Handling Dates in BISM Tabular
[View:https://prologika.com/CS/cfs-file.ashx/__key/CommunityServer.Blogs.Components.WeblogFiles/blog/2308.AdventureWorks.zip:550:0]If you have experience with multidimensional cubes, you know that most cubes have a Date dimension grained at a day level. If the fact table has multiple date keys, you can join the Date dimension multiple times to the measure group so the Date dimension can play multiple roles (a role-playing dimension), such as OrderDate, ShipDate, and DueDate. If you use Excel pivot reports connected to the cube, to get support for dates you need to make the following changes as explained in Designing SQL Server 2005 Analysis Services Cubes for Excel 2007 PivotTables:
- Set the Type property of the Date dimension to Time. This is also required for MDX time-related functions, such as YTD.
- Set the ValueColumn column of the Date key to a column of date data type.
Once this is done, Excel “understands” the date semantics and treats dates as dates when you sort and filter on any field from the Date dimension. It also shows a nice menu for time calculations (relative dates).
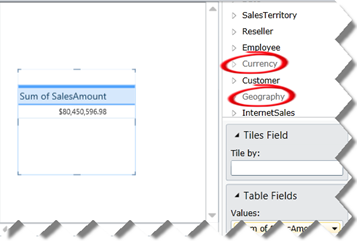
But what if another dimension has a date attribute, such as the customer’s birth date? Unfortunately, Excel won’t recognize this field as of date type and it will treat as text. Not good, but these are the limitations of Excel OLAP pivot reports.
How does BISM Tabular change things as far handling dates? Starting with SQL Server 2012 and PowerPivot version 2, you can mark a table as a Date table. In the process of doing so, you need to specify a unique identifier. Once this is done, you get the same support for dates with Excel pivot reports because they are actually OLAP pivot reports that see BISM Tabular models as cubes. Specifically, Excel will treat only fields from the Date table as dates. Take for example the following model (attached in the blog):
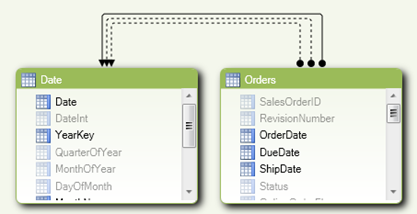
The Orders table has three date fields (OrderDate, DueDate, and ShipDate). In SQL Server 2012, BISM Tabular and PowerPivot support multiple joins between tables, as Kasper de Jonge explains in his PowerPivot Denali: Working with multiple relationships between two tables blog. Well, kind of, because only one join can be active (the one in the solid line). The other dotted relationships can be used for DAX calculations, such as SalesAmountByDueDate, SalesAmountByShipDate, etc. In other words, BISM Tabular doesn’t support true role-playing tables and you won’t get automatically DueDate and ShipDate instances of the Date table. You can import the Date table multiple times but only one table can be marked as a Date table. However, Power View (code-named Crescent) is designed from ground up to support natively BISM Tabular models. Consequently, the Excel date limitations disappear, as shown in the table below.
| Date Features | Excel | Power View |
| Date types | Only in Date table | All tables |
| Relative Dates | Only in Date table | N/A |
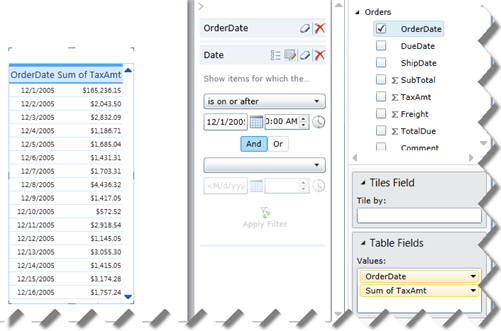
Power View treats any Date field as a date. For example, this Power View report shows the OrderDate and TaxAmt fields from the Order table. The OrderDate field is of date data type. As you can see, I can filter on dates after a given date and Power View shows the correct results. Unfortunately, Power View doesn’t support relative dates as Excel does so you must define DAX time calculations.
In short, here are some recommendations to get the most of dates:
- If you need to support multiple dates, leave the columns as a of date data type. Don’t use integer keys or smart keys, which are a common practice in data warehousing, to join to the Date table.
- Have a Date table that joins to the date that is mostly commonly used so users can aggregate by quarters, years, etc. Make sure that the date columns in the other tables don’t include times because you won’t be able to join 10/19/2011 8:40 PM to 10/19/2011. If you need to have the same support for the other dates, reimport the Date table multiple times.
- Consider creating inactive relationships for the other dates to be able to implement DAX calculations.
- Use Power View for reporting. Besides better handling of dates, Power View will give you better performance with transactional reporting, as I explained in my Transactional Reporting with BISM Tabular blog.
BTW, speaking of dates and BISM Tabular, Boyan Penev (MVP SQL Server) has implemented a nice Date Stream feed on Azure Data Market. If you decide to consume the feed, you would notice that the DateKey column is returned as ISO8601 date (such as 2011-10-29T00:00:00. Unfortunately, Excel doesn’t recognize the ISO8601 format. You might think that you can around this predicament by creating a calculated column that removes the time portion but you can use a calculated column as a unique identifier in the Date table. As a workaround, save the feed as a file and strip out the time portion so you can set the data type to Date.
 MDX is the query language for multidimensional cubes. Many BI practitioners perceive MDX to have a high learning curve probably not that much for the language itself but for the multidimensional concepts you need to master before you can get something out of it. When interacting with the community, I am frequently asked to recommend a MDX book. So far, my recommendations have been
MDX is the query language for multidimensional cubes. Many BI practitioners perceive MDX to have a high learning curve probably not that much for the language itself but for the multidimensional concepts you need to master before you can get something out of it. When interacting with the community, I am frequently asked to recommend a MDX book. So far, my recommendations have been