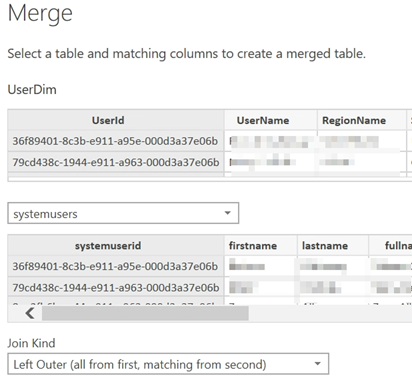
Scenario: You are merging two tables in Power Query on GUID columns with Text data type. In my case, the first table (UserDim) came from Azure SQL DB and the second (systemusers) from Dynamics CRM, but I believe the source is irrelevant. Then, you expand the second table in the next step after the merge, select the columns you need, and see expected results in the preview pane. However, when you apply the changes, the related columns are not populated (empty) in the Power BI data model. In other words, the join fails to find matches.
Solution: I think there is some sort of a bug in Power Query. True, Power Query is case-sensitive so joining on the same text that differs in casing in the two columns would fail the match. However, in this case the guids were all lower case (or at least that’s how they appear in the preview). The only way I could explain the issue is that the refresh somehow converts the guid values to different casing before the join is performed. Anyhow, the problem was solved by adding an explicit step to convert both guid columns to lower case before the merge step.
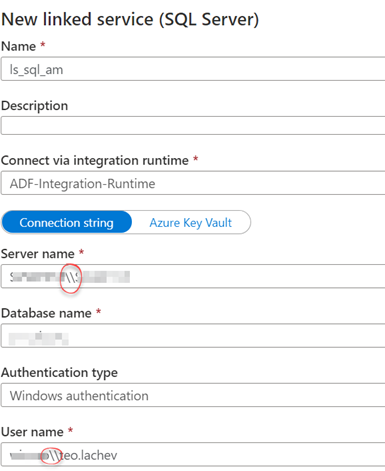
You’ve set up the Azure Data Factory self-hosted integration runtime to access on-prem data sources. You create a linked server, click Test Connection, and then get greeted with an error saying the security context can’t be passed. On the on-prem VM, you use the Integration Runtime Configuration Manager and get a similar error or something to the extent that JSON can’t be parsed. You spent a few hours in trying everything that comes to mind, such as checking firewalls, connectivity from SSMS, but nothing helps.
How do we fix this horrible problem? We double the backslashes in the server name (if you use a named instance) and in the user name (after the domain) on the linked server properties. Apparently, Spark/Databricks has an issue with backslashes.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-10-02 16:05:322020-10-02 16:05:32Solving Configuration Errors with ADF Self-hosted IR
Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, October 5th, at 6:30 PM. Paco Gonzalez (CEO of SolidQ) will present and demonstrate the Power BI AI and ML capabilities. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Perhaps some of the most powerful features of Power BI involve the Artificial Intelligence and Machine Learning functionality built into the platform. In this session, we will review the AI and ML capabilities built into Power BI Desktop and the Power BI Service. From Data Visualizations to Data Preparation and Data Modeling, we will discuss the various ways that AI and ML can be easily implemented in your reporting.
Speaker:
Paco Gonzalez is the CEO of SolidQ North America, and a Microsoft Data Platform MVP. Focused on Business Analytics and Artificial Intelligence, he specializes in helping organizations become data driven from a strategic and technical perspective. Paco is a speaker at small and large conferences such as PASS Summit, Ignite, and Business Applications Summit, and he has published several books and whitepapers. He is based in Atlanta, GA.
Prototypes without pizza:
Power BI latest features
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-09-29 21:05:302021-02-17 01:01:42Atlanta MS BI and Power BI Group Meeting on October 5th
Cloud deployments are the norm nowadays for new software projects, including BI. And Azure Synapse Analytics shows a great potential for modern cloud-based data analytics platform. Here are some high-level pros and cons to keep in mind for implementing Azure Synapse-centered solutions that I harvested from my real-life projects and workshops.
