Migrating Fabric Import Semantic Models to Direct Lake (Part 2)
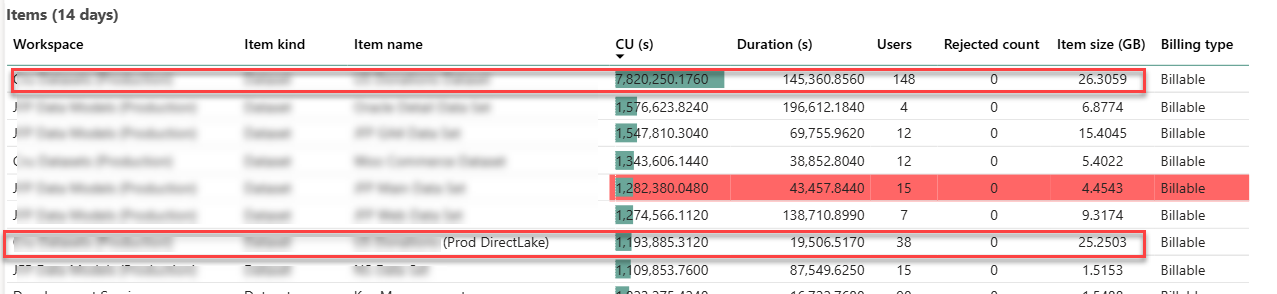
I’ve previously shared my experience with migrating a Fabric imported semantic model to Direct Lake. This blog follows up with additional observations about performance. The following screenshot is taken from the Fabric Capacity Metrics app and it shows the maximum metrics over 14 days. The two enclosed items of interest are the original imported semantic model (the first item on the list) and its DL counterpart (the seventh item on the list).
Memory utilization
As I explained in the first part, the whole reason for taking this epic journey was to solve the out-ot-memory blowouts and constant pressure to climb the Fabric capacity ladder. With 1/5 of the user audience testing the dataset in production environment, that dataset grew to a maximum of 25 GB memory utilization which is in line with the imported model. It could have been interesting to downgrade the capacity, such as to F64, and observe how the DL model would react to memory pressure. However, as shown in the screenshot, the client had other large semantic models that can exhaust the F64 25 memory grant so we couldn’t perform this test.
Again, what we are saving here is the additional memory required for refreshing the model. In a sense, we shifted the model refresh to replicating the data from Google Big Query to a Fabric lakehouse. On the downside, an error during the replication process could leave the replicated tables in an inconsistent state (and user complaints because reports would show no data or stale data) whereas a failure during refreshing the model would fall back on the old model (Fabric builds a new in-memory cache during model refreshing).
The team is currently exploring options to mitigate failures during replications, including incremental replication or using the Delta time-travel features. Replication errors aside, eliminating model refresh is a huge win.
CPU utilization
A while back, I got some feedback that an organization that attempted to switch to Direct Lake found that the capacity CPU utilization increased significantly causing them to revert to import mode.
I didn’t witness CPU pressure during production testing. Further, the team didn’t notice any report performance degradation or increased CU capacity utilization. If I must guess that organization didn’t force the model to Direct Lake Only, causing the model to go back between Direct Lake and Direct Query under certain conditions.
Summary
Assuming you have exhausted traditional methods to alleviate memory pressure, such eliminating high-cardinality column, incremental refresh, etc., Direct Lake is a viable option to conserve memory of Fabric semantic models. Unfortunately, it may require replicating your data to a Fabric lakehouse or migrating your data warehouse to Fabric so that it uses Fabric storage (Delta Parquet format) required for Direct Lake. If this is a new project and you expect large semantic models, your architecture should consider Fabric Data Warehouse or Lakehouse to take advantage of Direct Lake storage for your semantic models.


