One of trails my wife and I hiked today in the Acadia National Park was the Precipice Trail. This trail is considered one of the hardest trails in the United States. In fact, “hiking” is a misnomer as most of the ascent involves vertical rock climbing and pulling yourself up on iron rangs. Slipping and falling can surely result in a serious injury or death as there are no safety nets and there were such incidents in the past.
However, if you put yourself in the right mindset and prepare, you probably won’t find it that hard. In fact, we’ve found the descent more challenging than the ascent which we thought was exhilarating. And the Gulf of Main views were breathtaking!
How many ascents and views do we miss in life by not taking moderate risks?
I’ve been an independent consultant for almost 20 years and through most of this time, my company (Prologika) has been a Microsoft consultancy partner with Gold Data Analytics and Gold Data Platform competencies. Speaking of which, I’d like to thank all the wonderful people who have helped Prologika attain and maintain these competencies over the years by taking rigorous certification exams. I couldn’t have done it without you!
My simple definition of a consultant is an external expert whose services improve the client’s situation. Therefore, the most important criterion for measuring the consultant’s effectiveness is how much “lift” the client gets.
Effectiveness is rarely tangible because it’s difficult to measure. However, in the past, the second component (besides certifications) for maintaining the Microsoft partnership was providing customer references to Microsoft. I don’t think Microsoft ever called the customers but if they did, a simple question would have been “On the scale from to 1 to 10, how do you measure the Prologika’s intervention to improve the objective they were hired to do?” Or, “would you rehire or recommend Prologika?” That’s it, no fancy scores are necessary. Most often, the client is either happy or unhappy, although shades of gray might exist.
Fast forwarding to Microsoft modern partnership requirements and things have changed starting the beginning of this year where Microsoft introduced new criteria for measuring the effectiveness of their partners expressed as a “partner capability score” – “a holistic measurement framework which evaluates the partner on categories of performance, skilling and customer success”. Before we get to it, I find it sad that as a woke company positioned to defend minorities (see the Microsoft’s wokeness report), Microsoft has gone to great lengths to destroy its small-biz partner ecosystem over the years, including:
Favoring large “managed” partners.
Replacing the Microsoft Software Assurance consulting credits, where the client had the discretion how to spend and allocate, with revenue-centric Microsoft-managed funds which are almost impossible to get approved for, such as ECIF and PIE.
Replacing a designated Microsoft Partner Network point of contact with offshore outsourced service.
All the promises given and broken through years. Too many to mention here but it looks to me that every now and then some manager comes which a checklist of all great things Microsoft will do for partners and then all if forgotten or suffers a natural death.
Removing the Silver partner level.
Let’s now look at the new partner capability score for Data & AI, which spans three categories: performance, skilling, and customer success.
Performance – the partner must add up to 3 new customers every year. Apparently, Microsoft favors expansion of the customer base (more revenue) as opposed to doing recurring business to existing customers, which to me is by far a much better testimonial for effective services. But wait, there is a fine text explaining that not all customers are equal. “This is the number of unique customer tenants contributing at least $1000 ACR (Azure Consumed Revenue) in one of the last 2 months.” There we go. The emphasis is on selling more aggressively to customers.
Skilling – No surprises here. Microsoft wants a certain number of certified individuals. This is the only commonality with the old partner criteria.
Customer success – It quickly becomes evident that Microsoft equates “customer success” with revenue. Here we have two paths: number of deployments that depend on advanced Azure services represented in ACR (meaning expensive) and usage growth expressed as ACR growth across the customer base over the past 12 months.
There you have it. Microsoft now views partners as extension to their sales force that are pressured to sell and generate revenue to Microsoft. The more the partner sells, the better partner you are. Therefore, expect increased pressure from Microsoft partners to sell expensive products you probably don’t need, such as Power BI Premium or Fabric in the data analytics space.
The Microsoft VP who came up with this should have been fired on the spot. Gee, with all this focus on revenue, you might think that the partner gets some decent revenue cut, but that’s not the case. It doesn’t matter to me. I’m not making money from selling software and when I recommend a tool it’s always for the client’s best interest and my recommendation is usually very cost effective.
