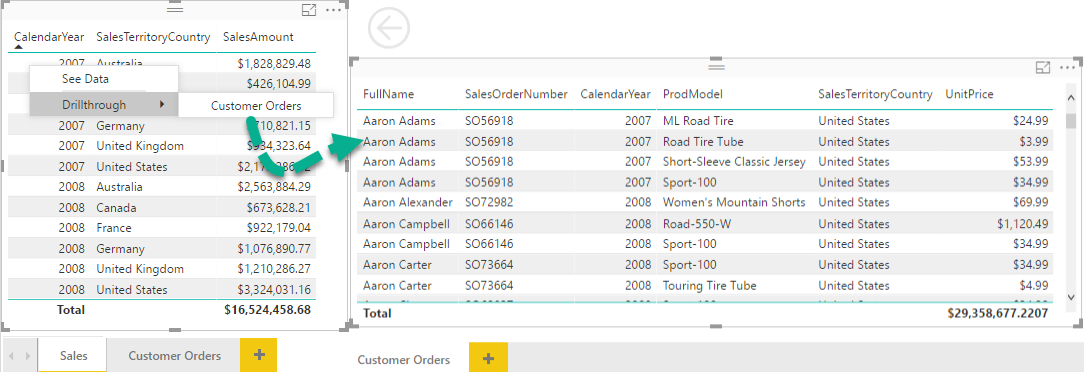
I won’t repeat the Microsoft intro (watch it here) but I’ll add a few more notes that the demo doesn’t cover and I find very useful. Consider this report which has two pages: Sales page that shows a sales summary and Customer Orders page that is defined as a drillthrough page. The idea here is to allow the user to drill from the sales summary to the Customers Orders to see the data in more detail.
To “define” the Customer Orders page as a drillthrough target, I had to only add CalendarYear and SalesTerritoryCountry fields to the new Drillthrough Filters area in the Visualizations pane. This is conceptually similar to defining parameters in an SSRS drillthrough report. Interestingly, the summary page automatically detects if the visual has one of the fields used in the Drillthrough Filters area. If it does, it automatically enables the Drillthrough context menu. The context menu is activated even if the summary page has just one of the fields defined as drillthrough filters. For example, if the Sales visual has only Calendar Year, the drillthrough page would show all customer orders for that year. If it has also SalesTerritoryCountry, the drillthrough page would show orders for that year and for that country. If the Sales visual has none of the fields used for drillthrough filters, then Drillthrough won’t show up. In other words, Power BI automatically matches the source fields and drillthrough filters and this saves you a lot of configuration steps, such as to configure parameters, to check which field exist and to pass All to the parameters that don’t exist!
Page BI page drillthrough was one of the most requested features by the community. I’d love to see it extended with the following options in future:
Expression-based filters – This applies not only to drillthrough filters but the other filter types. For example, it will be great to default the filter to value using an expression, e.g. =IF(SELECTEDVALUE()==”, <some value>).
Ability to drill to pages in other reports.
Multiple context-aware drillthrough actions – For example, SSRS allows you define an action for each report element. Currently, PBI page drillthrough takes the entire row context and you can’t define drillthrough targets for specific fields.
In the “Processing Tabular from Exotic Clients” blog, I said that if you Azure AS model retrieves data from an Azure database, such as Azure SQL Database, it should also be located in the same Azure data center for faster processing and to avoid data transfer fees between data centers. Let’s elaborate a bit on this and share some performance results from a real-life project.
We deployed two Azure AS instances to North Central and South Central Azure data centers, while the Azure SQL Database was deployed to the South Central data center. Here the stats for processing loading about 35 million rows in Tabular using the Full Process of the AS database. The Azure SQL Database was at P1 performance level and Azure AS was at S1 performance level.
