Using the Hash Group Hint to Speed up ColumnStore Indexes
As I mentioned in my blog post on this subject, I’ve found a good use of SQL Server 2012 columnstore indexes to speed up significantly ETL processes that need to aggregate large datasets. But we run into a snag, which got promoted to a bug by Microsoft Support Services. Under some conditions, SQL Server would create a plan that uses a “stream aggregate” operator instead of the more efficient hash match aggregate. This is illustrated by the following plans.
This plan uses the stream aggregate and the query is much slower. If you hover on the Sort predicate, you will see a warning that the sort will spill data to tempdb.
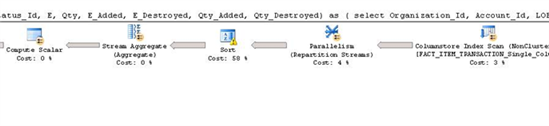
By contrast, this plan uses the Hash Match predicate and the query is about three times faster.
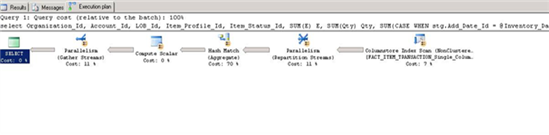
As I mentioned, this appears to be a bug with SQL Server 2012, which might not get fixed in RTM. Meanwhile, force your queries to use the HASH GROUP query hint to force SQL Server to use a hash match with columnstore indexes.
GROUP BY Organization_Id,
Item_Profile_Id,
…
OPTION (HASH GROUP)



