To expand on my announcement about SQL Server 2012 editions, I welcome the new BI edition for the following reasons:
The BI edition will include all BI features, including features that would previously require an enterprise edition, such as SSAS partitioning and semi-additive functions, as well as SSRS data-driven subscriptions. Therefore, from a functionality perspective, there will be no difference between BI and Enterprise editions as far as BI is concerned. That’s said, the Enterprise edition includes a set of database engine features not found in the BI edition, such as partitioning, ColumnStore indexes, AlwaysOn, etc.
The BI edition could be a cost-effective alternative for ISVs and smaller deployments. For example, the Enterprise edition will cost you over 50K with a two-socket 4-core server. However, the BI edition will cost you $8,592 + Nx$209, where N is the number of users. So, for 20 users, it will be less than 13K. The cost convergence with this hardware configuration is about 200 users. Above that number Enterprise will be more cost effective, unless of course you decide to upgrade to say 4-socket server in which case you need to upgrade your Enterprise license.
Once you’ve purchased a CAL for a user, that user can access multiple licensed SQL servers. So, if you install SharePoint and Analysis Services in SharePoint integration mode on one server, which is licensed using the above formula, and then you install SSAS in Multidimensional or Tabular mode on a separate server, you need to pay only $8,592 for the second server. You don’t need to purchase new CALs. Per-user pricing allows you to spread the implementation across the appropriate number of machines without paying a significant price.
[View:https://prologika.com/CS/cfs-file.ashx/__key/CommunityServer.Blogs.Components.WeblogFiles/blog/2308.AdventureWorks.zip:550:0]If you have experience with multidimensional cubes, you know that most cubes have a Date dimension grained at a day level. If the fact table has multiple date keys, you can join the Date dimension multiple times to the measure group so the Date dimension can play multiple roles (a role-playing dimension), such as OrderDate, ShipDate, and DueDate. If you use Excel pivot reports connected to the cube, to get support for dates you need to make the following changes as explained in Designing SQL Server 2005 Analysis Services Cubes for Excel 2007 PivotTables:
Set the Type property of the Date dimension to Time. This is also required for MDX time-related functions, such as YTD.
Set the ValueColumn column of the Date key to a column of date data type.
Once this is done, Excel “understands” the date semantics and treats dates as dates when you sort and filter on any field from the Date dimension. It also shows a nice menu for time calculations (relative dates).
But what if another dimension has a date attribute, such as the customer’s birth date? Unfortunately, Excel won’t recognize this field as of date type and it will treat as text. Not good, but these are the limitations of Excel OLAP pivot reports.
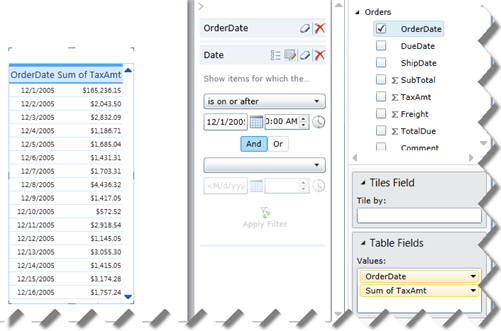
How does BISM Tabular change things as far handling dates? Starting with SQL Server 2012 and PowerPivot version 2, you can mark a table as a Date table. In the process of doing so, you need to specify a unique identifier. Once this is done, you get the same support for dates with Excel pivot reports because they are actually OLAP pivot reports that see BISM Tabular models as cubes. Specifically, Excel will treat only fields from the Date table as dates. Take for example the following model (attached in the blog):
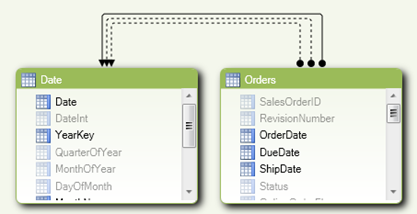
The Orders table has three date fields (OrderDate, DueDate, and ShipDate). In SQL Server 2012, BISM Tabular and PowerPivot support multiple joins between tables, as Kasper de Jonge explains in his PowerPivot Denali: Working with multiple relationships between two tables blog. Well, kind of, because only one join can be active (the one in the solid line). The other dotted relationships can be used for DAX calculations, such as SalesAmountByDueDate, SalesAmountByShipDate, etc. In other words, BISM Tabular doesn’t support true role-playing tables and you won’t get automatically DueDate and ShipDate instances of the Date table. You can import the Date table multiple times but only one table can be marked as a Date table. However, Power View (code-named Crescent) is designed from ground up to support natively BISM Tabular models. Consequently, the Excel date limitations disappear, as shown in the table below.
