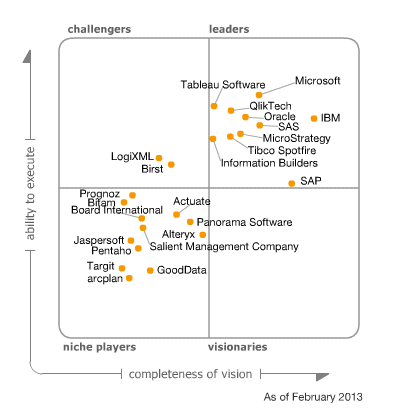
MVP fellow, Andrew Burst, discusses Gartner’s newly released DW (not BI, mind you) magic quadrant. It looks like Gartner fell in love with Teradata but Microsoft is moving up as well thanks to the advances in its Parallel Data Warehouse (PDW) and in-memory offerings.
Performance tuning – my favorite! This blog originated from a quest to reduce the processing time of an SSAS cube which loads some 2.5 billion rows and includes DISCINTCT COUNT measure groups. The initial time to fully process the cube was about 50 minutes on a dedicated DELL PowerEdge R810 server, with 256 GB RAM and two physical processors (32 cores total). Both the SSAS and database servers were underutilizing the CPU resources with SSAS about 60-70 utilizations and the database server about 20-30 CPU utilization. What was the bottleneck?
By using the sys.dm_os_waiting_tasks DMV like the statement below (you can use also the SQL Server Activity Monitor), we saw a high number of CXPACKET wait types.
SELECT dm_ws.wait_duration_ms,
dm_ws.wait_type,
dm_es.status,
dm_t.TEXT,
dm_qp.query_plan,
dm_ws.session_ID,
dm_es.cpu_time,
dm_es.memory_usage,
dm_es.logical_reads,
dm_es.total_elapsed_time,
dm_es.program_name,
DB_NAME(dm_r.database_id) DatabaseName,
— Optional columns
dm_ws.blocking_session_id,
dm_r.wait_resource,
dm_es.login_name,
dm_r.command,
dm_r.last_wait_type
FROM sys.dm_os_waiting_tasks dm_ws
INNER JOIN sys.dm_exec_requests dm_r ON dm_ws.session_id = dm_r.session_id
INNER JOIN sys.dm_exec_sessions dm_es ON dm_es.session_id = dm_r.session_id
The typical advice given to address CXPACKET waits is to decrease the SQL parallelism by using the MAXDOP setting. This might help in some isolated scenarios, such as UPDATE or DELETE queries. However, the SQL Sentry Plan Explorer showed that each processing query is highly parallelized to utilize all cores. Notice in the screenshot below, that thread 16 fetches only 14,803 rows.
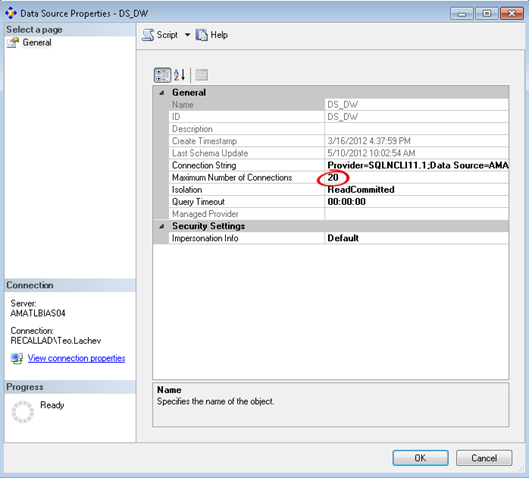
Therefore, the CXPACKET waits were simply caused by faster threads waiting for other threads to finish. In other words, CXPACKET wait is just a coordination mechanism between the threads being parallelized. To confirm this, we set the SQL Server MAXDOP setting to 1. Surely, the CXPACKET waits disappeared but the overall cube processing time went up as well. In our case, the biggest benefit was realized not by decreasing the SQL Server parallelism but by increasing it, by increasing the maximum number of database connections. This resulted in decreasing the overall processing time some 20%.
You need to be careful here though. While increasing the connections to max out the CPU on the SSAS server will yield the biggest gain, it might also slow down other processing, such as reports that query the cube while the database is being processed. So, as a rule of thumb, target no more than 80% CPU utilization to leave room for other tasks.
SQL Server 2012 introduces columnstore indexes. Using the same in-memory VertiPaq engine that powers PowerPivot and Analysis Services Tabular, columnstore indexes can speed up dramatically SQL queries that aggregate large datasets. For a great introduction to columnstore indexes, see the video presentation, “Columnstore Indexes Unveiled” by Eric Hanson. I personally don’t see columnstore indexes as a replacement of Analysis Services because an analytical layer has much more to offer than just better performance. However, in a recent project we’ve found a great use of columnstore indexes to speed up ETL processes.
Issue: Perform an initial load of a snapshot fact table for inventory analysis from another fact table with one billion rows. For each day, extract some 200 million rows from the source fact table and group these rows into a resulting set of about 300,000 rows to load the snapshot fact table for that day. The initial estimates indicated that that the extraction query alone takes about 15 minutes when using a clustered index. And, that’s just for one day. Given this speed, we estimated the initial load could take weeks.
Solution: We upgraded to SQL Server 2012 and created a columnstore index on selected columns from the source fact table. We excluded high-cardinality columns that were not used by the extraction query to reduce the size of the index. Creating the index on the source table (1 billion rows) took about 10 minutes and this is very impressive. The disk footprint of the index was about 4GB. We ran the same extraction query and saw a five-fold performance improvement. This query, which would previously run for 15 minutes with a B-tree clustered index, would now finish in 3 minutes with a columnstore index.