What’s to Like
There is plenty to like in Azure Synapse which is the evaluation of Azure SQL DW. If you’re tasked to implement a cloud-based data warehouse, you might be evaluating three Azure SQL Server-based PaaS offerings: Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse. However, Azure SQL Database and Azure SQL MI are optimized for OLTP workloads. For example, they have full logging enabled and replicate each transaction across replicas. Full logging is usually a no-no for decent size DW workloads because of the massive ETL changes involved.
In addition, to achieve good performance, you’ll find yourself moving up the performance tiers and toward the price point of the lower Azure Synapse SKUs. Further, unlike Azure SQL Database, Azure Synapse can be paused, such as when reports hit a semantic layer instead of DW, and this may offer additional cost cutting options.
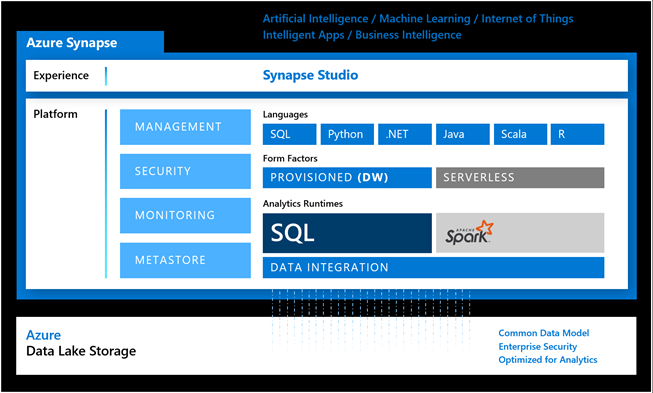
To get started with Synapse, you need to create a workspace. A workspace can host two analytics runtimes, SQL and Spark. These runtimes are hosted in pools. For example, you might have one pool Pool for your enterprise data warehouse, and other SQL pool for a departmental data mart, all provisioned within the same workspace.
A SQL Pool (previously known as Azure SQL DW) hosts your SQL relational database. As an MPP system, it can scale to petabytes of data with proper sizing and good design. The obvious benefit is that for the most part (see the Ugly section discussing exclusions) you can carry your SQL Server skills to Azure Synapse.
As a general rule of thumb, Azure Synapse should be at the forefront of your modern cloud DW with data loads starting with 500 GB.
I like the integration with Azure Data Lake Storage (ADLS). Previously, you had to set up external tables to access files in ADLS via PolyBase. This is might redundant now thanks to the serverless (on-demand) endpoint which also replaces the Gen1 U-SQL with T-SQL. All you have to do is link your ADLS storage accounts and use the T-SQL OPENROWSET construct to query your ADLS files and exposed them as SQL datasets. Not only does this opens new opportunities for ad hoc reporting directly on top of the data lake, but it also can help you save tons of ETL effort to avoid staging the ADLS data while loading your DW.
As the diagram shows, you can also provision an Azure Spark runtime under a Synapse workspace. This opens the possibility for using Azure Spark/Databricks for data transformation and data science. For example, a data scientist can create notebooks in Synapse Studio that use a programming language of their choice (SQL, Python, .NET, Java, Scala, and R are currently supported).
What Needs Improvement
You have two coding options to implement artifacts for Azure Synapse, such as ETL and reports:
You can use the respective development environment, such as Azure Data Factory Studio for ADF development and Power BI Desktop for Power BI report development.
You can use Synapse Studio which attempts to centralize coding in one place.
