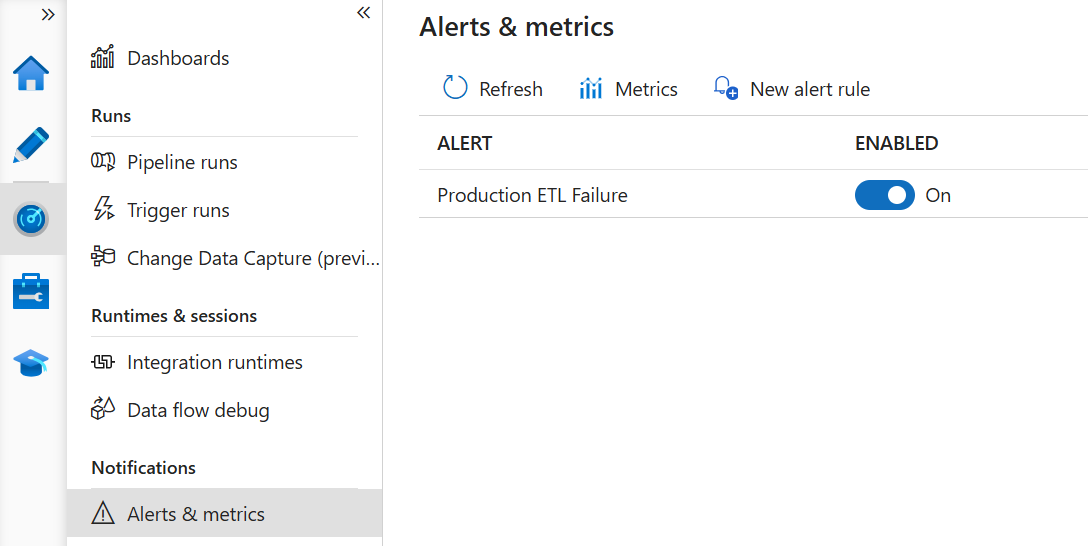
Alerting is an important monitoring task for any ETL process. Azure Data Factory can integrate with a generic Azure event framework (Azure Monitor) which makes it somewhat unintuitive for ETL monitoring. You can set up and change the alerts using the ADF Monitoring hub.
You might find the following tips useful for setting up an ADF alert:
Dimension – I like to nest pipelines where a master pipeline starts dimension and fact master pipelines, which in turn execute unit pipelines, such as a loading a dimension table. This allows me to restart ETL at any level. In the Dimension dropdown (nothing to do with DW dimensions), I select all such master pipelines because if an error is triggered downstream, it will bubble up to the master.
Failure Type – I select all failure types.
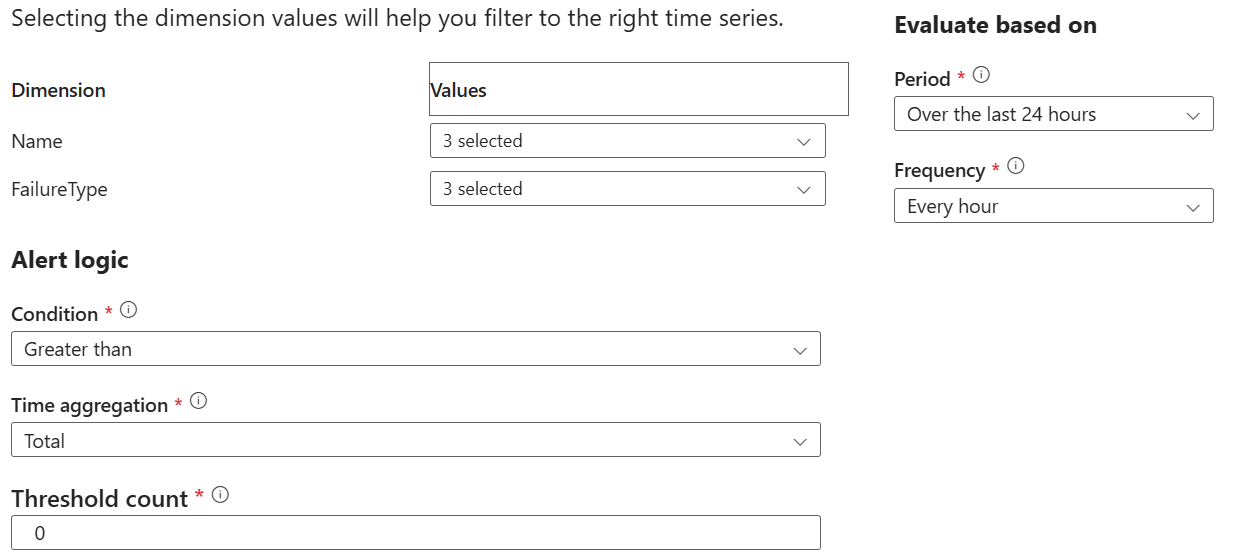
Condition – I configure the alert to be generated as soon as one failure occurs.