Date Features
Excel
Power View
Date types
Only in Date table
All tables
Relative Dates
Only in Date table
N/A
Power View treats any Date field as a date. For example, this Power View report shows the OrderDate and TaxAmt fields from the Order table. The OrderDate field is of date data type. As you can see, I can filter on dates after a given date and Power View shows the correct results. Unfortunately, Power View doesn’t support relative dates as Excel does so you must define DAX time calculations.
In short, here are some recommendations to get the most of dates:
If you need to support multiple dates, leave the columns as a of date data type. Don’t use integer keys or smart keys, which are a common practice in data warehousing, to join to the Date table.
Have a Date table that joins to the date that is mostly commonly used so users can aggregate by quarters, years, etc. Make sure that the date columns in the other tables don’t include times because you won’t be able to join 10/19/2011 8:40 PM to 10/19/2011. If you need to have the same support for the other dates, reimport the Date table multiple times.
Consider creating inactive relationships for the other dates to be able to implement DAX calculations.
Use Power View for reporting. Besides better handling of dates, Power View will give you better performance with transactional reporting, as I explained in my Transactional Reporting with BISM Tabular blog.
BTW, speaking of dates and BISM Tabular, Boyan Penev (MVP SQL Server) has implemented a nice Date Stream feed on Azure Data Market. If you decide to consume the feed, you would notice that the DateKey column is returned as ISO8601 date (such as 2011-10-29T00:00:00. Unfortunately, Excel doesn’t recognize the ISO8601 format. You might think that you can around this predicament by creating a calculated column that removes the time portion but you can use a calculated column as a unique identifier in the Date table. As a workaround, save the feed as a file and strip out the time portion so you can set the data type to Date.
SQL Server 2012 introduces a Reporting Services feature called Data Alerts. Data alerts notify a selected list of recipients about data changes on the report. Behind the scenes, data alerts use the report data feeds feature which was introduced in SQL Server 2008 R2. Consequently, similar to subscriptions, data alerts run in the background and poll the reports for changes. For more information about the data alerts architecture, read the Data Alerts (SSRS) topic in BOL.
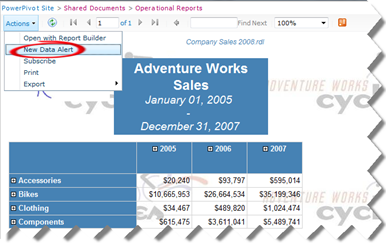
The steps to create a data alert for the Company Sales 2008 report follow (note that creating alerts require View Items and Create Alerts SharePoint permissions):
Open the report in SharePoint.
Expand the Actions menu and click New Data Alert.
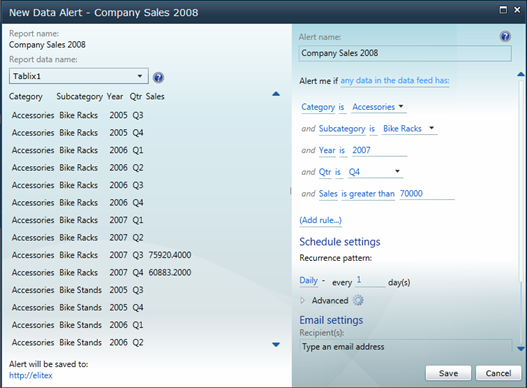
Reporting Services opens the New Data Alert dialog box. The Report Data Name drop-down list shows all data regions defined on the report. In the case of the Company Sales report, there is only one data region – Tablix1. In addition, Reporting Services shows you the data that feeds the region based on the report parameters selected.
