Atlanta BI fans, please join us in person for the next meeting on Monday, July 1st at 6:30 PM ET. John Kerski (Microsoft MVP) will shows us how to integrate ChatGPT with Power BI. Your humble correspondent will help you catch up on Microsoft BI latest. CloudStaff.ai will sponsor the event. For more details and sign up, visit our group page.
Details
Presentation: Commenting Power Query with Azure OpenAI Delivery: In-person Date: July 1, 2024 Time: 18:30 – 20:30 ET Level: Intermediate Food: Pizza and drinks will be provided
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Venue
Improving Office
11675 Rainwater Dr
Suite #100
Alpharetta, GA 30009
Overview: Large Language Models (such as ChatGPT) can greatly enhance the way you develop and deliver Power BI solutions. In this session I will show you how to integrate Azure Open AI into Power BI using prompt engineering techniques.
Speaker: John Kerski has over a decade of experience in technical and government leadership. He specializes in managing Data Analytics projects and implementing DataOps principles to enhance solution delivery and minimize errors. John’s expertise is showcased through his ability to offer patterns and templates that streamline the adoption of DataOps with Microsoft Fabric and Power BI. His in-depth knowledge and hands-on approach provide clients with practical tools to achieve efficient and effective data operations.
Sponsor: CloudStaff.ai
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-06-25 11:14:362024-06-25 11:14:36Atlanta Microsoft BI Group Meeting on July 1st (Commenting Power Query with Azure OpenAI)
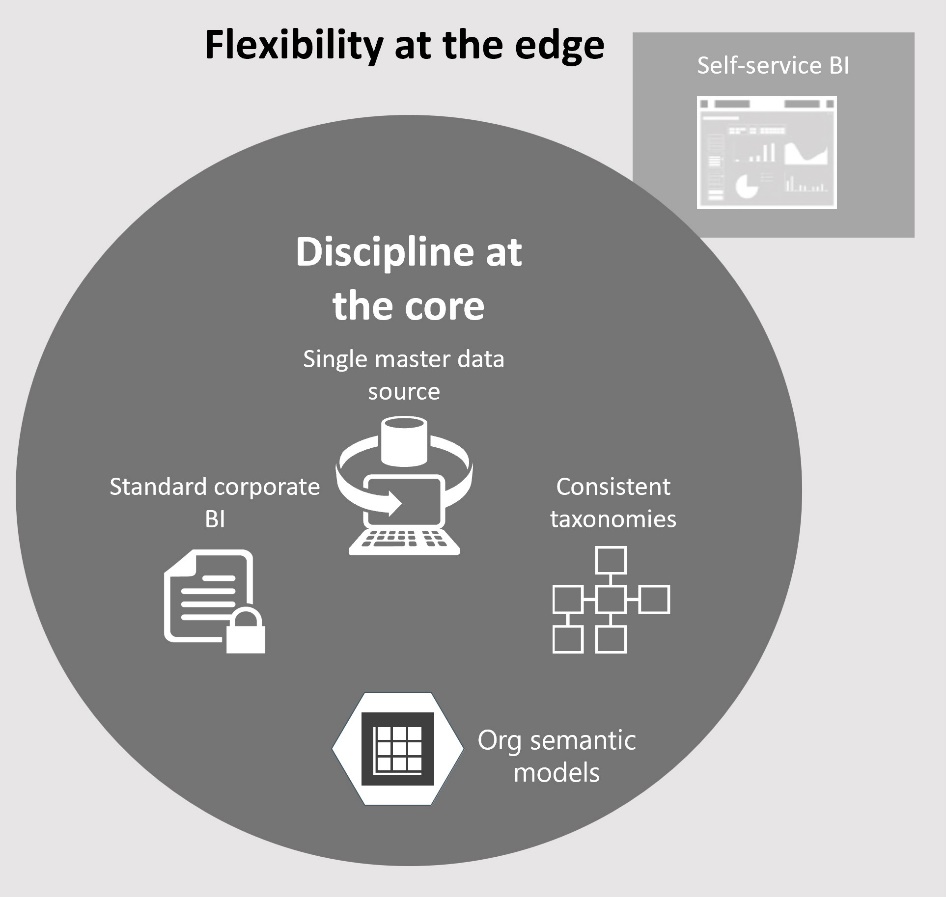
I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “Are you modern yet?” and “Data Lakehouse: The Good, the Bad, and the Ugly”) but a recent assessment inspired to me write about this topic again. This newsletter advocates a hybrid and cautionary approach for data integration to avoid overdoing data lakes and warns about pitfalls of over-staging source data to files. It recommends instead following the “Discipline at the core, flexibility at the edge” methodology with emphasis on implementing enterprise data warehouse and organizational semantic models.
Data Lake Overstaging
How did the large vendor attempt to solve these horrible issues? Modern Data Warehouse (MDM) architecture of course. Nothing wrong with it except that EDW and organizational semantic model(s) are missing and that most of the effort went into implementing the data lake medallion architecture where all the incoming data ended up staged as Parquet files. It didn’t matter that 99% of the data came from relational databases. Further, to solve a data change tracking requirement, the vendor decided to create a new file each time ETL runs. So even if nothing has changed in the source feed, the data is duplicated should one day the user wants to go back in time and see what the data looked like then. There are of course better ways to handle this that doesn’t even require ETL, such as SQL Server temporal tables, but I digress.
At least some cool heads prevailed and the Silver layer got implemented as a relational ODS to serve the needs of home-grown applications, so the apps didn’t have to deal with files. What about EDW and organizational semantic models? Not there because the project ran out of budget and time. I bet if that vendor got hired today, they would have gone straight for Fabric Lakehouse and Fabric premium pricing (nowadays Microsoft treats partners as an extension to its salesforce and requires them to meet certain revenue targets as I explain in “Dissolving Partnerships“), which alone would have produced the same outcome.
