Dynamic Dimensions
Scenario
You need to assign a dimension dynamically to a cube measure group, such as to calculate binning. In the extreme example, you might need to perform fact row level evaluation to determine where the dimension “fits” in. Consider the following example from the insurance industry. An ODS-style Claim table interprets every change to the claim table as a Type 2 change by creating a new row and expiring the previous row of the claim.
| Claim_Key | Start_Date | End_Date | Claim_Number | Status |
| 1 | 1/1/2010 | 5/1/2010 | C00001 | New |
| 2 | 5/2/2010 | 3/8/2012 | C00001 | Open |
| 3 | 3/9/2012 | 12/31/9999 | C00001 | Closed |
Options
Given this scenario, you might want to count the number of claims as of any date. You have two options:
- Create a Claim Snapshot fact table taken at a daily or monthly interval.
- Dynamically associate the Date dimension. In Multidimensional, this will require creating a Claim dimension and a Claim measure group, both bound to the same Claim table. Then, you can use the following script to “associate” the Date dimension (added as a unrelated dimension to the cube) to the Claim measure group:
CREATE MEMBER CURRENTCUBE.[Measures].[ClosingAccountingDate] AS [Date].[Calendar].MemberValue, VISIBLE = 0 ;
Scope
(
(
MeasureGroupMeasures(“Fact Claim”)
–
{
[Measures].[Start Date],
[Measures].[End Date]
}
),
[Date].[Calendar].Members,
Leaves([Claim])
);
this = iif ([Measures].[ClosingAccountingDate]>=[Measures].[Start Date] and [Measures].[ClosingAccountingDate]<=[Measures].[End Date],
Measures.CurrentMember, null);
End Scope;
End Scope;
To simplify the evaluation, the MemberValue property of all attributes of the Date dimension is bound to the closing date of the period, e.g. 12/31/2014 for year 2014, 3/31/2014 for any day in Q1, and 1/31/2014 for any day in January 2014. The scope assignment includes all measures in the Fact Claim measure group, except the Start Date and End Date measures since we don’t want to overwrite them. It also scopes on all members of the Calendar hierarchy of the Date dimension so that the calculation is performed at any level of the Calendar hierarchy. For example, if the user selects 2014 as a year, the calculation is performed as of 12/31/2014. Moreover, the Leaves([Claim]) scope positions at the measure leaves so we can evaluate any row in the fact table by comparing if the ‘as of’ date falls in the range of Start Date and End Date for that row.
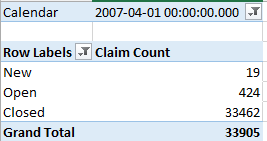
Are we happy? We might be but end users might not be so excited. The problem is that this remarkably simple scope assignment can put a remarkable dent in the query performance. For any date, the server has to perform the evaluation for every row in the fact table. With a Claim dimension and a measure group with 500,000 rows, calculating the counts executes relatively fast (within a few seconds). However, running a trend query that requests counts for every day in a quarter might take a minute or so. The larger the claim dimension and the cube subspace that the query requires, the worse the performance will be. The performance is further impacted if you have other calculations on top of the claim counts.
Scope assignments are a very powerful and useful feature of Multidimensional but you shouldn’t abuse them. Keep the scope as narrow of possible to limit the cube space where the calculation is applied. Although it might require ETL effort, materialize whenever you can. For example, although it might result in millions of rows, a snapshot would perform much better with the above scenario. Further, performance can be further enhanced by partitions and aggregations while dynamic granular calculations won’t.


