Organizational BI vs. Personal BI
This is a blog post that I’ve been planning for a while. With the ever-increasing power of laptops and desktop computers and declining hardware prices, personal BI is on the rise. Typically, a new technology usually has a self-propelled upward spiral to a point – vendors are talking about it to clients, executives are talking about it on golf courses, consultancies are talking about it, and are rushing to fill in the void. There is a lot of money to be made with a lot of misinformation and sometimes outright lies. I’ll be quick to point out that personal BI alone is not going to fix your BI and data challenges. However, it can complement organizational BI well and open possibilities when organizational BI alone is not enough. You might find the following information interesting when you’re contemplating which way to go.
Organizational BI
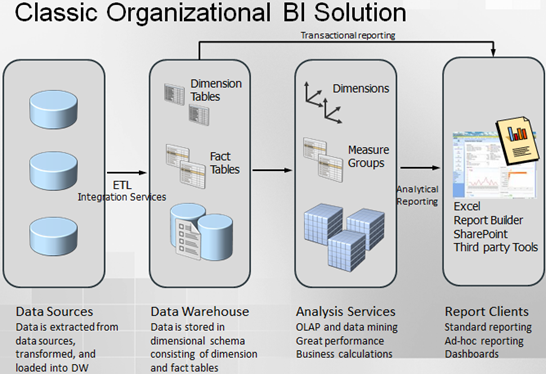
Organizational BI is a set of technologies and processes for implementing an end-to-end BI solution where the implementation effort is shifted to BI Pros. An example of a “classic” (and somewhat simplified) organizational BI solution follows.
PROS
- Pervasive business intelligence – Available to all users across the enterprise, subject to security policies.
- Single version of the truth with trusted data – Provides accurate and trusted analysis and reporting. Data is clean, validated, and secure.
- Rich feature set –OLAP, data mining, KPIs, dashboards. For more information about using Analysis Services for organizational BI, read my blog Why an Analytical Layer?
- Performance – High performance and scalability with massive data volumes
CONS
- Effort – Significant development effort might be required
- Skills – Specialized skills required (BI pros)
- More rigid – Less flexible to react to new business requirements
PERSONAL BI
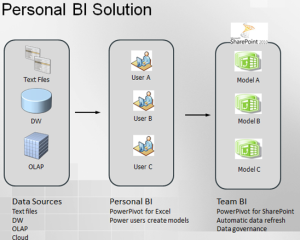
Personal BI provides business users tools for implementing ad-hoc BI models with help, guidance and supervision from IT (see below). In the Microsoft BI world, the tool for personal BI is PowerPivot with its two flavors: PowerPivot for Excel and PowerPivot for SharePoint.
PROS
- Offloads effort from IT – Anyone can implement BI models if they have access to data. However, IT must still provide ongoing guidance and supervision, such as to provide access to data, to implement more advanced business calculations, to monitor the shared environment where the BI models are deployed. Therefore, I believe more in “managed” personal BI than just personal BI.
- Knowledge domain expertise – Business users should know their domain better than IT.
- Data mashups — Easy to mix data from different data sources.
- Data exploration – Let business users explore data and tell IT what they really want before BI pros take over.
CONS
- “Spreadmarts” – Proliferation of models. Which model do you trust?
- Data integrity and validation issues – If users don’t import data that is already validated, such as importing data stored in the company’s data warehouse, reports probably cannot be trusted.
- Power users – In reality, personal BI requires power users. In my experience, regular users don’t have the desire, skills, and time to create models. A case in point – a major organization decided to embrace a popular tool for personal BI but hired a consultancy to implement the reports! Have you heard from your users that they want operational reports, preferably delivered to them via subscriptions?
- Security issues – Another burden on IT to secure data and make sure that data is not compromised when the business user imports it and share the model with another user.
So, each approach has pros and cons. Instead of exclusivity, consider using them together. For example, implement organizational BI for pervasive BI and single version of the truth, coupled with isolated scenarios for personal BI, such as when the data is not in the data warehouse or when users need to mash up data.