Besides the ADLS integration and notebooks, I find no advantages in the Synapse Studio “unified experience”, which is currently in preview. In fact, I found it confusing and limiting. The idea here is to offer an online development environment for coding and accessing in one place all artifacts surrounding your DW project. Currently, these are limited to T-SQL scripts, notebooks, Azure Data Factory pipelines, and Power BI datasets and reports. However, I see no good reason to abandon the ADF Studio and do ETL coding in Synapse Studio. In fact, I can only see reasons against doing so. For example, Synapse Studio lags in ADF features, such as source code integration and wrangling workflows. For some obscure reason, Synapse Studio separates data flows from ADF pipelines in its own Data Flows section in the Development Hub. This is like putting the SSIS data flow outside the package. Not to mention that inline data flows should be deemphasized since ELT (not ETL) is the preferred pattern for loading Azure Synapse. To make things worse, once you decide to embrace Synapse Studio for developing ADF artifacts, you can use only Synapse Studio because the ADF pipelines are not available outside Synapse.
On the Power BI side of things, you can create a Power BI dataset in Synapse Studio. All this saves is the effort to go through two Get Data steps in Power BI Desktop to connect to your Azure Synapse endpoint. You can also create Power BI reports using Power BI Embedded in Azure Synapse. Why would I do this outside Power BI Desktop is beyond me. Perhaps, I’m missing the big picture and more features might be coming as Synapse evolves. Speaking of evolution, as of this time, only SQL pools are generally available. Everything else is in preview.
What’s Not to Like
Developers moving from on-prem BI implementations to Azure Synapse, would naturally expect all SQL Server features to be supported, just like moving from on-prem SSAS to Azure AS. However, they will quickly find that Azure Synapse is “one of a kind” SQL Server. The nice user interface in SSMS for carrying out admin tasks, such as creating logins and assigning logins to roles, doesn’t work with Azure Synapse (all changes require T-SQL). SQL Profiler doesn’t work (tip: use the Profiler extension in Azure Data Studio for tracing queries in real time).
Because Azure Synapse uses Azure SQL Database, it’s limited to one physical database, so you must rely on using schemas to separate your staging and DW tables. There are also T-SQL limitations, such as my favorite MERGE for ELT-based UPSERTs is not yet supported (currently in preview for hash and round-robin distributed tables but not for replicated tables, such as dimension tables). So, don’t assume that you can seamlessly migrate your on-prem DW databases to Synapse. Also, don’t assume that your SQL Server knowledge will suffice. Prepare to seriously study Azure Synapse!
Teo Lachev
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
I am delivering a data governance assessment for an enterprise client. As a part of the effort to migrate reporting from MicroStrategy to Power BI, the client wants to improve data analytics. The gap analysis interviews with the business leaders revealed common pitfalls: no single version of truth, data is hard to come by, business users don’t know what data sources exist, business users spend more time in data wrangling than analytics, data quality is bad, IT is overwhelmed with report requests, report proliferation and duplication, and so on…
Sounds familiar? As I mentioned many times in my blog, an enterprise data warehouse (EDW) plays a critical role in overcoming the above challenges, but it’s not enough. A semantic model is needed and I extolled its virtues in my “Why Semantic Layer?” newsletter. In the Microsoft BI world, Analysis Services Tabular is commonly used to implement such models that are typically layered on top of EDW . In general, there are two ways to approach the model implementation:
(Self-service BI path) Business users create self-service semantic models using Power BI Desktop. Behind the scenes, Power BI creates databases hosted in the Analysis Services Tabular server from the *.pbix files.
(Organizational BI path) BI developers implement organizational semantic models.
Since both implementation paths lead to the same technology, it boils down to ownership, vision, and purpose.
Because IT is overwhelmed, the temptation is to transfer the semantic model development to business users. The issue with this approach is business users seldom have the skills, time, and vision to do so. And the end, mini “semantic models” (“spreadmarts”) are produced and the same problems are perpetuated.
In most cases, my recommendation is for IT to own the semantic model because they own the data warehouse and the “Discipline at the Core” vision. And yes, unless operational and security requirements dictate otherwise, it should strive for a single centralized semantic model that spans all subject areas. If the technology you use for semantic modeling can’t deliver acceptable performance with large models, then it’s time to change it.