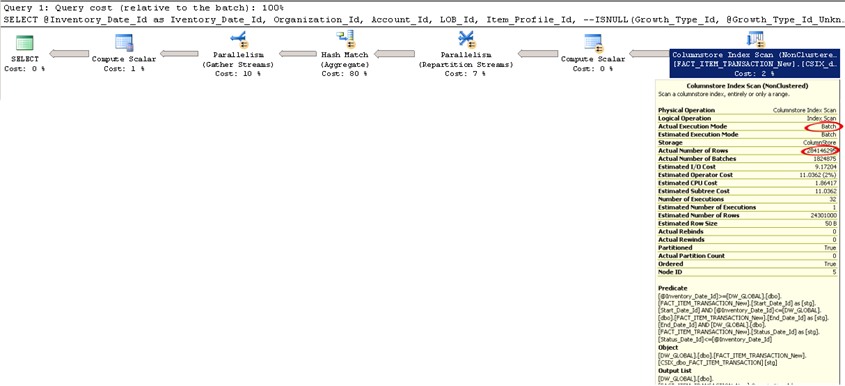
When testing your queries with columnstore indexes, it is important to make sure that the query executes in Batch mode. As you can see in the screenshot below, the query uses the columnstore index and the execution mode is Batch. If it says Row, the query performance degrades significantly. Watch Eric Hanson’s presentation to understand why this happens and possible workarounds.
When I did initial tests to test the columnstore index, I ran into a gotcha. I tested a simple “SELECT SUM(X) FROM TABLE” query to find that it executes in a Row mode and the query took about 2 minutes to finish. As usual, the first thing I try doesn’t work. As it turned out, currently a columnstore index doesn’t support batch mode with scalar aggregates. You need to rewrite the query with a GROUP BY as Eric Hanson explains this in more details in his blog, “Perform Scalar Aggregates and Still get the Benefit of Batch Processing”. This is rather unfortunate because every ad-hoc report starts with the end user dropping a measure and the report tool generating such queries.
When testing the performance gain, it’s useful to compare how the same query would perform without a columnstore index. Instead of having two tables or dropping the index, you could simply tell SQL Server to ignore the columnstore index, such as:
SELECT … FROM…WHERE…GROUP BY…
OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX)
To sum up, when you are pushing the envelope of traditional B-tree indexes and queries aggregate data, consider SQL Server 2012 columnstore indexes. The query optimizer would automatically favor a columnstore index when it makes sense to use it. Columnstore indexes require a read-only table but the cost of dropping and recreating them is not that high. Or, you could add them to speed up the initial DW load and drop them once the load completes.
Disabling check constraints, such as foreign key constraints, is often required when populating a data warehouse. For example, you might want to disable a check constraint to speed up loading of a fact table.
How do we disable check constraints in SQL Server? You can script each check constraint or you can use the undocumented sp_MSforeachtable function.
ALTER TABLE [dbo].[FACT_ITEM_INVENTORY] NOCHECK CONSTRAINT [FK_DIM_DATE_FACT_ITEM_INVENTORY_Date_Id] — disables a specific contraint
sp_MSforeachtable ‘ALTER TABLE ? NOCHECK CONSTRAINT ALL’ — disables all contraints in the database
Once the foreign keys are disabled, you can run the ETL job or delete records from the referenced table without referential integrity checks. Note that you cannot truncate a table even if you have disabled the constraints due to the different way SQL Server logs the truncate operation. You must drop the constraints if you want to truncate a table. You can use sp_MSforeachtable to drop constraints as well although I personally prefer to disable them for a reason that will become obvious in a moment.
How do we enable check constraints?
The same way you disabled them but this time you use the CHECK predicate:
ALTER TABLE [dbo].[FACT_ITEM_INVENTORY] CHECK CONSTRAINT [FK_DIM_DATE_FACT_ITEM_INVENTORY_Date_Id] — enables a specific constraint
sp_MSforeachtable ‘ALTER TABLE ? CHECK CONSTRAINT ALL’ — enables all contraints in the database
Does SQL Server verify referential integrity for existing data when you re-enable check constraints?
This is where the behavior differs between recreating and enabling constraints. If you drop and create the constraints, the server will check the data unless WITH NOCHECK is used.
ALTER TABLE [dbo].[FACT_ITEM_INVENTORY] WITH NOCHECK ADD CONSTRAINT [FK_DIM_DATE_FACT_ITEM_INVENTORY_Date_Id] FOREIGN KEY([Date_Id]) REFERENCES [dbo].[DIM_DATE] ([Date_Id])
The server doesn’t check existing data if you enable a previously disabled constraint. You can manually check foreign key violations by using this command:
dbcc checkconstraints(FACT_ITEM_INVENTORY) –- checks a specific table
dbcc checkconstraints — checks the entire database
The checkconstraints command will output all rows that violate constraints.
UPDATE 10/31/2011
Reader Ian pointed out that re-enabling foreign key constraints without checking data marks them as non-trusted. Consequently, the SQL Server optimizer may choose different execution plans for a certain range of queries. Tibor Karaszi explains this in more details in his blog Non-trusted constraints and performance. Paul White also mentions about a bug in this area. This makes me believe that enabling check constraints without checking data should be avoided. Therefore, to speed up fact table imports for large dataset consider:
Disable foreign key constraints
Drop indexes on fact tables
Import data
Recreate indexes on fact tables
Re-enable constraints with the WITH CHECK option
sp_MSforeachtable ‘ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL’ — enables all constraints in the database