Demystifying Power BI Dataset Scale-out
Microsoft announced a public preview of Power BI Dataset scale-out (DSO) for Power Premium, Premium per User (PPU), and Power BI Embedded. In the comments below the announcement, the article implies that this feature is a replacement for the Azure Analysis Services scale-out. “If you have an AAS scale out and you migrate your databases (aka models aka datasets aka cubes) to Power BI Premium, you get scale out automatically and at no extra cost.” Scaling out for free? Sure, where do I sign?
But then further down the comments, we have this clarification “[Power BI DSO happens] if a dataset is on peak load and the vcores of your capacity aren’t maxed out. Keep in mind that scalability on a single instance isn’t linear. By scaling out, we can achieve a better utilization of available CPU resources for high workloads. On the other hand, if your vcores are already maxed out, then scaling out brings no further perf benefit.” Confused? So was I, and I reached for clarification to Microsoft. Below, is my best understanding of what happens behind the scenes.
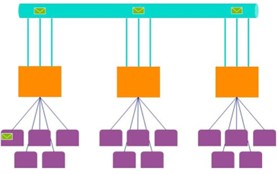
First, let’s start with a definition. By scaling out, we mean distributing the load to more machines (presumably when scaling up has saturated one server). AAS scale-out is a true scale-out because you provision additional VMs (replicas) and the system distributes queries across the available replica to achieve a linear load (to the point of saturation of course). The big downside is that you pay for each replica and that cost can surely a dent in your budget (a customer recently incurred 30K for one month with the maximum 7 replicas).
Power BI DSO gets trickier. First, Power BI monitors your overall CPU usage to make sure that you don’t abuse the system and exceed the provisioned number of cores. For example, P1 limits you to 4 background cores. If your capacity is consistently saturated, DSO doesn’t bring any benefits. Power BI will throttle all replicas if it sees sustained saturation. You paid for 4 cores and you get 4 cores overall, irrespective that you now have other read replica(s).
But then, suppose the system is in a relatively quiet state. Suddenly, at 8 AM in the morning, a burst of queries comes along from sales reps checking the latest commissions. Now, Power BI will distribute these queries across the replicas to answer them as quickly as possible without throttling. But there is also some smoothing that happens as your queries execute in Gen2. If you get 100 queries at the same time, then they can all execute together with no throttling and on different replicas. After they finish, their CPU cost may cause latency for the next set of queries – but if there’s enough of a gap between this burst of queries and the next burst of queries, then the impact will be minimal and you would just see far better experiences for the end users.
Additional performance boost can be realized by enabling Power BI core auto-scale. As your CPU usage grows beyond the provisioned cores, Power BI will provision more cores. And now you will benefit from a second replica, because a new VM is available with its own set of physical cores. By contrast, without QSO the extra cores wouldn’t really help performance of that dataset because the first replica is running on a VM with all provisioned cores.
For now, DSO targes refresh isolation (one write + one read replica) and this enables scenarios where you want to do a full refresh on a large dataset that wouldn’t otherwise fit in memory. But in future, Power BI promises DSO to scale out to more read replicas. However, I see no reason against using this feature for large datasets, such as organizational semantic models, even in its current state (free, remember?).
Finally, unlike AAS, replica synchronization is automatic if you schedule the dataset refresh in Power BI. If you go through the back door, such as to process a dataset via the XMLA endpoint, you’re on your own synchronizing the replicas.
The following table summarizes the DSO features for AAS and Power BI.
| Azure Analysis Services | Power BI | |
| Core throttling | No | Yes, with sustained loads |
| Primary scenario | Better query performance | Currently, refresh isolation |
| Synchronization | Explicit synchronization required | Automatic (Power BI dataset refresh) or explicit when XMLA endpoint is used |
| Cost | Pay per replica | No additional cost |