Microsoft announced two company acquisitions related to data analytics.
It announced that it will acquire Revolution Analytics. Revolution Analytics is the leading commercial provider of software and services for R, the world’s most widely used programming language for statistical computing and predictive analytics. This acquisition could help more companies use the power of R and data science to unlock big data insights with advanced analytics.
Previously, Microsoft also announced that it will acquire Equivio. Equivio is a provider of machine learning technologies for eDiscovery and information governance to help customers tackle the legal and compliance challenges inherent in managing large quantities of email and documents.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2015-01-25 17:00:002016-02-12 12:52:15Microsoft is Serious about Statistical Analysis and Machine Learning
Non-clustered columnstore indexes (NCCI) were introduced in SQL Server 2012 to improve the performance of large aggregate queries (common for data warehousing) with the caveat that there were read-only. Consequently, the ETL process has to drop NCCI, load the data, and recreate the columnstore index.
NOTE Building an index (columnstore or regular) should be a highly-parallel operation. Building a columnstore index in particular should max out all licensed cores. Currently, we have an open support case with Microsoft where a columnstore index allows adding a computed column (while it shouldn’t). Consequently, SQL Server builds the index using a single thread which may lead to excessive index creation times.
SQL Server 2014 introduced clustered columnstore indexes (CCI) which offer two main advantages:
CCI is updatable — Therefore, you don’t have to drop and recreate the index anymore.
Storage is greatly reduced — For example, you might have a fact table of 100 GB. Assuming x10 compression, your table space with NCCI will be 110 GB. However, if you create CCI the table space will be only 10 GB. This is why Analytics Platform System (previously known is PDW) uses CCI.
On the downside, CCI doesn’t support any other indexes that you might need to optimize ETL or speed up joins. Basically, CCI is the only index you can have on a table. However, CCI is not designed for equality and short-range queries that are typical for detail-level SELECT or MERGE queries. It’s a common misconception that you don’t need such indexes with CCI but this is not the case. I hope a future release of SQL Server enhances CCI to support regular indexes as well.
I’m presenting at the Atlanta.MDF group on Monday, January 12th. I’ll be covering a wide range of tips and techniques for analyzing and improving performance of SQL Server-based data analytics solutions. Hope you can make it.
Title: Can Your Data Analytics Solution Scale?
Abstract: Does your ETL exceed its processing window? Do your users complain about the SSRS spinny? Can your SQL Server database design deliver the expected performance? Can the system scale to thousands of users? Join this session to learn best practices and tips for isolating bottlenecks and improving the performance of data analytics solutions. I’ll dissect the layers of a “classic” solution (relational database, ETL, data model, reports) and share solutions harvested from real-life projects to address common performance-related issues.
Scenario: You execute a SQL Server 2012 task that uses parallelism, such as index rebuild or a query on a server with more than 20 cores running SQL Server 2012 Enterprise Edition. In the Windows Task Manager, you observe that the task uses only 20 cores. We discovered this scenario during a rebuild of a columnstore index. To confirm this further, you examine the SQL Server log and notice that a similar message is logged when the SQL Server instance starts:
“SQL Server detected 8 sockets with 4 cores per socket and 4 logical processors per socket, 32 total logical processors; using 20 logical processors based on SQL Server licensing. This is an informational message; no user action is required.”
Explanation: More than likely, you have upgraded to SQL Server 2012 from SQL Server 2008 R2 under Software Assurance. Microsoft created a special SKU of Enterprise Edition to support this scenario with the caveat that this SKU limits an instance to using only 20 processor cores (or 40 CPU threads if hyperthreading is enabled). If this level of parallelism is not enough, the only solution is to switch to the Enterprise Edition SKU that is licensed per core and purchase a license that covers as many cores as needed. Once you obtain the new license key, you can upgrade your SQL Server instance:
Setup.exe /q /ACTION=editionupgrade /INSTANCENAME=MSSQLSERVER /PID=<PID key for new edition>” /IACCEPTSQLSERVERLICENSETERMS
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2015-01-07 02:49:002016-02-12 14:02:58SQL Server and 20 Cores Limit
One of the biggest strengths of Microsoft self-service BI is the ability to create sophisticated data models on a par with organizational BI models built by professionals. This fact is often overlooked when organizations evaluate self-service tools and the decision is often made based on other factors but not insightful understanding of the data model capabilities. This is unfortunate because most popular tools on the market don’t go much further than supporting a single dataset. By contrast, Power Pivot allows you to import easily multiple datasets from virtually anywhere and join the resulting tables as you can do in Microsoft Access. This brings tremendous flexibility and analytical power.
Unlike multidimensional cubes, one of the limitations of the Power Pivot and Tabular data models has been the lack of support for declarative many-to-many relationships. The workaround has been using a simple DAX formula to resolve the relationship over a bridge table, such as =CALCULATE (SUM (Table[Column] ), <BridgeTable>) but this approach might present maintenance issues, as you have to create multiple calculated measures to support different slicing and dicing needs. However, as pointed out in my latest newsletter, the upcoming version of Power BI aims to remove adoption barriers and adds new features. And, one of this features, is bidirectional relationships and declarative support of M2M relationship, which Chris Webb already wrote about.