Of course, not all data exists or will exist in EDW. This is where self-service “Flexibility at the Edge” comes in. I have high expectations for the forthcoming “Composite models over Power BI datasets and Azure Analysis Services” mega feature (public preview expected in November 2020). This will enable the following scenario that Power BI cannot deliver today:
Business user starts by connecting live to corporate data in the organizational semantic model. Every new report requirement should start with evaluating if all or some of the data is in the semantic model, and if so, instructing the user to connect to the semantic model to avoid data modeling and data duplication.
Business user wants to mash up this data with some data that is not in EDW by retaining the live connection to the organizational semantic model and importing (or connective live with DirectQuery) to other datasets.
My wife and I started section hiking the Appalachian Trail during weekends to escape the summer heat and the virus. A.T. runs for 2,200 miles from Georgia to Maine, with 78.6 miles in Georgia. Today we finished the Georgia part and entered North Carolina. We actually covered twice the distance (averaging 10-12 miles per section) because we had to come back each time to where we parked. We started hiking with the great Atlanta Outdoor Club back in February, 2020. But when the virus hit, group hikes were put on hold, so we were left to our own devices.
Hiking somehow grew on me. Perhaps, because it as a metaphor for life. There are ups and downs. Some sections are hard and require a great deal of effort and perspiration, while others are easy. There are exhilarating views but there are also areas with overgrown vegetation. Perceived risks, such as wild animals (note the bear spray on my belt ), are lurking in the distance. Some people tell you that you’re crazy. The climate is unpredictable, and planning is sometimes futile (we got ourselves in a really bad thunder storm and downpour once while the weather was supposed to be OK). But for the most part, it is just putting one foot in front of the other. It’s about the journey, not the destination. And the more you put in, the more you’ll get out.
Kudos to the wonderful people who maintain the A.T. and those who supported us with advice! Kudos to these brave thru-hikers that cover the whole distance. I’m really jealous…one day maybe.
Cloud deployments are the norm nowadays for new software projects, including BI. And Azure Synapse shows a great potential for modern cloud-based data analytics. Here are some high-level pros and cons to keep in mind for implementing Azure Synapse-centered solutions that I harvested from my real-life projects and workshops.
The Good
There is plenty to like in Azure Synapse which is the evaluation of Azure SQL DW. If you’re tasked to implement a cloud-based data warehouse, you have a choice among three Azure SQL Server-based PaaS offerings, including Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse. In a nutshell, Azure SQL Database and Azure SQL MI are optimized for OLTP workloads. For example, they have full logging enabled and replicate each transaction across replicas. Full logging is usually a no-no for decent size DW workloads because of the massive ETL changes involved.
In addition, to achieve good performance, you’ll find yourself moving up the performance tiers and toward the price point of the lower Azure Synapse SKUs. Further, unlike Azure SQL Database, Azure Synapse can be paused, such as when reports hit a semantic layer instead of DW, and this may offer additional cost cutting options.
At the heart of Azure Synapse is the SQL Pool (previously known as Azure SQL DW) which hosts your DW. As an MPP system, it can scale to petabytes of data with proper sizing and good design. The obvious benefit is that for the most part (see the Ugly section discussing exclusions) you can carry your SQL Server skills to Azure Synapse.
As a general rule of thumb, Azure Synapse should be at the forefront of your modern cloud DW with data loads starting with 500 GB.
I liked the integration with Azure Data Lake Storage (ADLS). Previously, you had to set up external tables to access files in ADLS via PolyBase. This is now unnecessary thanks to the serverless (on-demand) endpoint which also replaces the Gen1 U-SQL with T-SQL. All you have to do is link your ADLS storage accounts and use the T-SQL OPENROWSET construct to query your ADLS files and exposed them as SQL datasets. Not only does this opens new opportunities for ad hoc reporting directly on top of the data lake, but it also can help you save tons of ETL effort to avoid staging the ADLS data while loading your DW.
As the diagram shows, you can also provision an Azure Spark runtime under a Synapse workspace. This opens the possibility for using Azure Spark/Databricks for data transformation and data science. For example, a data scientist can create notebooks in Synapse Studio that use a programming language of their choice (SQL, Python, .NET, Java, Scala, and R are currently supported).