Given that my business values differ from the new Microsoft partnership values, I’m not planning to pursue further competency in the Microsoft partnership ecosystem. I’ll keep the hard earned and now retired Gold partner logo to remind me of what’s important. I’ll continue working with and recommending Microsoft products when it makes sense, such as when they are better from the competition, but without any strings attached.
I ranted many times about SaaS vendors preventing direct access to data in its native storage, which is typically a relational database. It’s sort of like going to a bank, handing them over your money, and they telling you that you can only get your money back in cash, in Bitcoin, in ₿100 bills but no more than ₿1,000 per withdrawal, or whatever madness suits the bank best. I wonder how long this bank will be in business. Yet, many companies just hand over the keys of the data kingdom to a SaaS vendor and they wonder how to get their “precious” back so they can build EDW and enable modern analytics. Since when direct access became an anathema perpetuated by mega software vendors, including Microsoft? I’ll repeat again that there are no engineering reasons to prevent direct access to your data, even if you must pay more to “isolate” you from other customers for security, performance, liability, or other “tradeoffs” for you choosing the SaaS path.
However, there are rays of sunshine here and there. In a recent integration project, I had to extract data from the InTempo ERP cloud software. Besides other integration options, InTempo supports ODBC access to their IBM Db2 database over VPN connectivity. Not only did InTempo give us direct access to the ERP data, but they also provided support services to help with the SQL queries. I couldn’t believe my luck. Finally, an enlightened vendor! On the downside, we had to send freeform SELECT statements down the wire from ADF while I personally would have preferred an option to package them in SQL views residing at the database, but I’d be pushing my luck.
Direct access to your data should be on top of your SaaS vendor selection criteria. TIP: if you hear “API” in any flavor (REST, ODATA, SOAP, etc.), run for the exit. I have nothing but horrible experience taking that path, even with Microsoft Dynamics APIs. “Data lake” is a tad better but still your best option is direct access to data in its native storage to avoid excessive integration effort and reduce data latency.
There has been a lot of noise surrounding a data lakehouse nowadays, so I felt the urge to chime in. In fact, the famous guy in cube, Patrick LeBlanc, gave a great presentation on this subject to our Atlanta Power BI Group and you can find the recording here (I have to admit we could have done better job with the recording quality, but we are still learning in the post-COVID era).
What is a Lakehouse?
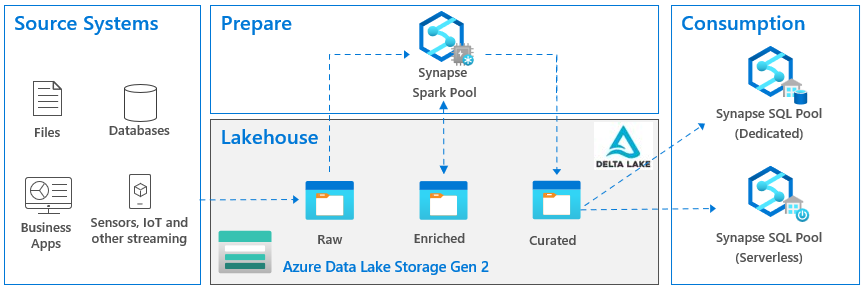
According to Databricks which are credited with this term, a data lakehouse is “a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.” It other words, it’s a hybrid between a relational data warehouse and a data lake. Sounds great, right? Visualizing this in Microsoft parlor, the last incarnation of the lakehouse architecture that I came across looks like this:
The Good
I’m sure that many large companies or companies with complex data integration needs could benefit from a similar architecture. As I said many times, staging data to a lake is a good thing when you must deal with files. For example, some cloud vendor that hasn’t matured enough to give direct access to your data, could decide to push files instead (I described a similar scenario in this blog). A “network share” on steroids, the data lake is the best place to store files. A good question here and the one I personally struggled with would be “what if the data comes from relational databases or from REST APIs?” Should you stage that data in a data lake as files before it flows into the data warehouse? A wise consultant’s answer here would be “it depends”. Here are some good reasons when this might make sense.
Stage data first – For some, a large ISV company (see related newsletter here), had to integrate data from many databases with similar but not the same schema. They preferred to stage the data to a data lake and figure out the integration “mess” caused my schema discrepancies and data quality later.