What did the vendor accomplish? Not much. Nor only didn’t the implementation address the main challenges, but it introduced new, such as overcomplicated ETL and redundant data staging. Although there might be good reasons for file staging (see the second blog above), in most cases I consider it a lunacy to stage perfect relational data to files, along the way losing metadata, complicating ETL, ending up serverless, and then reloading the same data into a relational database (ODS in this case).
I’ve heard that the vendor justified the lake effort by empowering data scientists to do ML one day. I’d argue that if that day ever comes, the likelihood (pun not intended) of data scientists working directly on the source schema would be infinitely small since more than likely they would require the input datasets to be shaped in a different way which would probably require another ETL pipeline altogether.
Better Data Staging
I don’t subject my clients to excessive file staging. My file staging litmus test is what’s the source data format. If I can connect to a server and get in a tabular (relational) format, I stage it directly to a relational database (ODS or DW). However, if it’s provided as files (downloaded or pushed, reference data, or unstructured data), then obviously there is no other way. That’s why we have lakes.
Fast forward a few years, and your humble correspondent got hired to assess the damage and come up with a strategy. Data lakes won’t do it. Lakehouses and Delta Parquet (a poor attempt to recreate and replace relational databases) won’t do it. Fabric won’t do it and it’s too bad that Microsoft pushes Lakehouse while the main focus should have been on Fabric Data Warehouse, which unfortunately is not ready for prime time (fortunately, we have plenty of other options).
What will do it? Going back to the basics and embracing the “Discipline at the core, flexibility at edge” ideology (kudos to Microsoft for publishing their lessons learned). From a technology standpoint, the critical pieces are EDW and organizational semantic models. If you don’t have these, I’m sorry but you are not modern yet. In fact, you aren’t even classic, considering that they have been around for long, long time.
Just passed DP-600 and therefore I’m officially a Fabric Analytics Engineer. Besides renewals, I intend this to be my last Microsoft certification. After more than 30 years of certifying (12 certifications and 30 exams) and helping other certify with training and books, I think it’s time to close this chapter. Call me certifiable…
“Where are the prophets, where are the visionaries, where are the poets To breach the dawn of the sentimental mercenary” “Fugazi”, Marillion
I’ve written in the past about the dangers of blindly following “modern” data architectures (see my posts “Are you modern yet?” and “Data Lakehouse: The Good, the Bad, and the Ugly”) but here we go again. Once upon a time, a large company hired a large Microsoft partner to solve a common and pervasive challenge. Left on their own, departments have set up their own data servers, thus creating data silos leading to data duplication and inconsistent results.
How did the large vendor attempt to solve these horrible issues? Modern Data Warehouse (MDM) architecture of course. Nothing wrong with it except that EDW and organizational semantic model(s) are missing and that most of the effort went into implementing the data lake medallion architecture where all the incoming data ended up staged as Parquet files. It didn’t matter that 99% of the data came from relational databases. Further, to solve a data change tracking requirement, the vendor decided to create a new file each time ETL runs. So even if nothing has changed in the source feed, the data is duplicated should one day the user wants to go back in time and see what the data looked like then. There are of course better ways to handle this that doesn’t even require ETL, such as SQL Server temporal tables, but I digress.
At least some cool heads prevailed and the Silver layer got implemented as a relational ODS to serve the needs of home-grown applications, so the apps didn’t have to deal with files. What about EDW and organizational semantic models? Not there because the project ran out of budget and time. I bet if that vendor got hired today, they would have gone straight for Fabric Lakehouse and Fabric premium pricing (nowadays Microsoft treats partners as an extension to its salesforce and requires them to meet certain revenue targets as I explain in “Dissolving Partnerships“), which alone would have produced the same outcome.
What did the vendor accomplish? Not much. Nor only didn’t the implementation address the main challenges, but it introduced new, such as overcomplicated ETL and redundant data staging. Although there might be good reasons for file staging (see the second blog above), in most cases I consider it a lunacy to stage perfect relational data to files, along the way losing metadata, complicating ETL, ending up serverless, and then reloading the same data into a relational database (ODS in this case).
I’ve heard that the vendor justified the lake effort by empowering data scientists to do ML one day. I’d argue that if that day ever comes, the likelihood (pun not intended) of data scientists working directly on the source schema would be infinitely small since more than likely they would require the input datasets to be shaped in a different way which would probably require another ETL pipeline altogether.
I don’t subject my clients to excessive file staging. My file staging litmus test is what’s the source data format. If I can connect to a server and get in a tabular (relational) format, I stage it directly to a relational database (ODS or DW). However, if it’s provided as files (downloaded or pushed, reference data, or unstructured data), then obviously there is no other way. That’s why we have lakes.
Fast forward a few years, and your humble correspondent got hired to assess the damage and come up with remediation. Data lakes won’t do it. Lakehouses and Delta Parquet (a poor attempt to recreate and replace relational databases) won’t do it. Fabric won’t do it and it’s too bad that Microsoft pushes Lakehouse while the main focus should be Fabric Data Warehouse, which unfortunately is not ready for prime time (but we have plenty of other options).
What will do it? Going back to the basics and embracing the “Discipline at the core, flexibility at edge” ideology (kudos to Microsoft for publishing their lessons learned). From a technology standpoint, the critical pieces are EDW and organizational semantic models. If you don’t have these, I’m sorry but you are not modern yet. In fact, you aren’t even classic, considering that they have been around for long, long time.
So, keep on implementing these medallion lakes to keep my consulting pipeline full. Drop a comment how they work for you.

 I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “
I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “