Prologika Newsletter Fall 2025
 Like the Ancient Greek philosopher Diogenes, who walked the streets of Athens with a lamp to find one honest man, I have been searching for a convincing Fabric feature for my clients. As Microsoft Fabric evolves, more scenarios unfold. For example, Direct Lake storage mode could help you alleviate memory pressure with large semantic models in certain scenarios, as it did for one client. This newsletter summarizes the important takeaways from this project. If this sounds interesting and you are geographically close to Atlanta, I invite you to the December 1st meeting of the Atlanta MS BI Group where I’ll present the implementation details.
Like the Ancient Greek philosopher Diogenes, who walked the streets of Athens with a lamp to find one honest man, I have been searching for a convincing Fabric feature for my clients. As Microsoft Fabric evolves, more scenarios unfold. For example, Direct Lake storage mode could help you alleviate memory pressure with large semantic models in certain scenarios, as it did for one client. This newsletter summarizes the important takeaways from this project. If this sounds interesting and you are geographically close to Atlanta, I invite you to the December 1st meeting of the Atlanta MS BI Group where I’ll present the implementation details.
About the project
In this case, the client had a 40 GB semantic model with 250 million rows spread across two fact tables. The semantic model imported data from a Google BigQuery (GBQ) data warehouse. The client applied every trick in the book to optimize the model, but they’ve found themselves forced to upgrade from a Power BI F64 to F128 to F256 capacity.
I’ve written in the past about my frustration with Power BI/Fabric capacity resource limits. While the 25 GB RAM grant of a P1/F64 capacity for each dataset is generous for smaller semantic models, such as for self-service BI, it’s inadequate for large organizational semantic models. Ultimately, the developer must face gut wrenching decisions, such as whether to split the model into smaller semantic models to obey what are in my opinion artificially low and inflexible memory limits or ask for more money.
We’ve decided to replicate the GBQ data to a Fabric lakehouse and try Direct Lake to avoid the dataset refresh, which requires at least twice the memory. Granted, replicating data is an awkward solution, but currently Direct Lake requires data to be in Delta tables (Fabric Lakehouse, Data Warehouse, or shortcuts to Delta tables, such as in OneLake or Databricks).
Next, we migrated the largest semantic model from import to Direct Lake. You can find the technical details for the replication and migration steps we took in my blog “Migrating Fabric Import Semantic Models to Direct Lake”.
Performance considerations
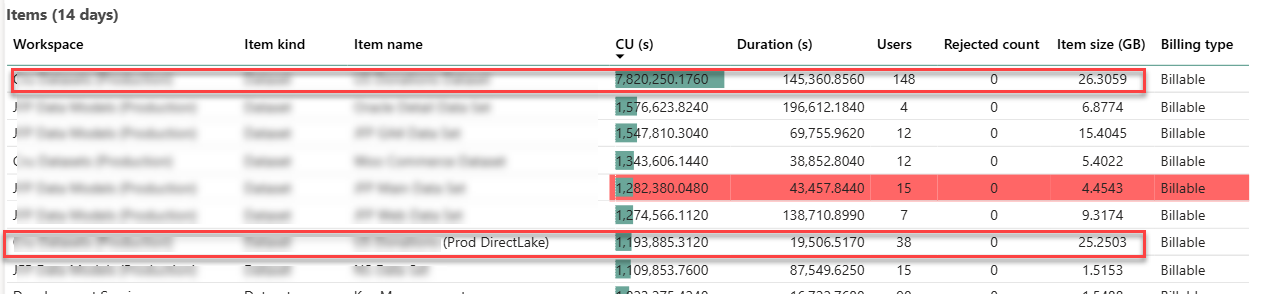
The following screenshot is taken from the Fabric Capacity Metrics app and it shows the maximum metrics over 14 days. The two enclosed items of interest are the original imported semantic model (the first item on the list) and its DL counterpart (the seventh item on the list).
The Direct Lake memory utilization was at a par with the imported model. With 1/5 of the user audience testing the dataset in production environment, that dataset grew to a maximum of 25 GB memory utilization which is in line with the imported model. It could have been interesting to downgrade the capacity, such as to F64, and observe how the DL model would react to memory pressure. However, as shown in the screenshot, the client had other large semantic models that can exhaust the F64 25 memory grant so we couldn’t perform this test.
Again, what we are saving here is the additional memory required for refreshing the model. In a sense, we shifted the model refresh to replicating the data from Google Big Query to a Fabric lakehouse. On the downside, an error during the replication process could leave the replicated tables in an inconsistent state (and user complaints because reports would show no data or stale data) whereas a failure during refreshing the model would fall back on the old model (Fabric builds a new in-memory cache during model refreshing).
We didn’t witness excessive CPU pressure during production testing. Further, the team didn’t notice any report performance degradation or increased CU capacity utilization.
Summary
Assuming you have exhausted traditional methods to alleviate memory pressure, such eliminating high-cardinality column, incremental refresh, etc., Direct Lake is a viable option to conserve memory of Fabric semantic models. However, it may require replicating your data to a Fabric lakehouse or migrating your data warehouse to Fabric so that it uses Fabric storage (Delta Parquet format) required for Direct Lake. If this is a new project and you expect large semantic models, your architecture should strongly consider Fabric Data Warehouse or Lakehouse to take advantage of Direct Lake storage.

Teo Lachev
Prologika, LLC | Making Sense of Data
![]()