A glorified archive – For example, in case you want to reload the data, you can do it from the lake in the case where the source systems truncate data. However, my personal preference to address this scenario would be to stage the data into a relational Operational Data Store (ODS), especially in the case where changes must be tracked. In a nutshell, if I’m given a choice between a file or relational database, I’d go with the latter.
Synapse – If you decide to host your data warehouse in a Synapse dedicated SQL pool and use Azure Data Factory (ADF) to load the data, ADF will stage the data to Azure Data Lake Service (ADLS) anyway to load it faster into Synapse. Another good thing for Synapse here is that you can use Synapse Serverless to query that data using SQL which might come handy (I share some “serverless” lessons learned here).
Data science – There are some good reasons why data scientists prefer files instead of loading the data from a relational database. Or so I was told (I’m not a data scientist).
Uniformity – If your organization prefers a uniform data flow path despite the additional effort, inconvenience, and redundancy, then this might make sense. Then despite the source data type (structured or unstructured), all data follows the same ingestion pipeline. Just make sure to hire more ETL developers.
Outside these considerations, when you can connect directly to the data source, staging data to files is probably overkill as files are notoriously difficult to deal with.
The Bad
Now let’s look at the so-called zones in the lake: raw, enriched and curated, sometimes also referenced as bronze, silver, and gold. The idea here is to enrich the staged data. So, the raw zone has the staged data 1:1 as in the source. Then let’s say a data scientist needs some enrichment, and we spin more ETL to add a bunch of columns to some file. And then Business needs to reference the data that might require more enrichment. So, into the ETL rabbit hole we go again.
The problem is that many people take this architecture verbatum, whether it makes sense or not. A question came from the audience during Patrick’s presentation “What data do we add to these zones?” How do we know when it’s time to move to the next zone? And the answer here is that these zones are just a recommendation that someone has come up with. A large organization might benefit from them. But in most cases in my opinion spinning more and more ETL and moving data around just so that you follow some vendor’s best practices, makes no sense. And should you stage the data 1:1 from the source? In some cases, like the Get Data First aforementioned scenario, it might make sense. But in most cases, it would be much more efficient to stage the data in the shape you need it, which may necessitate joining multiple tables at the source (by the way, a relational server is the best place to handle joins).
The omni-presence of Synapse in such architectural diagrams is questionable at least. As I stated in another newsletter, like a red giant star, Synapse seems to engulf everything in its path in order to increase its value potential. But Synapse shouldn’t be a default choice for most organizations. It’s rather expensive and has limitations, such as lacking important T-SQL features.
Finally, Spark/Databricks that orchestrates the data preparation with Python or some other custom code since all the toolset you get is a notebook with a blinking cursor. What happened to low code, no code approach? More ETL developers to the rescue…
The Ugly
The omnipresence of the delta lake regardless if it makes sense or not. I’m sure that some scenarios for staging changing data into a lake, such as IoT streaming, will benefit greatly from a delta lake. But it shouldn’t be a default recommendation. The moment we introduce a delta lake, our tool choice becomes rather restricted because of the file format. On ETL side of things, for example, you must use data flows with Azure Data Factory (I’d personally favor ELT over data flows). And to read the data, you must provision either a Spark cluster or Synapse Serverless. So, complexity increases together with cost while data accessibility decreases.
And if you go with Databricks (credited for inventing the delta lake too), they are far more ambitious . They want to replace RDBMs for OLAP (OLTP won’t work with a delta lake for performance reasons). We’ve seen similar claims before and how they ended. Another question came from the audience during the presentation was if a lakehouse can deliver the same performance as a relational database. One house must be redundant, right? True, after rewriting their software, Databricks can deliver some decent performance (they even claim to be the world’s fastest “data warehouse” although only one other vendor submitted results to that specific benchmark). James Serra (Data & AI Solution Architect at Microsoft), whose excellent blog discusses these topics in detail, recently gave our group a presentation and said that anyone he knows of that has tried replacing a relational data warehouse with a data lake, has failed. Enough said.