In the right pane, click the Add Rule button to specify criteria for activating the alert. In my case, I want the alert to be triggered for the Accessories product category, Bike Racks product subcategory, year 2007, quarter Q4, and Sales greater than 70,000. As the report data shows, currently the Sales value for these criteria is 60,883.20. As new data is coming in, this value will probably increase and I want to be notified after it exceeds 70,000. I set the alert schedule to run on a daily basis (other options include Weekly, Hourly, or Minute).
Next, you specify the e-mail addresses of the recipients who will get notified when the criteria are met and the e-mail subject text. Once you click Save, the alert is saved in the Reporting Services database and scheduled for execution with the SQL Server Agent. I can see and manage the alerts I’ve created by expanding the report context menu in SharePoint and clicking Manage Data Alerts.
Reporting Services data alerts have the following limitations:
They are only available in SharePoint. Reporting Services in native mode doesn’t support data alerts.
They are supported with operational reports only, such as reports created by Report Designer or Report Builder and deployed to the SharePoint. Data alerts cannot be created on Power View reports.
Similar to subscriptions and report caching, data alerts require stored credentials. Consequently, developers targeting BISM Multidimensional or Tabular must go through the same hoops (none of them easy) to use alerts with Analysis Services. If you are not happy about this limitation, please vote for my suggestion on connect.microsoft.com that is time for Microsoft to address this limitation.
SQL Server 2012 data alerts extend the Reporting Services capabilities to poll reports and trigger notifications when report data changes. If you target data sources that require standard security (login and password), the feature is very easy to use and business users will probably love it.
Today happens to be my birthday. To reverse the tradition, how about I give you a gift? If you find yourself spending hours creating partitions in BIDS, you might find the Partition Generator sample (requires registration at the Prologika website) useful. Often, I partition larger cubes by month which may require creating quite a few partitions. Not only is this time-consuming and tedious, but is also error-prone as you can easily get the partition slice query wrong. Written as a C# console application, Partition Generator has the following design goals:
Keep it simple on purpose and due to time constraints. So, no GUI yet and you need to have basic .NET coding skills. You will need Visual Studio 2008 or later with C# to configure it.
Auto-generate a partition definition file in an offline mode without making changes to the server by default. You can use this file to replace the *.partitions file in BIDS so the partitioning scheme can become a part of your project.
Support an online mode where you can deploy the partition changes to the server.
Configuring Partition Generator
Configuring partition generator requires opening the source and making changes to reflect your environment. Specifically, you need to update the following variables:
staticstring _server = “<your server>”; // SSAS server where the cube is deployed
staticstring _cube = “<cube>”; // SSAS cube to partition
staticstring _measureGroup = “<measure group>”; // Measure group to partition
staticstring _dataSource = “<data source name>”; // The data source name
staticDateTime _dateStart = newDateTime(2007, 1, 1); // start date for the period
staticDateTime _dateEnd = newDateTime(2020, 12, 31); // end date for the period
// the partition query
staticstring _query = “SELECT * FROM [dbo].[FactInternetSales] WHERE OrderDateKey “;
Note that you need a live cube to connect to which can be partitioned or not partitioned (default partition only). The start date and end date variables specify the start date for the first partition and end date for the last partition respectively. By default, Partition Generator will partition by month but you can overwrite this in code by changing the following line:
_dateStart = _dateStart.AddMonths(1); // assuming parititon by month
Partition Manager creates also start and end partitions for dates outside the date range which could be handy if you forget to add partitions after the end date is passed. Partition Generator sets also the partition slice which is a recommended performance-optimization technique.
Updating the Project
Once you configure Partition Generator, run it with Ctrl+F5. It uses AMO to retrieve the cube metadata and generates a partitions.xmla file in the project bin\debug folder.