Period – This is a tricky one. It specifies over what period the threshold failure count will be evaluated. Let’s say you schedule the ETL process nightly at 12 AM. If you specify a value lower than 24 hours, let’s say 6 hours, Azure Monitor will check for failures every 6 hours. If ETL fails at say 12:15 AM, you will get the alert the next time Azure Monitor runs as you should. But then, after it checks in another 6 hours and finds no failure, it will send a notification that the failure is resolved, while probably it’s not. Therefore, I set the period to 24 hours. Obviously, this will be an issue if ETL runs weekly but 24 hours is the longest period supported.
Frequency – I set this to the longest frequency of 1 hour as it doesn’t make sense to check frequently for failures if the process runs once in a day. With this setup, the threshold count will be evaluated every hour for each 24-hour cycle.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-04-15 17:32:062024-04-15 17:36:46Tips for Configuring Azure Data Factory Alerts
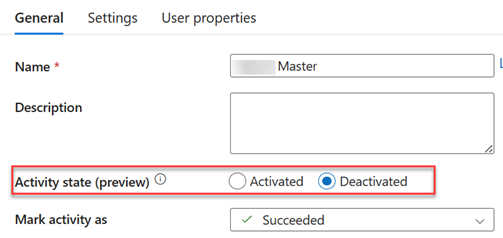
Lo and behold, Azure Data Factory now supports deactivating activities as a preview feature. It took only seven years…
You can deactivate/activate activity by right-clicking it in the canvas or from its General settings. You can also configure how the subsequent activities should treat a deactivated activity, with Succeeded being the most common outcome.
Someone asked the other day for my opinion about the open-source dbt tool for ETL. I hadn’t heard about it. Next thing I’ve noticed was that Fabric Warehouse added support for it, so I got inspired to take a first look. Seems like an ELT-oriented tool. Good, I’m a big fan of the ELT pattern whose virtues I extolled many times here. But a Python-based tool that requires writing templates in a dev environment, such as Visual Studio Code? Yuck!
So, what’s my first impression? Same thoughts as when I see developers use another generic programming language, such as C#, for ETL. You can do it but why?
For years, I’ve been trying to get developers out of custom coding for ETL to low-code ETL specialized tools, such as SSIS and ADF.
Just because you studied Python in college, should you use Python for everything? I guess the open-source custom code gravitational pull is too strong. Or there are plenty of masochists out there. One of their case studies hailed dbt for democratizing ETL because everyone knows SQL and can contribute. That’s true but what goes around SQL is also important, as well productivity and maintainability of the overall solution.
On the Azure platform my preferred ETL architecture remains ADF and ELT with SQL in stored procedures. I don’t see any dbt advantages. Dbt might make sense to you if want to stay vendor-neutral, but I’d argue that if you follow the ELT pattern, migrating your ETL processes to another vendor would be trivial.
What am I missing?
UPDATE 10/19/2023
I’m humbled by the interest and comments this blog inspired on LinkedIn. It might well become one of the most popular posts I’ve ever written! This is what I’ve established based on the feedback from people who have used dbt:
Although designed for ELT, it does only the “T” (transformation) part of the ELT process. You’d still need other tools, such as ADF, to extract and load the data. And so in a typical DW project, you could use ADF to extract data from the data sources, stage it, and then execute your dbt process to load the DW tables.
It’s a template-based tool, where you use Python-like syntax to define “models”, such a model corresponding to a fact table, and the SQL statement to load it. Therefore, the SQL statement is embedded inside the template.
It supports features, such as tests, macros, lineage, and documentation.