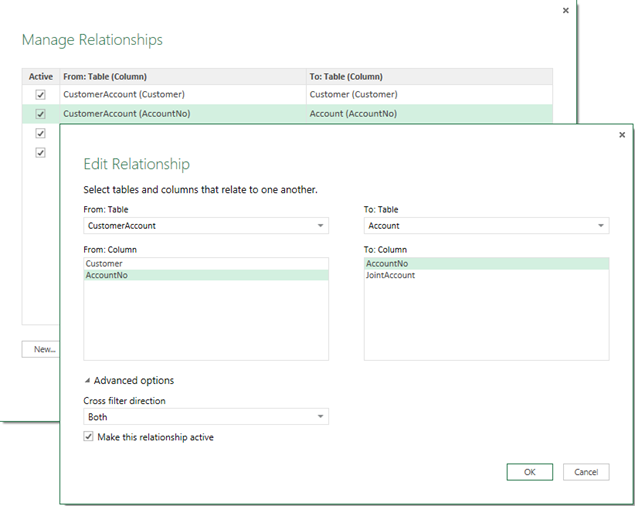
To test the M2M relationship, I attempted to create the same M2M scenario that I used in my book, which models a joint bank account. The corresponding Power Pivot schema is shown below. The CustomerAccount table is the bridge table that resolves the M2M relationship (a customer might have many accounts and a bank account might be shared by multiple customers). The Balances table stores the account balances over time and the Date table lets us analyze these balances over time.
Setting up a M2M relationship in the Power BI Designer is achieved by changing the “Cross filter direction” relationship setting to Both. This setting and bi-directional relationships are described in more details here.
Indeed, creating a report that shows balances by customer resolves the M2M relationship and aggregates correctly.
Unfortunately, attempting to slice the report by Date returns an error in the preview version of the Power BI Designer so the M2M feature is still a work in progress. Brining this further, a useful addition could be declarative semi-additive functions to allow the user to set the aggregation behavior of the Balance measure, such as to LastNonEmpty. Similar to Multidimensional, this will avoid the need for user-defined explicit measures.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2015-01-04 19:03:002021-02-16 04:58:58Tabular M2M Relationships on the Horizon
ETL exceeds the processing time window? Optimizing ETL, starts with obtaining task-level execution times? If you use SSIS 2012 project deployment mode, task-level stats are already loaded in the SSIS catalog and you can use the following query:
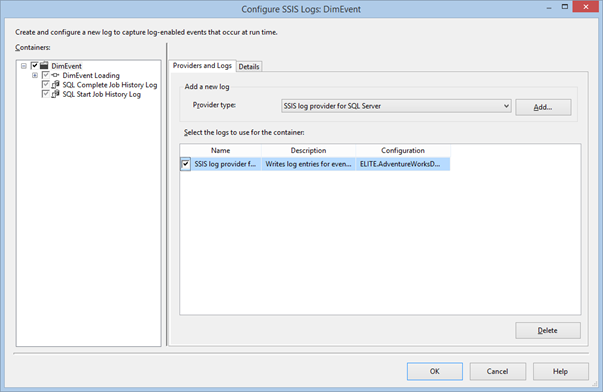
What if you are not on SSIS 2012 or later yet or you are not using the project deployment mode or a framework that logs the task duration? You can still obtain the task duration but you need to enable SSIS logging for each package you want to monitor, as follows:
Open the package in BIDS/SSDT.
On the SSIS menu, click Logging. Configure logging to use the SSIS Log Provider for SQL Server. The provider will save the statistics in a SQL Server table so you can easily query the results.
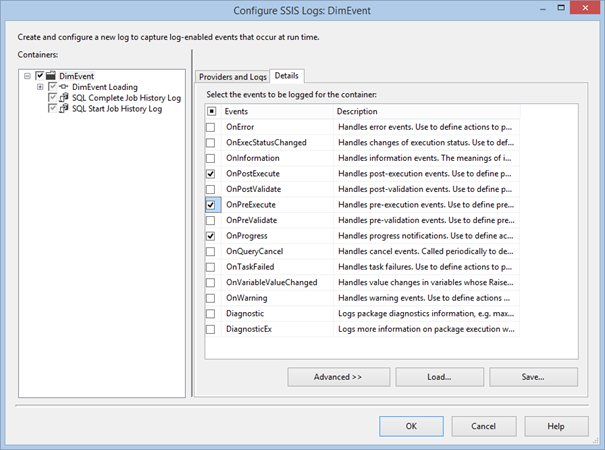
On the Details tab, select the OnPreExecute, OnPostExecute, and most importantly the OnProgress event so you can get the same level of execution statistics as in the BIDS/SSDT Progress tab.
Once you configure the SSIS Log Provider for SQL Server, it will create a sysssislog table in the database you specified when you configured the provider. When the SQL Server Agent executes your package, you can use a query like the one below to obtain task-level durations:
SELECT executionid Execution,
PackageName = ( SELECT TOP 1 source FROM dbo.sysssislog S WHERE S.executionid = L.executionid AND S.[event] = ‘PackageStart’ ),