The Bad
You have two coding options with Synapse.
You can use the respective development environment, such as Azure Data Factory Studio for ADF development and Power BI Desktop for Power BI report development.
You can use Synapse Studio which attempts to centralize coding in one place.
Besides the ADLS integration and notebooks, I find no advantages in the Synapse Studio “unified experience”, which is currently in preview. In fact, I found it confusing and limiting. The idea here is to offer an online development environment for coding and accessing in one place all artifacts surrounding your DW project. Currently, these are limited to T-SQL scripts, notebooks, Azure Data Factory pipelines, and Power BI datasets and reports.
However, I see no good reason to abandon the ADF Studio and do ETL coding in Synapse Studio. In fact, I can only see reasons against doing so. For example, Synapse Studio lags in ADF features, such as source code integration and wrangling workflows. For some obscure reason, Synapse Studio separates data flows from ADF pipelines in its own Data Flows section in the Development Hub. This is like putting the SSIS data flow outside the package. Not to mention that inline data flows should be deemphasized since ELT (not ETL) is the preferred pattern for loading Azure Synapse. To make things worse, once you decide to embrace Synapse Studio for developing ADF artifacts, you can use only Synapse Studio because the ADF pipelines are not available outside Synapse.
On the Power BI side of things, you can create a Power BI dataset in Synapse Studio. All this saves is the effort to go through two Get Data steps in Power BI Desktop to connect to your Azure Synapse endpoint. You can also create Power BI reports using Power BI Embedded in Azure Synapse. Why would I do this outside Power BI Desktop is beyond me. Perhaps, I’m missing the big picture and more features might be coming as Synapse evolves. Speaking of evolution, as of this time, only SQL pools are generally available. Everything else is in preview.
The Ugly
Developers moving from on-prem BI implementations to Azure Synapse, would naturally expect all SQL Server features to be supported, just like moving from on-prem SSAS to Azure AS. However, they will quickly find that Azure Synapse is “one of a kind” SQL Server. The nice user interface in SSMS for carrying out admin tasks, such as creating logins and assigning logins to roles, doesn’t work with Azure Synapse (all changes require T-SQL). SQL Profiler doesn’t work (tip: use the Profiler extension in Azure Data Studio for tracing queries in real time).
Because Azure Synapse uses Azure SQL Database, it’s limited to one physical database, so you must rely on using schemas to separate your staging and DW tables. There are also T-SQL limitations, such as my favorite MERGE for ELT-based UPSERTs is not yet supported (currently in preview for hash and round-robin distributed tables but not for replicated tables, such as dimension tables). So, don’t assume that you can seamlessly migrate your on-prem DW databases to Synapse. Also, don’t assume that your SQL Server knowledge will suffice. Prepare to seriously study Azure Synapse!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-08-23 12:48:212020-08-25 11:01:52Azure Synapse: The Good, The Bad, and The Ugly
I had an integration challenge recently. I set up Azure Data Lake Storage for a client and one of their customers want to use Python to automate the file upload from MacOS (yep, it must be Mac). They found the command line azcopy not to be automatable enough. So, I whipped the following Python code out. I configured service principal authentication to restrict access to a specific blob container instead of using Shared Access Policies which require PowerShell configuration with Gen 2. The comments below should be sufficient to understand the code.