What’s a best practice? A best practice to me is adopting the most efficient way to achieve something without sacrificing too much flexibility for what might be thrown at you in the future. To me, a lakehouse as a replacement for a relational data warehouse or as a default staging area is as big of a hype as Big Data was, with all the vendor propaganda surrounding it to buy stuff you don’t need. Large organizations with complex integration needs might benefit from the lakehouse architecture shown above. However, most companies could save a lot of implementation, maintenance, and licensing costs by simplifying it and judicially introducing pieces when it makes sense.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-02-08 17:11:322023-02-13 19:36:53Data Lakehouse: The Good, The Bad, and the Ugly
Microsoft re-awarded me as a FastTrack Recognized Solution Architect – Power BI for 2022! This prestigious recognition is conferred by the Power Platform product engineering team for consistently exhibiting deep architecture expertise and creating high quality solutions for customers during project engagements. I’m one of the 36 individuals worldwide who met the following criteria:
Must have a minimum of 2 years of experience with Power BI and a minimum of 5 years of experience with Enterprise BI solutions
Must have a minimum of 2 years of experience as an Enterprise BI architect
Must be working for a partner with Gold certification in Data Analytics MPN competency
Must have been lead architect for at least 2 Power BI in-production implementations with at least 200 active users (Preferably for CAT managed customers)
Amazon started in 1994 as an online marketplace for books. You’d think that after being in this business for almost 30 years, they’ve figured out the book ecommerce inside out. Unfortunately, rapid revisions (I revise annually my Power BI book) break their model. Every new revision wreaks havoc in the customer experience to purchase a book and punishes the publisher. Here is what I’ve learned after having my books sold on Amazon for many years.
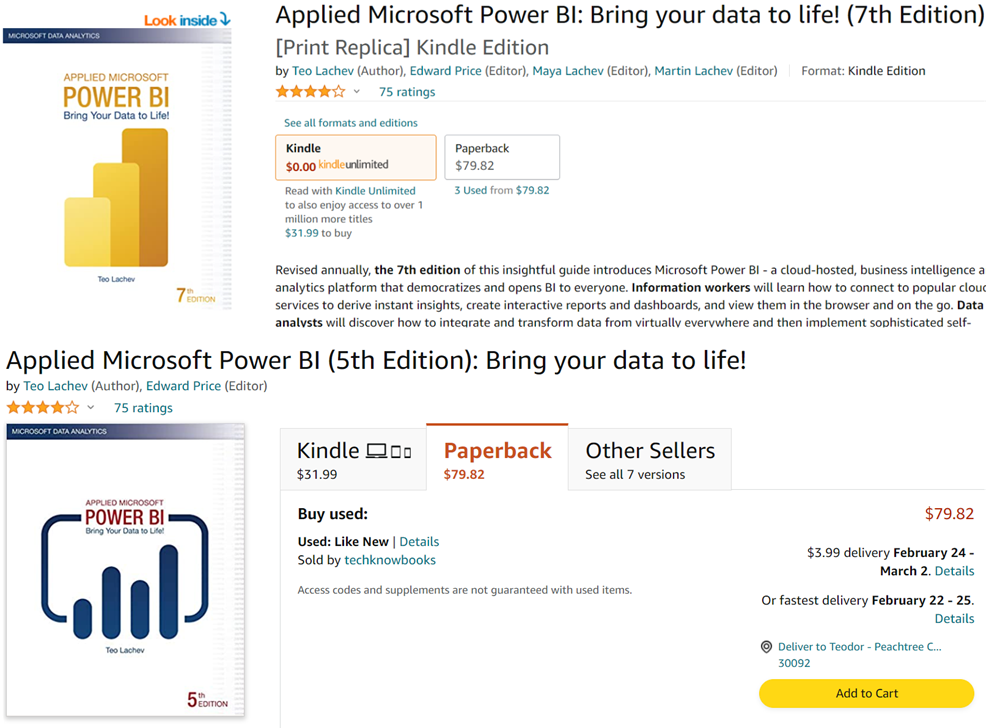
Amazon has a proprietary algorithm that decides what to show on the book detail page. My books are available in two formats: paperback and ebook (Kindle). When a customer lands on the book page, the natural expectation is that the Kindle tab would redirect to the ebook format and the Paperback tab would redirect to the paperback format of the same edition. Unfortunately, the publisher has no control over what the Paperback tab would eventually link to. For example, in the screenshot below, today the algorithm has decided that the customer would be more interested to purchase the 5th edition paperback (7th edition is currently the latest) for the modest price of $79.82 because it’s a vintage. Not to mention that the 5th edition has been long unpublished and only available from third-party sellers that should’ve been listed on the “Other Sellers” tab.