I wonder how many ETL projects would need these features though. If yours does, then dbt might be of interest. For me, the tool is still a hard pass that shares the same dark corner as ETL automation tools and ETL with custom code. Everybody is trying to do more with less nowadays, so maintainability and productivity are more important. If you have resources and time, my recommendation would be to invest into a home-grown SQL generator that would auto-generate the “T” part, such as the MERGE statement.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-10-16 14:19:452024-03-13 16:11:37When All You Have is a Hammer… (Dbt Tool for ETL)
I ranted many times about SaaS vendors preventing direct access to data in its native storage, which is typically a relational database. It’s sort of like going to a bank, handing them over your money, and they telling you that you can only get your money back in cash, in Bitcoin, in ₿100 bills but no more than ₿1,000 per withdrawal, or whatever madness suits the bank best. I wonder how long this bank will be in business. Yet, many companies just hand over the keys of the data kingdom to a SaaS vendor and they wonder how to get their “precious” back so they can build EDW and enable modern analytics. Since when direct access became an anathema perpetuated by mega software vendors, including Microsoft? I’ll repeat again that there are no engineering reasons to prevent direct access to your data, even if you must pay more to “isolate” you from other customers for security, performance, liability, or other “tradeoffs” for you choosing the SaaS path.
However, there are rays of sunshine here and there. In a recent integration project, I had to extract data from the InTempo ERP cloud software. Besides other integration options, InTempo supports ODBC access to their IBM Db2 database over VPN connectivity. Not only did InTempo give us direct access to the ERP data, but they also provided support services to help with the SQL queries. I couldn’t believe my luck. Finally, an enlightened vendor! On the downside, we had to send freeform SELECT statements down the wire from ADF while I personally would have preferred an option to package them in SQL views residing at the database, but I’d be pushing my luck.
Direct access to your data should be on top of your SaaS vendor selection criteria. TIP: if you hear “API” in any flavor (REST, ODATA, SOAP, etc.), run for the exit. I have nothing but horrible experience taking that path, even with Microsoft Dynamics APIs. “Data lake” is a tad better but still your best option is direct access to data in its native storage to avoid excessive integration effort and reduce data latency.
An enterprise client wants to migrate many Alteryx workflows created over years by smart business users to the Microsoft ecosystem. During the initial intake, we discussed Power BI dataflows vs Azure Data Factory mapping data flows. Yep, Microsoft loves to confuse us, but these technologies have nothing to do with each other.
Azure Data Lake Storage (CSV files in CDM folders)
Many sinks
Debugging
N/A
Debug mode
Monitoring
Very basic (refresh failures)
Detail output
In a nutshell, Power BI dataflows are meant for self-service ETL, where the business users would be responsible for creating and managing the ETL flows. By contrast, ADF mapping data flows target BI Pros. If you have been following my blog, you know that I’m big proponent for the ELT pattern for various reasons, mainly better performance and avoiding tool dependencies. Despite how much Microsoft promotes ADF mapping data flows, my typical data integration projects don’t use them. The last time I looked at them, they didn’t support ADF self-hosted runtimes, and they are a pain to debug. But if you must do transformations on the fly, e.g. when dumping data into files, then you obviously don’t have a choice.
So, what did the client decide to do? IT decided to take over the Alteryx workflows and convert them to Azure Data Factory. So much about self-service ETL.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-04-15 11:57:232022-04-15 11:57:23Power BI Dataflows vs ADF Mapping Data Flows
Nowadays, it’s unlikely to envision a data analytics solution without ingesting data from some cloud vendor. Unfortunately, as many of you have found out the hard way, moving to the cloud, such as moving your on-prem ERP system to the vendor’s cloud offering, comes at a huge burden – you relinquish control to the vendor and lose access to your data. In this letter, I’ll present several options for extracting your data out of the vendor’s realm.
I previously ranted here about cloud prohibitors – cloud providers that negate the benefits of moving to the cloud by enforcing all sorts of hoops to get to your data. This blog summarizes a few data integration options with cloud vendors that I’ve used in my projects, ranked from best to worst
Direct access to the database
This is by far your best option. If the provider allows you to access the data by directly connecting to its native storage, you should take it even if it involves higher fees, such as upgrading to a “premium” tier (a travesty considering that you didn’t have pay higher fees with their on-prem installations). There are no insurmountable engineering barriers for the vendor to provide direct access to the data in its native storage, but very few cloud vendors do it citing “issues”, such as security, impact on operational processes, etc. Here is a free piece of advice to cloud vendors: provide direct access to the underlying relational database and use this as a big differentiator against the competition. Security and performance should be on you and not the customer.