# upgrade or install pywin32 to build 282 to avoid error “DLL load failed: %1 is not a valid Win32 application” while importing azure.identity
# pip install pywin32 –upgrade
# IMPORTANT! set the four environment (bash) variables as per https://docs.microsoft.com/en-us/azure/developer/python/configure-local-development-environment?tabs=cmd
# Note that AZURE_SUBSCRIPTION_ID is enclosed with double quotes while the rest are not
import os
from azure.storage.blob import BlobClient
from azure.identity import DefaultAzureCredential
storage_url = “https://mmadls01.blob.core.windows.net” # mmadls01 is the storage account name
credential = DefaultAzureCredential() # This will look up env variables to determine the auth mechanism. In this case, it will use service principal authentication
# Create the client object using the storage URL and the credential
blob_client = BlobClient(storage_url, container_name=“maintenance/in”, blob_name=“sample-blob.txt”, credential=credential) # “maintenance” is the container, “in” is a folder in that container
# Open a local file and upload its contents to Blob Storage
withopen(“./sample-source.txt”, “rb”) as data:
blob_client.upload_blob(data)
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-08-13 13:50:522020-08-13 13:50:52Uploading Files to ADLS Gen2 with Python and Service Principal Authentication
In partnership with Microsoft, I’m delivering a complimentary, one-day, Analytics in a Day virtual workshop on August 20th, 9 AM – 5 PM Eastern Time. Targeting BI developers, architects and technology decision makers interested in achieving a single version of truth with organizational BI, this workshop is designed to guide and accelerate your journey towards a modern data warehouse to power your business with Azure Synapse, Azure Data Factory, Azure Data Lake, and Power BI.
The first half of the day from 9 am – 1 pm will help you better understand how to:
Create an analytics solution that goes from data ingestion to insights using Azure Synapse Analytics and Power BI
Empower self-service analytics
Enable a truly data-driven culture in your business
Part of the workshop will be dedicated to hands-on training to help you get started on your cloud analytics journey.
The second half of the day from 1 pm – 5 pm is optional and will focus on best practices around designing Power BI + Azure Synapse Analytics BI solutions to enable “Discipline at the core and flexibility at the edge“.
Say goodbye to data silos. Analytics in a Day is designed to simplify and accelerate your journey towards a modern data warehouse to power your business. Reserve your seat today at http://bit.ly/aid202008.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-08-11 14:49:432020-08-11 14:49:43Presenting Analytics in a Day Workshop on August 20th
I’m preparing to teach the brand new Analytics in a Day course by Microsoft. This course emphasizes the business value and technical fundamentals for implementing a modern cloud DW using Azure Synapse, ADF, Data Lake, and Power BI. The second half of the class is focused on Power BI and its role for creating organizational semantic models and self-service models from Synapse. I liked the best practices that Microsoft shares based on how they’ve adopted BI over years and challenges they faced with self-service BI, including:
Inconsistent data definitions, hierarchies, metrics, KPIs
Analysts spending 75% of their time collection and compiling data
78% of reports being creating in “offline environments”
Over 350 centralized finance tools and systems
Approximately $30M annual spend on “shadow applications”
Indeed, many vendors tout only self-service BI which can quickly lead to chaos. By contrast, I have found that most successful data-driven organizations have both organizational and self-service BI.
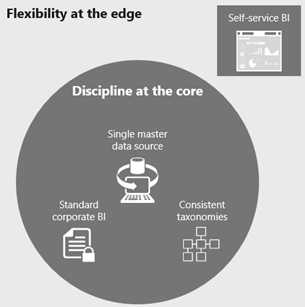
Microsoft calls the collection of these best practices “Discipline at the Core, Flexibility at the Edge“.
“Discipline at the Core” is organizational BI where IT retains control to:
Deliver standardized and performant corporate BI (single version of truth)
Define consistent taxonomies, hierarchies, and KPIs
Enforce data permissions centrally.
“Flexibility at the Edge” is self-service BI where data analysts:
Quickly create reports sourced from trusted data
Mashup core data with departmental data
Create new metrics and KPIs relevant to their part of the business
I further recommend the 80/20 rule as a rough guideline, where most of the effort (as much as 80%) goes into integration and curating the data, implementing enterprise models, and enforcing security, and 20% is left for the agility of self-service BI.
Is your organization disciplined at the core, or is the core missing as a result of blind adherence to the self-service BI mantra?
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-08-06 12:02:122020-08-06 14:04:19Discipline at the Core, Flexibility at the Edge