Atlanta Microsoft BI Group Meeting on October 9th (Everything You Want to Know About SQL Databases in Fabric)
Atlanta BI fans, please join us in person for our next meeting on Thursday, October 9th (note that we are meeting on Thursday for this meeting) at 18:30 ET. Sukhwant (Senior Product Manager, Microsoft) will explain why you should consider Fabric SQL databases. And your humble correspondent will walk you through some of the latest Power BI and Fabric enhancements. For more details and sign up, visit our group page.
Delivery: In-person
Level: Intermediate
Food: Pizza and drinks will be provided
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (news, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Overview: Microsoft Fabric is an all-in-one analytics platform, right? Wrong! With the introduction of SQL databases last year, we now have an all-in-one data platform. During this session you will hear directly from the product team about why we added SQL databases to Fabric, who should be using them, how this is different from Azure SQL databases, how to get started through an end-to-end demo, and the integration story with the rest of the platform.
If you’re a DBA that’s been trying to move applications for running SQL or a business user with limited database skills and no DBAs to be found, you’ll want to hear all about this exciting new offering that is simple, automated, and optimized for AI.
Speaker: Sukhwant has served as a Product Manager at Microsoft for the past few development cycles. During this time, she’s focused on the entire product management lifecycle, from working with development teams and user experience to collaborating with cross-functional teams to drive customer satisfaction in ensuring our products not only meet but exceed customer expectations.
Before joining Microsoft, she held various full-time/contracting roles as a technology leader for over two decades in software lifecycle development, system integration and enterprise architecture design. Her expertise extends to Data Strategy, Analytics, and Web Content Management. Throughout her career, she has successfully led numerous projects, both small and large, from inception through to implementation. She is a proponent of the servant-leader philosophy, which aims to continuously improve and empower those she works with.
Sponsor: At CloudStaff.ai, we’re making work MORE. HUMAN. We believe in the power of technology to enhance human potential, not replace it. Our innovative AI and automation solutions are designed to make work easier, more efficient, and more meaningful. We help businesses of all sizes streamline their operations, boost productivity, and solve real-world challenges. Our approach combines cutting-edge technology with a deep understanding of human needs, creating solutions that work the way people do! https://cloudstaff.ai

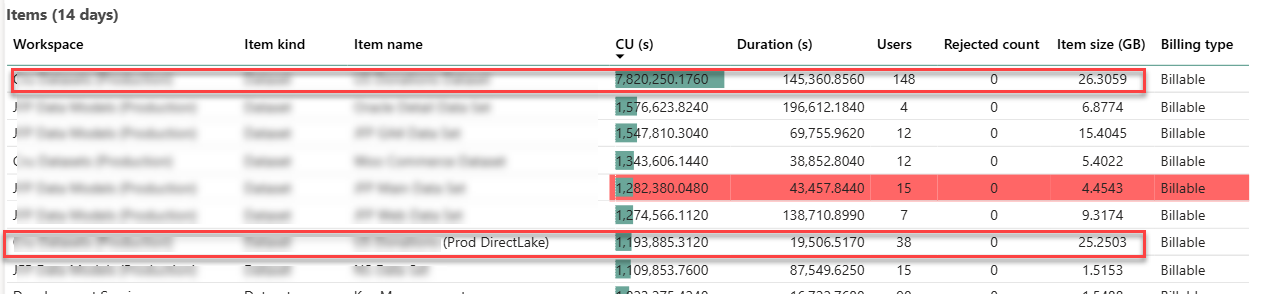
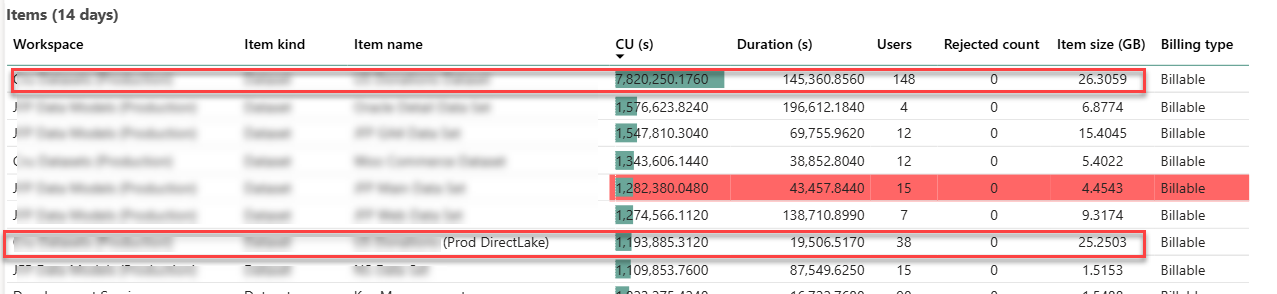
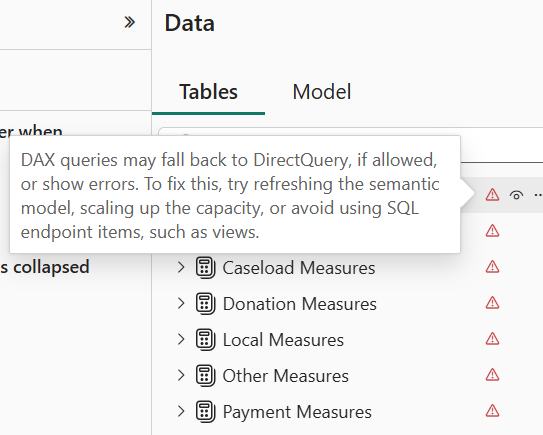
 Like the Ancient Greek philosopher Diogenes, who walked the streets of Athens with a lamp to find one honest man, I have been searching for a convincing Fabric feature for my clients. As Microsoft Fabric evolves, more scenarios unfold. For example, Direct Lake storage mode could help you alleviate memory pressure with large semantic models in certain scenarios, as it did for one client. This newsletter summarizes the important takeaways from this project. If this sounds interesting and you are geographically close to Atlanta, I invite you to the December 1st meeting of the
Like the Ancient Greek philosopher Diogenes, who walked the streets of Athens with a lamp to find one honest man, I have been searching for a convincing Fabric feature for my clients. As Microsoft Fabric evolves, more scenarios unfold. For example, Direct Lake storage mode could help you alleviate memory pressure with large semantic models in certain scenarios, as it did for one client. This newsletter summarizes the important takeaways from this project. If this sounds interesting and you are geographically close to Atlanta, I invite you to the December 1st meeting of the