Columnstore Indexes To Speed ETL
SQL Server 2012 introduces columnstore indexes. Using the same in-memory VertiPaq engine that powers PowerPivot and Analysis Services Tabular, columnstore indexes can speed up dramatically SQL queries that aggregate large datasets. For a great introduction to columnstore indexes, see the video presentation, “Columnstore Indexes Unveiled” by Eric Hanson. I personally don’t see columnstore indexes as a replacement of Analysis Services because an analytical layer has much more to offer than just better performance. However, in a recent project we’ve found a great use of columnstore indexes to speed up ETL processes.
Issue: Perform an initial load of a snapshot fact table for inventory analysis from another fact table with one billion rows. For each day, extract some 200 million rows from the source fact table and group these rows into a resulting set of about 300,000 rows to load the snapshot fact table for that day. The initial estimates indicated that that the extraction query alone takes about 15 minutes when using a clustered index. And, that’s just for one day. Given this speed, we estimated the initial load could take weeks.
Solution: We upgraded to SQL Server 2012 and created a columnstore index on selected columns from the source fact table. We excluded high-cardinality columns that were not used by the extraction query to reduce the size of the index. Creating the index on the source table (1 billion rows) took about 10 minutes and this is very impressive. The disk footprint of the index was about 4GB. We ran the same extraction query and saw a five-fold performance improvement. This query, which would previously run for 15 minutes with a B-tree clustered index, would now finish in 3 minutes with a columnstore index.
When testing your queries with columnstore indexes, it is important to make sure that the query executes in Batch mode. As you can see in the screenshot below, the query uses the columnstore index and the execution mode is Batch. If it says Row, the query performance degrades significantly. Watch Eric Hanson’s presentation to understand why this happens and possible workarounds.
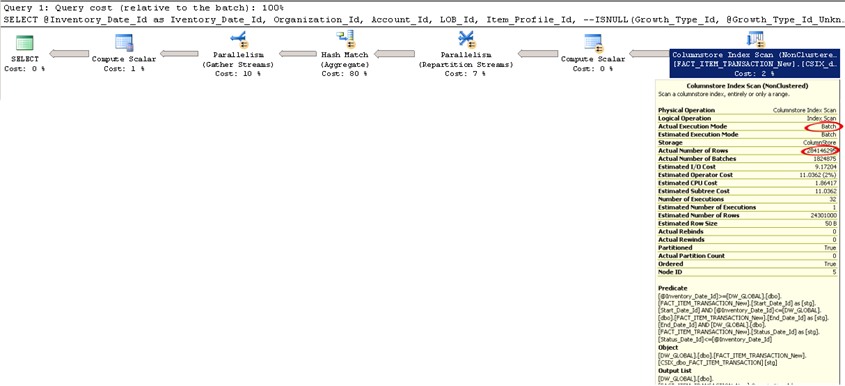
When I did initial tests to test the columnstore index, I ran into a gotcha. I tested a simple “SELECT SUM(X) FROM TABLE” query to find that it executes in a Row mode and the query took about 2 minutes to finish. As usual, the first thing I try doesn’t work. As it turned out, currently a columnstore index doesn’t support batch mode with scalar aggregates. You need to rewrite the query with a GROUP BY as Eric Hanson explains this in more details in his blog, “Perform Scalar Aggregates and Still get the Benefit of Batch Processing”. This is rather unfortunate because every ad-hoc report starts with the end user dropping a measure and the report tool generating such queries.
When testing the performance gain, it’s useful to compare how the same query would perform without a columnstore index. Instead of having two tables or dropping the index, you could simply tell SQL Server to ignore the columnstore index, such as:
SELECT … FROM…WHERE…GROUP BY…
OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX)
To sum up, when you are pushing the envelope of traditional B-tree indexes and queries aggregate data, consider SQL Server 2012 columnstore indexes. The query optimizer would automatically favor a columnstore index when it makes sense to use it. Columnstore indexes require a read-only table but the cost of dropping and recreating them is not that high. Or, you could add them to speed up the initial DW load and drop them once the load completes.