South Central: 12 minutes or about 50,000 rows/sec
North Central: 19 minutes or about 30,000 rows/sec
As you can see, hosting Azure AS in a different center incurs not only data transfer fees but also increased processing times (more than 50% overhead). Your results will probably vary but just like with on-premises installations, it’s very important to fine tune your queries or SQL views. SSAS is capable of processing more than 100,000 rows/sec on a single thread. However, it can do this if rows from the data source arrive at that speed. If you use custom queries or SQL views, any join or inefficient code can potentially slow down processing times significantly. For example, I typically use SQL views to wrap fact tables to perform ad hoc calculations. Initially, for this project I used the T-SQL AT TIME ZONE clause to perform some time zone calculations in the view. As it turned out, AT TIME ZONE is very slow because it looks in the registry for information about when daylight savings time starts and ends, and needs to work out whether each individual value you’re converting is within that period or not. As a result, processing the model took 6 hours! Once I switched to using SWITCHOFFSET, it went down to 12 minutes.
To quickly test the database throughput, open SSMS (ideally in a VM in the same data region to ignore connection latency) and execute a query that selects a few million rows from a table (make sure to change the Discard Query Results option in the query properties to False to avoid SSMS running out of memory when loading all these rows from the grid and to ignore the time to visualize the data). Then divide the query execution time by the number of rows. This gives you the data retrieval throughput and that will determine how fast SSAS can read the source data.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2017-09-11 12:38:202017-09-11 12:38:20Deploying and Processing Azure AS
As I’m writing this newsletter, Florida and Georgia (I live in Atlanta, GA) are in the midst of planning for hurricane Irma, which is expected to be one of the most powerful Atlantic Ocean hurricanes in recorded history. I hope that this won’t be the case and we don’t have to deal with a disaster of the magnitude of hurricane Harvey that took place just two weeks ago in Houston, TX. To avoid and mitigate this, a great deal of planning happens at every level: from government to citizens. Did you know that over 5 million of people in Florida were evacuated, making this the biggest US displacement of people to date? Speaking of planning, how does your company approach Business Performance Management? Do you use Excel spreadsheets or expensive high-end planning software? Next, I’ll share how Prologika helped a large organization improve its budgeting and planning process, powered by a cost-effective solution based on Microsoft BI.
Why Business Performance Management?
Wikipedia defines Business Performance Management (BPM) as “a set of performance management and analytic processes that enables the management of an organization’s performance to achieve one or more pre-selected goals”. A simpler BPM definition might be a methodology to help the company predict its performance. An integral part of a BPM strategy is a process for Budgeting, Planning, and Forecasting that typically has the following workflow:
Every planning year, a planner in the Financial department creates a budget for a certain number of future periods. The budget is revised and multiple versions are proposed to management. Once budget is approved, it becomes fixed for the duration of the planning year.
As actuals come in, the planner works on forecast scenarios. Multiple forecast scenarios are typically prepared as the planning year progresses over time.
The planner monitors the variance between actuals and budget, actuals and forecast versions, and between forecast versions to improve the planning accuracy.
Business Needs
When it comes to Finance, nothing is simple and BPM is no exception. In fact, it very well might be that that your BPM solution might be the most complicated software you’ve ever developed. The temptation is to buy a prepackaged software but even that route would require a lot of customization and compromises. To gauge complexity, let’s look at some of the business requirements we faced.
