Auditing Row Counts in SSIS
It’s a good practice to have a custom ETL framework that augment the SSIS capabilities. ETL frameworks come in different shapes and sizes but what I’d like to see in a framework is:
- Configurable parallelism – Does your ETL take hours? The chances are that your packages run sequentially. Or, disconnected flows in the master package’s control flow support limited parallelism, while your server probably has much bigger pipeline. By contrast, the framework we use support configuring the degree of parallelism and automatically distributes packages to be executed on different threads.
- Target and actual package execution duration – You must proactively monitor when the actual package execution exceeds its target duration. See my newsletter “Is ETL (E)ating (T)hou (L)ive?” of a real-life example of what could happen if you don’t do this. Plan to implement an ETL dashboard for monitoring the package execution against its target and to let the users know what date the data is current as by every source system.
- Restartability – Resume package execution from the point of failure.
- Sufficient auditing checks to ensure data quality – This is usually done by recording row counts of extracted, inserted, updated, and deleted rows. I’d also like to see ETL packages doing some quality checks to ensure the data is consistent as it moves through the pipeline (source, staging, DW, cubes).
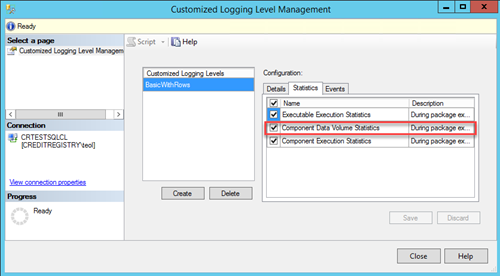
I’m currently auditing an ETL implementation where the original developers didn’t record row counts. Citing regulatory requirements, such as The Sarbanes-Oxley Act, the ETL was later”enriched” to record before and after row counts of every possible DML operation. If this is the stated business requirement, then that’s fine but before you start on this this path, consider that the SSIS catalog provides counts for data flow tasks. Before SQL Server 2016, collecting these counts would require enabling Verbose logging. This wasn’t a recommended practice because of the additional overhead. However, in SQL Server 2016 you can create a custom logging level to record only the things you need. Follow these steps to create custom logging level in order to capture row counts:
- Right-click the SSIS catalog and then click Customized Logging Level. Click the Create button and choose which of the system-defined logging levels you want to use as a base, e.g. Basic.
- To record the row counts, make sure to select Component Data Volume Statistics in the Statistics tab.
- When configure your job with SQL Server Agent, go to the Configuration tab, click the Advanced Tab, and then select the custom logging level you created in the “Logging level” drop-down.
Because the row counts are recorded for each buffer in the data flow task, in SSMS connect to the SSISDB database and execute this query to group by package, task, and component to see how many rows has gone through each component over time:
SELECT package_name, task_name, [source_component_name] , max(created_time) as created_time, SUM([rows_sent]) AS rows_sent
FROM [catalog].[execution_data_statistics]
GROUP BY package_name, task_name, [source_component_name]
order by 4
As useful as this is, it captures only the row counts in data flow tasks. It won’t record DML operations that are taking place in the Control Flow, such as in Execute SQL Tasks that are calling stored procedures. If capturing row counts in Control Flow is required, you have to do so on your own.
It’s unlikely that capturing row counts alone would satisfy stringent auditing requirements, such as when was the row changed, what change was made and what was the old values. Instead, consider using another feature introduced in SQL Server 2016 Database Engine: temporal tables. By configuring your destination tables as temporal, you let SQL Server to capture data changes in a history table. Now you have a rich audit trail.