Considerations for Detail Reports
Nobody likes watching a report spinny. Interactive detail reports that perform well from an Analysis Services semantic layer have been the bane of my BI career. A “detail report” is a report that requests data at a lower level, e.g. policy in the insurance business, customer in Sales, etc. A detail report typically has many dimension attributes, eustomer Name, Account Number, Product Name, Product Number, etc. And, the more columns you add, the slower the report gets. The reason why such reports don’t typically perform so well when generated from a semantic layer is that Analysis Services is not SQL Server.
Multidimensional is an attribute-based model and the server cross joins the member values when you add attributes to the report. Don’t be misled by the “relational” nature of Tabular either. Its database engine (xVelocity) is an in-memory columnar database that still cross joins the column values. That said, Tabular should give you a performance boost for two reasons. First, its in-memory nature is generally faster than Multidimensional. Second, Excel has been optimized for Tabular, as I explain in my “Optimizing Distinct Count Excel Reports” blog, thanks to the undocumented PreferredQueryPatterns settings (although not listed in the msmdsrv.ini, it defaults to 1).
In a recent project, I migrated a customer from Multidimensional to Tabular. Besides other benefits, such of elimination of snapshots, reducing dramatically ETL time and analyzing data as of any date (not just at the month end), the customer wanted to improve performance of Excel detail reports. Previously, some of the detail reports would never return. After the migration, these reports would execute within a minute, and in seconds if the Excel subtotals are disabled.
Here are some tips you might find useful if you’re tasked to produce detail reports:
- If the detail reports don’t require too much interactivity, consider implementing them as SSRS paginated reports that connect directly to the database. The chances are that this approach will give you the fastest performance as the Database Engine is designed to retrieve data in sets by rows and the number of columns won’t probably affect report performance (unless of course many joins are required).
- If it’s desired to connect these reports to a semantic layer, consider Tabular because it’s better for wide & flat results.
- If Excel is used as a front end, consider Excel 2016 as Microsoft has made various performance improvements for detail reports.
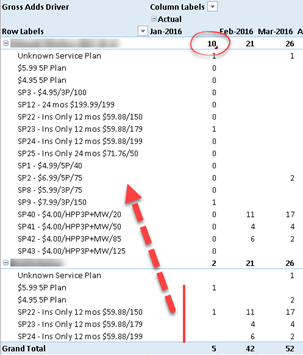
- Consider disabling Excel subtotals, as explained here. In my scenario, a detail report with no subtotals would execute under 15 seconds. However, if I enable just one column subtotal, Excel switches to a completely different query pattern (with many nested DrilldownMember levels) and the report query would take a minute. That’s because now the query needs to obtain the subtotals for each group from SSAS. Since we’re at the mercy of the Excel MDX query generator, I hope the Excel team finds a way to produce more optimal MDX queries. Ideally, a future Excel release would allow binding Excel native tables directly to SSAS with ability to define subtotals and optimized queries to load the data.
- In my experience, Power BI reports that generate DAX don’t perform necessarily any better. To make things worse, while the new PBI Matrix visual can be configured to a flattened layout, it doesn’t currently support disabling specific subtotals (currently, you can remove all row subtotals or have them for each and every column). And asking for subtotals for every column might not only contradict business requirements but it could also severely affect performance. UPDATE 8/14/2017 – The August release of Power BI Desktop supports configuring row subtotals per level.
Many thanks to Akshai Mirchandani for the SSAS product group for not losing patience throughout all these years from my complaints on this subject.