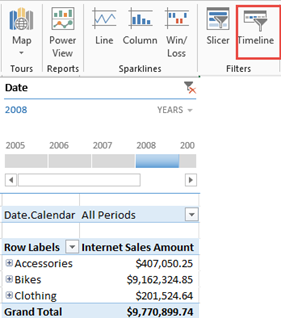
I wonder how many people believe that Tabular DistinctCount outperforms Multidimensional judging by Excel reports alone. In this case, an insurance company reported a performance degradation with Excel reports connected to a multidimensional cube. One report was taking over three minutes to run and it was requesting multiple fields on rows (insured, insured state, insured city, policy number, policy year, underwriter, and a few more) and about a dozen measures, including several distinct count measures, such as claim count, open claim count, and so on. The report would only need subtotals on three of the fields added to the ROWS zone. The cube had about 20 GB a disk footprint so the data size is not the issue here. The real issue is the crappy MDX queries that Excel auto-generates because they are asking for subtotals for all fields added to ROWS, using the following pattern:
NON EMPTY CrossJoin(CrossJoin(CrossJoin(CrossJoin(CrossJoin(CrossJoin(CrossJoin(CrossJoin(
Hierarchize({DrilldownLevel({[Insured].[Insured Name].[All]},,,INCLUDE_CALC_MEMBERS)}),
Hierarchize({DrilldownLevel({[Insured].[Insured City].[All]},,,INCLUDE_CALC_MEMBERS)})),
Hierarchize({DrilldownLevel({[Insured].[Insured State].[All]},,,INCLUDE_CALC_MEMBERS)})),
Hierarchize({DrilldownLevel({[Policy Effective Date].[Year].[All]},,,INCLUDE_CALC_MEMBERS)})),
Hierarchize({DrilldownLevel({[Policy].[Natural Policy Key].[All]},,,INCLUDE_CALC_MEMBERS)})),…
As you can see, the query requests the ALL member of the hierarchy. By contrast, a smarter MDX query generator would request subtotals on the fields that need subtotals only. For example, a rewritten by hand query executes within milliseconds following this pattern:
Hierarchize({DrilldownLevel({[Insured].[Insured Name].[All]},,,INCLUDE_CALC_MEMBERS)}) *
Hierarchize({DrilldownLevel({[Insured].[Insured City].[Insured City].Members},,,INCLUDE_CALC_MEMBERS)})) *
Hierarchize({DrilldownLevel({[Insured].[Insured State].[Insured State].Members},,,INCLUDE_CALC_MEMBERS)}))…
But we can’t change the queries Excel generates and we are at the mercy of the MDX query generator. And, the more fields the report requests, the slower the query would be. DistinctCount measures aggravate the issue further. The problem is that the DC measures cannot be aggregated from caches at deeper levels. Therefore, increasing the number of granularities in the query increases the number of subcubes that are requested from the storage engine, and they’re not going to hit earlier subcubes unless they match at the exact granularity – which is unlikely when the query results are not cached. And at some point, the doubled subcube count will trigger the query degradation (you will see many “Getting data from partition” events in the Profiler). Many of these subcubes are really needed, but some of them are generated for subtotals that Excel doesn’t really need.
I actually logged this issue more than three years ago but the Office team didn’t bother. The original bug was with Power Pivot but the issue was the same. To Microsoft’s credit, the SSAS team introduced an undocumented and unsupported PreferredQueryPatterns setting for both Multidimensional and Tabular, which can be set in msmdsrv.ini (ConfigurationSettings\OLAP\Query\PreferredQueryPatterns). I don’t think it can be set in the connection string. Excel discovers when PreferredQueryPatterns is set to 1 and generates different (drilldown) query pattern instead of the original (crossjoin) pattern. Unfortunately, it looks like more work and testing were done on the Tabular side of things where PreferredQueryPatterns is actually set by default to 1 (although you won’t see it in msmdsrv.ini). I tried a Tabular version of the customer’s cube (only a subset of tables loaded with the biggest table about 50 mil rows fact snapshot and a few distinct count measures) to test with similar Excel queries. With the default configuration (PreferredQueryPatterns=1), Tabular outperformed MD by far (queries take about 3-5 seconds). Initially, I thought that Tabular fares better because of its in-memory nature. Then, I changed PreferredQueryPatterns to 0 on the Tabular instance and reran the Tabular test to send queries with the crossjoin pattern. Much to my surprise, Tabular performed worse than the original MD queries.
PreferredQueryPatterns is 0 by default with Multidimensional due to concerns over possible performance regressions. Indeed, my tests with setting PreferredQueryPatterns to 1 on MD, caused ever-increasing memory utilization until the server ran out of memory so unfortunately it was unusable for this customer. If customer approves, I plan to log a support case. Ideally, the Office team should fix this by auto-generating more efficient MDX queries. If no help on that end, the SSAS team should make PreferredQueryPatterns work with MD. BTW, I was able to optimize somewhat the MD reports by using member properties instead of attributes (from 3 min query execution time went down to 1 min) but that was pretty much the end of the optimization path.