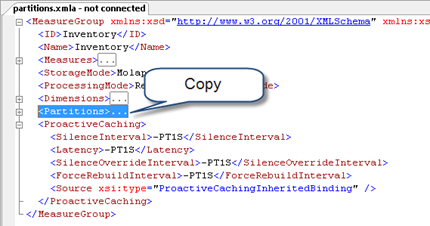
Double-click the partitions.xmla to open it in SQL Server Management Studio.
Find and collapse the Partitions XML element. Select the Partitions element and press Ctrl+C to copy its content.
Back up your SSAS project. Open your SSAS project in BIDS. In Solution Explorer, click Show All Files.
Expand the Cubes folder, right-click the <cube name>.partitions file and click View Code to open its source.
Find and select the entire Partitions element for the measure group you want to partition, and press Ctrl+V to replace the source with new partition schema which you copied in SSMS.
Save the project and close BIDS. That’s because BIDS doesn’t handle well changes made directly to the source files.
Open the SSAS project again in BIDS. Open your cube in the Cube Designer and click the Partitions tab. You should see the new partitions.
Deploying Partitions
By default, Partition Generator doesn’t change the deployed cube. It reads metadata only. However, you can be configured to deploy the partition changes. This could be useful when you want to experiment with different partitioning schemes, such as by month, quarter, year, etc. To configure Partition Manager to deploy the changes:
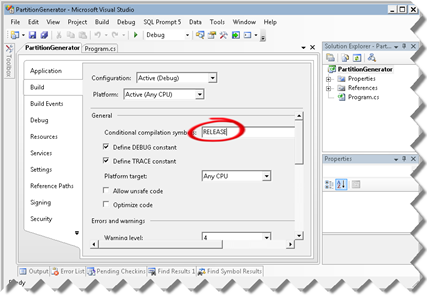
In the PartitionGenerator project, right-click the PartitionGenerator project node in Solution Explorer and click Properties.
In the Project Properties dialog box, select the Build tab and define a RELEASE conditional compilation symbol as follows:
Run Partition Manager to generate both the partitions.xmla file and apply the changes to the SSAS server.
I haven’t tested Partition Manager with BISM Tabular. It should work since Tabular uses the same Partition element in the model (*.bim) file. One more thing – Partition Manager is not supported so please use it at your own risk.
MDX is the query language for multidimensional cubes. Many BI practitioners perceive MDX to have a high learning curve probably not that much for the language itself but for the multidimensional concepts you need to master before you can get something out of it. When interacting with the community, I am frequently asked to recommend a MDX book. So far, my recommendations have been Microsoft SQL Server 2008 MDX Step by Step by Brian Smith at el for beginners and MDX Solutions by George Spofford at el for more advanced users.
I will add MDX with Microsoft SQL Server 2008 R2 Analysis Services Cookbook by Tomislav Piasevoli (MVP – SQL Server) to my recommendation list. This book takes an interesting approach that will be particularly appealing to readers who have already mastered the basics. As its name suggests, the book is a collection of recipes that you can quickly refer to when you tackle a specific MDX requirement. For example, suppose you need to obtain the last date with data in the cube. You flip to Chapter 2: Working with Time and you find a section Getting Values on The Last Date With Data. In it, the author provides the necessary background to explain the concept and provides a 9-step recipe for implementing it. Besides its practical and concise style, another thing that I liked about this book is that it targets the Adventure Works cube so you don’t have to spend time installing and learning other databases. You can hit the ground running by just copying and executing the query.
All in all, this is great book to add to your repertoire of Analysis Services books. The author is an industry-recognized expert who has many years of experience in developing BI solutions with Analysis Services and this becomes evident quickly. Get the recipes!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2011-10-20 23:49:002016-02-16 10:23:08Book Review: MDX with Microsoft SQL Server 2008 R2 Analysis Services Cookbook
Disabling check constraints, such as foreign key constraints, is often required when populating a data warehouse. For example, you might want to disable a check constraint to speed up loading of a fact table.
How do we disable check constraints in SQL Server?
You can script each check constraint or you can use the undocumented sp_MSforeachtable function.