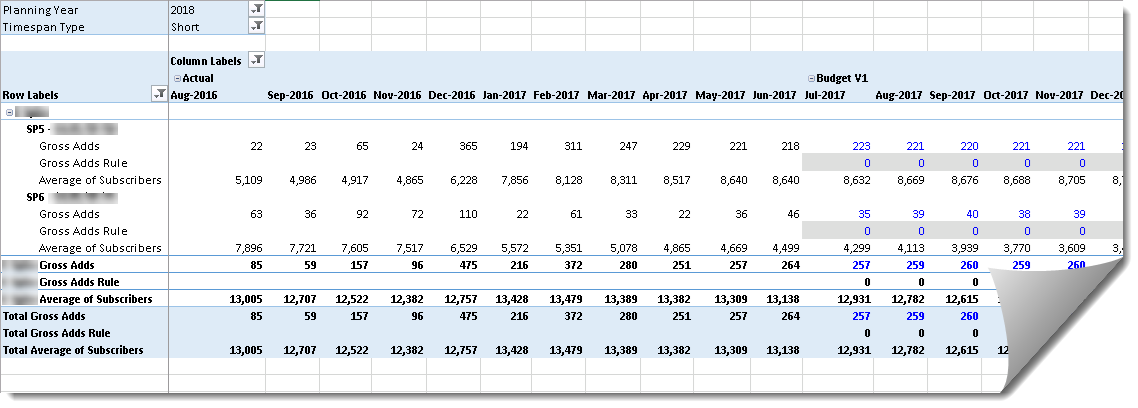
Similar to a Telco, this company has customers and service plans. As a B2B organization, their customers are other companies. Planning is done at the customer and service plan level, and across multiple subject areas. For example, the Excel report shows a subset of the measures for planning growth of the customer base. The planner can change the budget and forecast values of some measures, called drivers. For example, the planner can overwrite Gross Adds for future periods. Further, the planner can overwrite a rule in each cell to change how the driver cell value is computed. The rules are:
0 (default rule) – By default, planned values are calculated as 3-mo average of previous periods. For example, Gross Adds for Aug 2017 for the first plan is 221 and has a Gross Adds Rule of 0. This means that the system will calculate the value as a 3-mo simple average of the values of the previous three months (221, 218, and 223). Note that a previous month might fall in the Actuals range. Also notice that recursive calculations are required, where the value of each month is based on the same measure for previous periods.
1 (6-mo average) – Instead of 3-mo average, 6-mo average is used.
2 (seasonality index) – The value is computed by multiplying the driver values for the past 12 months by a seasonality index.
Any other value – The planner enters the driver value manually.
The driver measures are used to calculate other (output) measures. For example, Average of Subscribers has a formula that is based on Gross Adds and other measures. Finally, the drivers and output measures are allocated across a Chart of Accounts dimension (not shown on the report) to give managers the financial perspective of how the company is doing.
The Solution
Previously, the company has used an Excel-based home-grown solution. However, the process was manual, lengthy, error-prone, and it couldn’t give management a quick and accurate picture of the company’s performance. A Business Analytics group was responsible for retrieving and consolidating actuals. Then, the Finance group would manually input actuals into an Excel template. Complicated Excel formulas were used to calculate drivers and output measures but even Excel had difficulty with more complex recursive measures. Most of the time and effort was spent on working the system than on business performance management. The company looked at other high-end financial solutions, with a starting price tag of $300K, plus yearly maintenance fees and consulting feeds. At the end, the company entrusted Prologika to implement the solution.
We used Analysis Services 2016 Multidimension, Initially, we considered Tabular but we realized that the solution complexity exceeded the Tabular capabilities, including:
No support for writeback – Currently, Tabular doesn’t writeback although third-party solution such as Power Planner can be overcome this limitation.
No support for recursive measures – Currently, Tabular doesn’t support recursive measures, where the measure DAX formula references the same measure.
No scope assignments – Tabular doesn’t support scope assignments for allocations.
No parent-child dimensions and hierarchy functions – Tabular doesn’t support parent-child hierarchies and functions for navigating the hierarchy, such as Parent, Children, etc.
This is a classic example of using the best tool for the job. While Tabular could be a good fit for perhaps 80% of semantic models out there, Multidimensional is probably your best bet for Financial projects and projects that require massive data volumes. No tool is perfect. “When all you have (know) is a hammer, everything looks like a nail” doesn’t work for BI.
