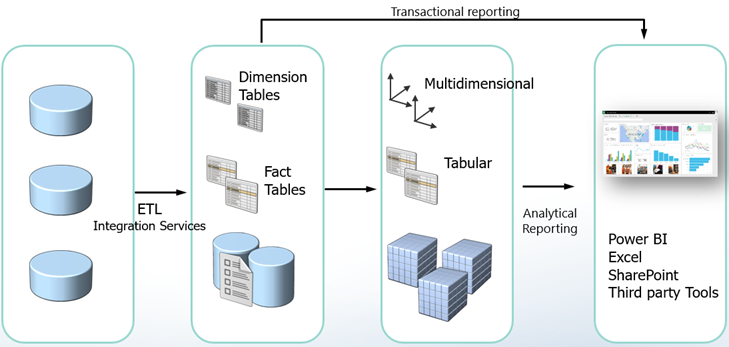
Beware Fast Columnar Databases
A large company uses the SAP HANA ERP system. Users requires real-time access to transactional data. To avoid performance degradation, SLT replication (trigger-based change data capture) replicates data to another SAP HANA system that is used solely for reporting. The problem is that the more detailed the report gets and the more columns it has, the slower it gets and SAP HANA throws out of memory exceptions.
SAP HANA is an in-memory columnar database like Tabular. So, it stores data in columns, not rows. Columnar databases are primarily designed for analytical reports which typically have a few columns (sales by customer, product, date), but can potentially aggregate large datasets. As the reporting grain lowers and more columns are added (order number, order line item, customer name, phone number, etc.), a columnar database has to cross-join more and more columns. This is not efficient and performance quickly degrades irrespective that storage is fast. SSAS Tabular and Power BI are no different. SAP HANA complicates the issue further by preventing direct access to tables and requiring “analytical” views that join tables and potentially nest other views.
So, what’s the solution? Use the right tool for the job. A relational database is designed to transactional reports and it’s very efficient for joining tables together on indexed columns. In this case, performance and user satisfaction would probably be much better if SAP HANA replicates to an SQL Server database instead to a columnar database. Use columnar databases for analytical reports. Every technology has limits and “super-fast” in-memory columnar databases are no exception. Resist the vendor propaganda.