ALTER TABLE [dbo].[FACT_ITEM_INVENTORY] NOCHECK CONSTRAINT [FK_DIM_DATE_FACT_ITEM_INVENTORY_Date_Id] — disables a specific contraint
sp_MSforeachtable ‘ALTER TABLE ? NOCHECK CONSTRAINT ALL’ — disables all contraints in the database
Once the foreign keys are disabled, you can run the ETL job or delete records from the referenced table without referential integrity checks. Note that you cannot truncate a table even if you have disabled the constraints due to the different way SQL Server logs the truncate operation. You must drop the constraints if you want to truncate a table. You can use sp_MSforeachtable to drop constraints as well although I personally prefer to disable them for a reason that will become obvious in a moment.
How do we enable check constraints?
The same way you disabled them but this time you use the CHECK predicate:
ALTER TABLE [dbo].[FACT_ITEM_INVENTORY] CHECK CONSTRAINT [FK_DIM_DATE_FACT_ITEM_INVENTORY_Date_Id] — enables a specific constraint
sp_MSforeachtable ‘ALTER TABLE ? CHECK CONSTRAINT ALL’ — enables all contraints in the database
Does SQL Server verify referential integrity for existing data when you re-enable check constraints?
This is where the behavior differs between recreating and enabling constraints. If you drop and create the constraints, the server will check the data unless WITH NOCHECK is used.
ALTER TABLE [dbo].[FACT_ITEM_INVENTORY] WITH NOCHECK ADD CONSTRAINT [FK_DIM_DATE_FACT_ITEM_INVENTORY_Date_Id] FOREIGN KEY([Date_Id]) REFERENCES [dbo].[DIM_DATE] ([Date_Id])
The server doesn’t check existing data if you enable a previously disabled constraint. You can manually check foreign key violations by using this command:
dbcc checkconstraints(FACT_ITEM_INVENTORY) –- checks a specific table
dbcc checkconstraints — checks the entire database
The checkconstraints command will output all rows that violate constraints.
UPDATE 10/31/2011
Reader Ian pointed out that re-enabling foreign key constraints without checking data marks them as non-trusted. Consequently, the SQL Server optimizer may choose different execution plans for a certain range of queries. Tibor Karaszi explains this in more details in his blog Non-trusted constraints and performance. Paul White also mentions about a bug in this area. This makes me believe that enabling check constraints without checking data should be avoided. Therefore, to speed up fact table imports for large dataset consider:
Disable foreign key constraints
Drop indexes on fact tables
Import data
Recreate indexes on fact tables
Re-enable constraints with the WITH CHECK option
sp_MSforeachtable ‘ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL’ — enables all constraints in the database
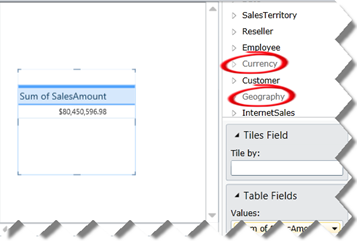
Similar to Report Builder models (now obsolete), Power View (formerly known as Crescent) filters metadata automatically. The reasoning behind this feature is that the tool should guide the user to choose only tables that are related to the ones used on the report to avoid Cartesian joins. For example, if the user has selected Sales Amount from the Reseller Sales table, Power Pivot automatically disables Currency and Geography tables because they are not related to the Reseller Sales table. The Metadata pane shows these tables greyed out and the user cannot choose a column from these tables.
As useful as this feature is, it can get in the way for the same reasons the Report Builder metadata filtering didn’t work so well with multidimensional cubes. Marco Russo has already reported an issue that this feature ignores M2M calculations in the model. I believe this will be even a bigger issue one day when Power View supports multidimensional cubes because there are scenarios where dimensions are not directly related to a fact table but still can be used for slicing, such as a shim dimension for time calculations that is populated with scope assignments.
If you agree, please vote for the suggestion I’ve submitted on connect. Ideally, there should be a visual indicator that a table is not related but the user should still be able to select a column. Or, the modeler should be able to overwrite this behavior per table.