MS BI Events in Atlanta
Atlanta MS BI and Power BI Group: “Did Qlik run out of BI power?”presentation by Carlos Rodriquez on 9/25
Atlanta MS BI and Power BI Group: “Topic: TBD” presentation by Slalom Consulting on 10/30
As you’d probably agree, the BI landscape is fast-moving and it might be overwhelming. If you need any help with planning and implementing your next-generation BI solution, don’t hesitate to contact me. As a Microsoft Gold Partner and premier BI firm, you can trust us to help you plan and implement your data analytics projects, and rest assured that you’ll get the best service. Regards,
Teo Lachev
Teo Lachev President and Owner Prologika, LLC | Making Sense of Data Microsoft Partner | Gold Data Analytics
Mark your calendar for the next meeting of our Atlanta MS and Power BI Group on September 25th when we will compare Power BI and Qlik.
Presentation:
Did Qlik run out of BI Power?
Level: Intermediate
Date:
September 25, 2017
Time
6:30 – 8:30 PM ET
Place:
South Terraces Building (Auditorium Room)
115 Perimeter Center Place
Atlanta, GA 30346
Overview:
Haters are gonna hate. Lovers are gonna love. What about you? Come decide by yourself whether you are a Qlik or a PBI guy/gal. This presentation is intended for anyone who wants to see these two BI tools in action. Carlos and Daniel will show the differences and similarities between QlikView and Power BI. They will perform side-by-side the following:
Extract and transform data
Create a data model (so to allow cross filtering)
Compare features side by side, including hiding/displaying visuals, creating linked objects, role-playing dimensions, what-if scenarios
Create a nice dashboard (which tool can actually do it?)
Speaker:
Carlos Rodrigues has more than 18 years’ experience as an IT professional and has successfully proven that he is especially adept at translating complex business needs into flawlessly Business Intelligence solutions. In his current role, Director- IT with Brightstar Device Protection, he holds the responsibility of defining the strategic roadmap and overseeing the implementation of the company’s Business Intelligence. He is a recent Georgia Tech MBA graduate (go Jackets 🐝). He enjoys traveling to different places around the world, appreciating the local culture, savoring local culinary styles and mainly, taking thousands of photos using his Nikon gear.
Daniel Granadillo is a Business Intelligence Architect / Developer with more than 10 years of experience around Data Warehouse and Analytics projects. Advocate of the Microsoft BI stack and discovered love at first sight with SSIS. You can find me enjoying the outdoors when not embraced with SQL Server
Sponsor:
Accelebrate is an IT training firm headquartered in Atlanta, Georgia, USA that provides on-site and online training on a wide variety of technologies for clients in North America, Europe, and worldwide. Accelebrate is a Prime Sponsor of the Atlanta Microsoft BI and Power BI Group.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2017-09-07 15:01:122021-02-17 01:01:06Power BI vs Qlik Presentation
Processing Tabular models from SSMS or .NET client apps is pretty straightforward. For example, you can connect with SSMS and issue processing commands through the UI or via TMSL. You can also use custom apps with Tabular Object Model (TOM) and you can send XMLA commands directly if you have an app perhaps that’s already doing that.
For Azure AS, it’s generally a good idea to run the app sending the processing command in the same data center where the Azure AS server is. If your Tabular database gets data from an Azure database, such as Azure SQL Database, the database should also be located in the same data center for better processing throughput and to avoid data transfer fees between data centers.
But what if you want to issue a processing command from more exotic clients, such as Python? Or, incrementally process from SSIS? Start with creating a JSON processing script (assuming Analysis Services 2016 or higher, or Azure AS). For the following script, processes two tables and the latest partition of the third table with the Data Only option (loads only the data). All objects are processed in parallel and 10 is specified as a maximum degree of parallelism. Then, it processes the database with Calculate option to restore calculated columns, relationships, and hierarchies.
Next, assuming you’re processing Azure AS, use one of the Microsoft-provided libraries to authenticate against Azure AD. For example, use the Python library to authenticate and submit the JSON in a standard XMLA message.


 As I’m writing this newsletter, Florida and Georgia (I live in Atlanta, GA) are in the midst of planning for hurricane Irma, which is expected to be one of the
As I’m writing this newsletter, Florida and Georgia (I live in Atlanta, GA) are in the midst of planning for hurricane Irma, which is expected to be one of the