LLM Adventures: RAG Apps
This post summarizes my research around the increasingly popular RAG apps, and it’s meant more as an internal memo to myself to summarize existing findings should one day a suitable project comes along. However, someone starting with RAG development might find this useful (we are all LLM rookies). RAG is a fascinating topic and presents another great case for generative AI in data analytics.
RAG (retrieval-augmented generation) apps apply AI to let end users intelligently search data, such as PDF or Word documents, using natural questions. The most common scenario is for searching internal data because public LLM models don’t have access to your corporate data repositories and therefore know nothing about your data.
Suppose your HR department has accumulated a large knowledge base of files detailing internal policies, such as health plans. Using a home-grown RAG app, the user can type natural questions, such as “Which plan supports vision?” and the RAG application should retrieve and rank related documents. Or a law firm might have documents related to matters and be interested in letting internal users ask natural questions to find the details of a specific case. As you can imagine, many companies can benefit from RAG <insert your company smart search needs here>.
Understanding RAG
Here is a typical high-level RAG architecture:
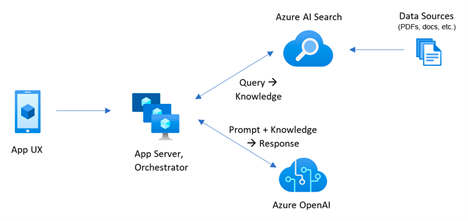
The user uses some sort of UI, such as a web portal, to submit the natural question. The app backend gets the question and submits it to a search service (Retrieval), such as Azure AI Search. Previously, you have configured Azure AI Search to create an index (knowledge base) by indexing the data found in files or popular databases. The following Azure AI Search features should be strongly considered (ideally, both should be implemented):
- Embedding vectors – As a part of indexing the data, each text chunk should have an embedding vector, such as a vector produced by Azure OpenAI LLM embedding model. This allow Azure AI Search to find related documents when related terms are used in the question, such as “vision exam” and “eye exam”, but the underlying documents don’t contain these exact terms.
- Semantic ranking – Once the related documents are identified, Azure AI Search can apply ranking to sort the related documents in descending order of relevance using an optional feature called Semantic Ranker.
Processing more complicated data can be done with Azure Document Intelligence Service (previously Form Recognizer). It’s capable of extracting data from more complicated structured files, such as invoices, medical forms, etc.
Once Azure AI Search returns the related text sections, the natural question and text are then sent to Azure OpenAI (Augmentation) which does the magic of parsing the semantics of the user input and describing the output in natural language typical to LLM-powered chat apps (Generative AI), such as “The plan A has coverage for vision”.
Further reading and code samples
A good starting point to learn about LLM in general and RAG is the Generative AI for Beginners free training (kudos to Kevin Jourdain for the hint). You can find more implementation-specific and in-depth RAG knowledge especially for Azure-based implementations in the excellent Pamela Fox’s YouTube Channel, such as the “Vector search, RAG, and Azure AI search” presentation.
Microsoft has also provided a code intensive end-to-end Python app. This app uses custom code for extracting the text using the Azure Document Intelligence Service, chunking the text, generating embeddings, integrating with Azure AI Search and Azure Open AI, and implementing a web app for the user interface.
An easier code to start with is the AG Academy’s Python sample. It uses custom code for chunking the text (either using the Python PDFReader library or Microsoft Document Intelligence service), and then integrating with Azure AI Search and Azure OpenAI.
Observations
Naturally, given that my developer skills are somewhat rusty (long live low-code BI solutions!), I’m inclined to find a low(er)-code approach that saves development effort. It looks like Microsoft is reasoning along the same lines as they’ve came up with the Azure AI Search Import and Vectorize Wizard (currently in preview). Based on my research, this wizard can avoid tons of custom code to:
- Extract and chunk text.
- Process documents of different types stored in the same folder (for some reason the files must be in ADLS Gen 1 or Fabric One Lake, since ADLS Gen 2 hierarchical folders are not supported).
- Generate embedding vectors by integrating with Azure OpenAI embedding model, such as text-embedding-ada-002.
- Refresh the index on schedule.
You still must write code for the user interface and integrating with Azure AI Search and Azure OpenAI. I’d love to see Microsoft enhancing the wizard to integrate further with Azure OpenAI text-based models in order to avoid the current two-step process that requires custom code for getting the results from Azure Search and them sending them to Azure OpenAI.