Data staging
If the direct access is not an option, the second best would be for the vendor to stage the data out, ideally to a relational database you provision, such as by using the Dynamics Data Export add-in to export data from Dynamics Online (now regretfully deprecated by Microsoft in favor of staging to data lake). Unfortunately, it looks like the norm nowadays is to export to a data lake as flat files and the extraction path becomes relational database -> flat files -> relational database. I hope that makes sense to you because it doesn’t to me. Things to watch out here for are where is the data lake located (Azure, AWS, others) and what integration options are provided. For example, only major ERP vendor supports only S3 as a data lake and provides and a JDBC driver to connect it (JDBC is a Java-based connector that can’t be used by any Microsoft-based integration tool.
Data push as flat files
Smaller and more flexible cloud providers might be willing to push the data to a storage that you provide. In such cases, you should strongly consider Azure data lake instead of FTP. For example, one cloud provider I integrated with used Ruby to call the Azure API to post data extracts to the client’s data lake storage that we set up.
REST APIs
Most cloud integration scenarios will fall in this bucket so that the vendor ensures “secure” and “controlled” access to data. The reality is that many of these REST APIs are horrible in both implementation and throughput. For example, the REST APIs of another ERP vendor couldn’t handle a batch export of 500,000 rows (a dataset that can fit into an Excel spreadsheet and be emailed around mind you). Their server would time out because of the “massive” data, and the client was asked to use callback APIs to chunk the export which of course wouldn’t either. And complexity only grows from here as some implementations require result paging, error handling, etc. forcing you to write custom code.
Manual export
If the above options are not possible, your last resort might be to use the vendor app and export the data manually. So much about automating the data integration…
Conclusion
When evaluating a cloud vendor, don’t forget to ask them how you can access your data. Extracting data by connecting to its native storage (typically a relational database) is the best option for integrating with cloud data sources, as the data is in its native format, you can fold operations, such as filtering and sorting, you can extract data incrementally, or even build SQL views if the vendor allows it. Unfortunately, the norm nowadays is to force you to call the vendor’s (often horrible) API, so the extraction effort in your ETL is on you and not the vendor.
Teo Lachev Prologika, LLC | Making Sense of Data Microsoft Partner | Gold Data Analytics
It’s unlikely to envision a data analytics solution without having to ingest data from some cloud vendor. I previously ranted here about cloud prohibitors – cloud providers that negate the benefits of moving to the cloud by enforcing all sorts of hoops to get to your data. This blog summarizes a few data integration options with cloud vendors from best to worst.
Direct access to the database – This is by far your best option. If the provider allows you to access the data by directly connecting to its native storage, you should take it even if it involves higher fees, such as upgrading to a “premium” tier (a travesty considering that you didn’t have pay higher fees with their on-prem installations). There are no insurmountable engineering barriers for the vendor to provide direct access to the data in its native storage, but very few cloud vendors do it citing “issues”, such as security, impact on operational processes, etc. Here is a free piece of advice to cloud vendors: provide direct access to the underlying relational database and use this as a big differentiator against the competition. Security and performance should be on you and not the customer.
Data staging – If the direct access is not an option, the second best would be for the vendor to stage the data out, ideally to a relational database you provision, such as by using the Dynamics Data Export add-in to export data from Dynamics Online (now regretfully deprecated by Microsoft in favor of staging to data lake). Unfortunately, it looks like the norm nowadays is to export to a data lake as flat files and the extraction path becomes relational database -> flat files -> relational database. I hope that makes sense to you because it doesn’t to me. Things to watch out here for are where is the data lake located (Azure, AWS, others) and what integration options are provided. For example, only major ERP vendor supports only S3 as a data lake and provides and a JDBC driver to connect it (JDBC is a Java-based connector that can’t be used by any Microsoft-based integration tool.
Data push as flat files – Smaller and more flexible cloud providers might be willing to push the data to a storage that you provide. In such cases, you should strongly consider Azure data lake instead of FTP. For example, one cloud provider I integrated with used Ruby to call the Azure API to post data extracts to the client’s data lake storage that we set up.