About four years ago, in my article Protect UDM with Dimension Data Security, I introduced an approach to secure dimension data in multidimensional cubes by using a factless bridge table. Since then, many BI practitioners have favored this approach because of its simplicity, reusability (transactional reports can join to the security table), and performance. Now that organizational tabular projects support data security, I wanted to try it with BISM Tabular. As it turned out, the factless bridge table approach worked out just fine.
Suppose that you’ve build a tabular project on top of the Adventure Works DW database and the SecurityResellerFilter table is the bridge table that stores the resellers that an employee is authorized to view. As shown in the diagram, SecurityResellerFilter has two relationships SecurityResellerFilter[EmployeeKey] and Employee[EmployeeKey] and SecurityResellerFilter[ResellerKey] and Employee[ResellerKey]. You’d probably want to hide the SecurityResellerFilter table so the end users can’t browse it.
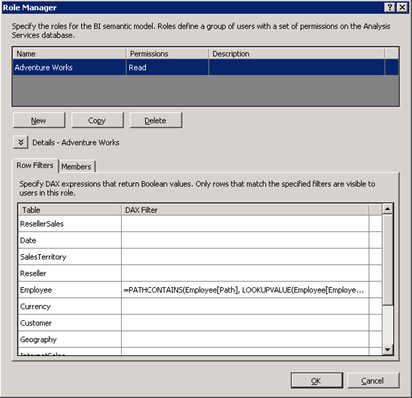
Given this model, implementing a dynamic data security over SecurityResellerFilter requires setting up a new role (click the Roles button in the Analysis Services toolbar) that uses a row filter.
A row filter defines a filter expression that evaluates which rows the role is allowed to see. To set up a row filter in the Role Manager, enter a DAX expression next to the table name. The DAX expression must be a Boolean expression that returns TRUE or FALSE. The Adventure Works role uses the following DAX expression for the row filter on the Employee table:
The LOOKUPVALUE function is used to obtain the employee key associated with employee’s Windows login which we get from the Username function. Because the row filter is set on the Reseller table, for each reseller the CONTAINS function attempts to find a match for the combination of the reseller key and the employee key. Notice the user of the RELATEDTABLE function to pass the current reseller. The net effect is that the CONTAINS function returns TRUE if there is a row in the SecurityResellerFilter table that matches the ResellerKey and EmployeeKey combination.
You can use the Analyze in Excel feature (click the Analyze in Excel button in the Analysis Services toolbar) to test the security changes. To verify that the user has access only to resellers the user is authorized to see, add the ResellerName field from the Reseller table in the Column Labels zone.
The report should show on columns only the resellers that are associated with the interactive user in the SecurityResellerFilter table.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2011-09-28 14:02:002021-02-16 03:48:17BISM Tabular Dynamic Data Security Over Bridge Table
A client complained that Reporting Services ReportViewer doesn’t render reports in Google Chrome or Apple Safari browsers. The magic property to apparently fix this issue was SizeToReportContent=”True”
Here is a link to Microsoft’s official stand on the browser support for Reporting Services. A couple of notes:
Currently Microsoft doesn’t support report rendering in Chrome but are re-visiting the browser support matrix periodically.
Report Manager doesn’t work in Safari or Firefox. Report Manager supports IE only. However, report rendering by URL or ReportViewer should work with the above change.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2011-09-27 13:52:112016-02-16 10:34:39Rendering Reports in Chrome and Safari
 MDX is the query language for multidimensional cubes. Many BI practitioners perceive MDX to have a high learning curve probably not that much for the language itself but for the multidimensional concepts you need to master before you can get something out of it. When interacting with the community, I am frequently asked to recommend a MDX book. So far, my recommendations have been
MDX is the query language for multidimensional cubes. Many BI practitioners perceive MDX to have a high learning curve probably not that much for the language itself but for the multidimensional concepts you need to master before you can get something out of it. When interacting with the community, I am frequently asked to recommend a MDX book. So far, my recommendations have been