Optimizing Massive SQL Joins
Scenario: Run ETL to perform a full data warehouse load. One of the steps requires joining four biggish tables in a stating database with 1:M logical relationships. The tables have the following counts:
VOUCHER: 1,802,743
VOUCHER_LINE: 2,183,469
DISTRIB_LINE: 2,658,726
VCHR_ACCTG_LINE: 10,242,414
Observations: On the development server, the SELECT query runs for hours. However, on the UAT server it finished within a few minutes. Both servers have the same data and hardware configuration, running SQL Server 2012 SP1.
Solution: Isolating the issue and coming up with a solution wasn’t easy. Once we ruled out resource bottlenecks (both servers have similar configuration and similar I/O throughput), we took a look at the estimated query plan (we couldn’t compare with the actual execution plan because we couldn’t wait for the query to finish on the slow server).
We’ve notice that the query plans were very different between the two servers. Specifically, the estimated query plan on the fast server included parallelism and hash match join predicates. However, the slow server had merge M:M join predicates. This requires a tempdb work table for inner side rewinds which surely can cause performance degradation.
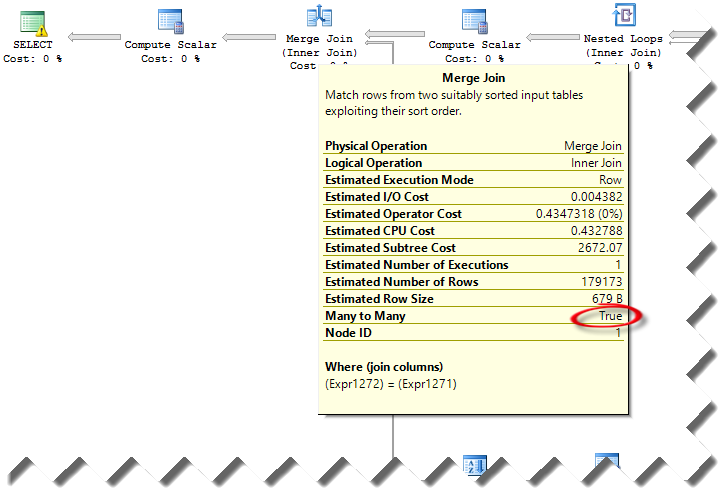
Interestingly, the cardinality of the tables and estimated number of rows didn’t change much between the two plans. Yet, the query optimizer decided to choose very different plans. At this point, we figured that this could be an issue with statistics although both servers were configured to auto update statistics (to auto-update statistics SQL Server requires modifications to at least 20% of the rows in that table). The statistics on the slow server probably just happened to have a sample distribution that led to a particular path through the optimizer that ended up choosing a serial plan instead of a parallel plan. Initially, we tried sp_updatestats but we didn’t get an improvement. Then, we did Update Statistics <table name> With Fullscan on the four tables. This resolved the issue and the query on the slow server executed in par with the query on the fast server.
Note: Updating statistics with full scan is an expensive operation that probably shouldn’t be in your database maintenance plan. Instead, consider:
1. Stick with default sampled statistics
2. Try hints for specific queries that exhibit slow performance, such as OPTION (HASH JOIN, LOOP JOIN) to preclude the expensive merge joins.
Special thanks to fellow SQL Server MVPs, Magi Naumova, Paul White, Hugo Kornelis, and Erland Sommarskog for shedding light in dark places!