REST APIs – Most cloud integration scenarios will fall in this bucket so that the vendor ensures “secure” and “controlled” access to data. The reality is that many of these REST APIs are horrible in both implementation and throughput. For example, the REST APIs of another ERP vendor couldn’t handle a batch export of 500,000 rows (a dataset that can fit into an Excel spreadsheet and be emailed around mind you). Their server would time out because of the “massive” data, and the client was asked to use callback APIs to chunk the export which of course wouldn’t either. And complexity only grows from here as some implementations require result paging, error handling, etc. forcing you to write custom code.
Manual export – If the above options are not possible, your last resort might be to use the vendor app and export the data manually. So much about automating the data integration…
In summary, when evaluating a cloud vendor, don’t forget to ask how you can access your data. Extracting data by connecting to its native storage (typically a relational database) is the best option for integrating with cloud data sources, as the data is in its native format, you can fold operations, such as filtering and sorting, you can extract data incrementally, or even build SQL views if the vendor allows it. Unfortunately, the norm nowadays is to force you to call the vendor’s API, so the extraction effort in your ETL is on you and not the vendor.
I helped an ISV a while back with their BI model design. They purchased a data transformation tool for $5,200/year because it’s “simple to use” (the tool was designed for self-service data transformation tasks by business analysists) and “relatively inexpensive”. The idea was to run the tool manually every time they have new data, import data from text files, transform, and output the data in another set of files, and then load the transformed data in Power BI. However, as it typically happens, the data transformation complexity quickly outgrew this approach. What did the ISV learn along the way?
Stage the data – Although it’s tempting to do transformations on the fly, data typically must be staged so you can query and manipulate it. This is also required to compare the input dataset with the target dataset and take care of things like Type 2 slowly changing dimensions that may sneak in unexpected.
Get a relational database – At much lower price point of purchasing a “user-friendly” ETL tool that does transforms only, the ISV could have bought a scalable SQL Server Standard Edition priced at $1,859 per core (or $7,500 for four cores). Mind you that this is a perpetual license that will typically last you 2-3 years until it’s time for upgrade. And they must pay only for production use (remember that on-prem SQL Server is free for dev and test). Or, they could have opted for an Azure SQL Database and pay as they go (Microsoft gives away $120,000 as Azure Cloud credits for qualifying startups for two years). Or, if they are really under budget and don’t have large data volumes, they could have gone with the free SQL Server Express edition.
Use the ELT pattern – What happens when you outgrow the capabilities of the “user-friendly” tool and you must migrate to a professional tool, like SSIS or ADF? Start over. You don’t want to do this, trust me, because more than 60% of the effort to build a BI solution typically goes into data prep. Personally, I’m a big fan of the ELT pattern (see my blog “3 Techniques to Save BI Implementation Effort” for more info on this pattern) that relies heavily on T-SQL and stored procedures. If you go ELT, the tool choice becomes irrelevant as you use it only to orchestrate data tasks. For example, you use Control Flow and very simple Data Flow (just a simple source-destination data flow to stage data) in SSIS. And as a bonus, if one day you migrate to Azure Synapse, you’ll find that it recommends ELT too. Since they wanted to run ETL occasionally, they could have used Visual Studio Community Edition and the SSIS extension. Or, they could have gone completely free by using an open-source ETL tool, like Talend.
When evaluating tools, cost is not the only factor. Your design must be flexible and capable of accommodating changes which are sure to happen.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-03-30 17:39:502020-03-30 17:39:50How Much Are You Really Saving?
Scenario: Consider a SQL Server configured for AlwaysOn Availability Groups where a set of databases can fail over to another node. You have SSIS jobs and you created them on both nodes. However, you need to check if the current node on which the job is running is the primary node. If you don’t do this, the job fails because the database isn’t accessible.
Solution: In every SQL Server Agent Job, add a first step to check if one of the replicated databases in the AlwaysOn availability group is the primary replica:
IF sys.fn_hadr_is_primary_replica (‘<replicated dataset name here>’) = 0
BEGIN
EXEC msdb..sp_stop_job N’DW Daily Load’;
END
This script checks if the database is a primary replica. If this is not the case, the script stops the next step, which in this case is the “DW Daily Load” step.