Every time a new revision is published, the book fights with itself. Despite the 7-year overall history and 75 reviews of my Power BI book, a new revision goes all the way back in the line, and its sales ranking starts from zero. Amazon doesn’t give any credit to prior revisions or reviews. And by the time the book has enough history to bubble up in the search results, it’s time for a new revision, and the cycle repeats itself.
I wrote this post mostly as an apology to my customers since there is nothing that be done to improve their Amazon book purchasing experience. The book is at the mercy of Amazon and its obsolete algorithms.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-02-20 12:47:482022-02-20 12:47:48How Power BI Broke Amazon
I’m preparing for the new Azure Data Engineer exam, which is one of options to maintain a Gold Certification for Data Analytics for MS partners that has to be renewed annually. I’m really impressed by the Azure Learning Path self-paced environment that Microsoft put together. The training material is top-notch, and I actually learn some practical and useful stuff from the covered topics on ADLS, ADF, Synapse, etc. And you can even practice in an Azure sandbox environment that Microsoft sets up and tears down for you! It’s clear that tremendous effort has gone into setting this online and free learning option. No excuse to not certify anymore …
In a previous blog, I said I consider it a travesty when a vendor’s cloud offering prohibits direct access to the data in its native storage, which is typically a relational database, and therefore a perfect store for data analytics and integration, such as to run real-time analytics or export the data to load a data mart. There is nothing simpler than connecting to a relational database, which is designed to handle efficiently select and filter operations. Unfortunately, it’s becoming a norm where the move to the cloud requires going through all sorts of hoops to access the data. Some enlightened providers offer direct access to the native store by charging a premium fee. However, this is not usually an option and most vendors require you call their REST APIs.
Since, the move to the cloud shouldn’t make things more difficult, I call these vendors “cloud inhibitors”. Such vendors usually cite concerns, such as security and performance, as reasons to prevent access. But the irony is that such issues could be easier addressed by the vendor, such as by hosting the customer on a dedicated VM (think of Power BI Premium), instead of transferring the data integration burden to the customer.
The previous “Cloud Inhibitor” award was held by Microsoft Dynamics Online that has decided to prevent access to the Dynamics SQL database and recommends the customer to consume the staged data from Azure Data Lake CDM folders. One popular ERP vendor has gone even further when embracing AWS as their platform of choice. Not only did they disallow access to their SQL Server database, but they also disallow access to the S3 data lake where they stage the data. Instead, when moving their on-prem ERP solution to the cloud, a client has found that they have two choices for data integration: call the REST APIs or use a JDBC driver, with the latter option out of reach for Microsoft apps.
I’m still researching the best option to enable this client access their data with minimum integration effort although the recommended solution by the vendor was to write a client app to call REST APIs or use Java-based ETL. How ridiculous is this given that that client could simply connect to their ERP database in the past? So much about real-time BI and no-code data integration!
If you need a convincing reason to use Edge Dev, user profiles might be it. I need access to various Power BI tenants that I need to log in. Or, your organization might have multiple Power BI tenants, such as a byproduct of acquisitions. Previously, I had to either use multiple browsers, open an incognito session (the caveat is that you can’t have two incognito sessions with different credentials), or install browser extensions to support simultaneous open sessions to Power BI. Now, all I have to do is to create a profile for each client. To do so:
Open Edge Dev.
Click the Profile icon in the top right and then click Add Profile.
Follow the steps to log in using the needed credentials.
Once the profile is created, click the profile icon and then click the desired profile. This will open a new normal (not incognito) session side by side with the other Edge DEV window. Now you have two session connected to two different Power BI tenants!
Microsoft awarded me FastTrack Recognized Solution Architect – Power BI! This prestigious recognition is conferred by the Power Platform product engineering team for consistently exhibiting deep architecture expertise and creating high quality solutions for customers during project engagements. I’m one of the 33 individuals worldwide who must meet the following criteria:
Must have a minimum of 2 years of experience with Power BI and a minimum of 5 years of experience with Enterprise BI solutions
Must have a minimum of 2 years of experience as an Enterprise BI architect
Must be working for a partner with Gold certification in Data Analytics MPN competency
Must have been lead architect for at least 2 Power BI in-production implementations with at least 200 active users (Preferably for CAT managed customers)