SQL Server 2017 introduces the ability to scale out SSIS. The primary scenario is to enable customers to scale out their SSIS execution at the package level. Imagine a retail business that has about 300 packages to run at the end of the day to push transactional data/finance data from multiple stores to the centralized data warehouse for reporting. All the 300 packages need to run at night but they also need to finish by 6 AM in the morning before new business day starts. As business grows, data size grows, and it takes longer time to run the 300 packages and it is becoming more difficult for the ETL processing window to finish before 6 AM. With SSIS scale out feature, you can now set up the scale out cluster with 1 master and N workers, so that the master can automatically distribute the packages to the workers based on the worker availability, therefore, it helps parallelize the execution at package level and achieve faster completion time. You don’t have to worry about which packages will be executed by which worker, as it’s handled by the master. All you need is to deploy the 300 packages into the catalog and then trigger the ETL run.
Sounds like an easy fix to your long ETL processing times? As with any technology, my advice is to focus on improving the performance of your ETL first, then scale up, then scale out. Here are the top 5 performance issues that I see over and over in my consulting practice:
No parallelism – Packages run sequentially, e.g. dimensions are populated one by one and then fact tables one by one. Meanwhile, despite all the CPU power and cores you fought hard to secure, the server isn’t doing much. Instead, you should run things in parallel as much you can with the goal to saturate that server CPU bandwidth. Ideally, you should invest into a framework that can automatically distribute work across packages with on a configurable degree of parallelism, as the one that we use and is mentioned in my newsletter ” Is ETL (E)ating (T)hou (L)ive?”.
No incremental extraction – The less data you process, the faster your ETL will be. You should strive to extract only the rows that have changed if possible, using techniques such as LastUpdated timestamp, Temporal tables, or CDC.
ETL instead of ELT pattern – Influenced by Microsoft and expert advice, you’ve decided to use the data flow transforms. For example, in a recent ETL review, I found that a Lookup task caches all the 50 million rows from a fact table in memory to determine a row should be inserted or updated! What happens when (not if) one day the fact table swells to 500 million rows? Instead, almost always the ELT pattern that relies on stored procedures and T-SQL MERGE would be a better choice from a performance standpoint. 30 years went into improving and evolving Microsoft SQL Server. It would be naïve not to take advantage of this evaluation and its set-based processing. And as a bonus, one day if you decide to migrate your DW to the cloud, such as by using Azure SQL Data Warehouse, you’ll find that ELT is recommended (unfortunately, Azure SQL DW still doesn’t support MERGE but one day I hope it will).
Query optimization – Needless to say, your queries should be optimized. In the same recent review, I found that one query that extract data from ODS takes four hours to execute!
Excessive data movement – This goes back to incremental extraction but I often see ETL that does full load or partial load (e.g. the last six months) and copies millions of rows from source to staging table 1, staging table 2, …, and finally data warehouse.
If, after you follow the above best practices, you still find that you’re exceeding your ETL processing windows, you should consider scaling out SSIS. Before doing so, consider the following limitations in the SSIS scale-out feature in SQL Server 2017:
A best practice is to partition your ETL process in child packages that are orchestrated by a master package using the Execute Package Task (EPT). SSIS scale-out can run packages with EPT but it does not scale out the EPT packages execution on another machine. If you have a main package, which as various sub package execution with EPT, the package and all EPT sub package execution will run on the same worker machine, while other workers in your scale out cluster can handle other packages that are independent. If some order/dependency is needed, there will be extra work needed from you to design a master package on purpose (i.e. one master package to control the overall flow and trigger execution in Scale-out and wait for the result accordingly).
If you opt for the ELT pattern as I suggested, scaling out might not help all that much. Your gain will depend on where the performance bottleneck is. If the bottleneck is already in the database, scaling out ETL across multiple nodes will be a futile effort. But if the bottleneck is not the database, then the scale-out can still help to take advantage of multiple machines.
When a package is scheduled in scale-out, by default it is possible for it to be assigned to any worker node to be executed. But if needed, you can also specify which worker node(s) you want the package execution to be assigned to when triggering the execution. The master node doesn’t monitor the worker utilization. Instead the worker node does its own CPU or Memory’s monitoring and tells the master if it can take more packages.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2017-06-11 16:54:172017-06-11 16:54:17Scaling out SSIS in SQL Server 2017