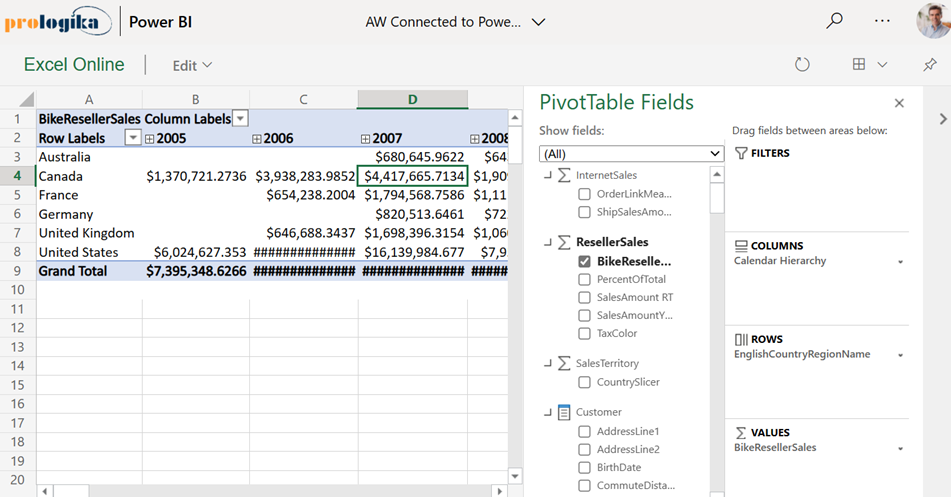
Azure Data Factory is Getting Better All the Time
Three years ago, I wrote that it would probably take a decade for to mature and close the gap with SSIS.
To its credit thought, while it’s still lagging in the area of extensibility, ADF added features that we don’t have in SSIS so I’m developing a taste for it:
- Schema drift – Suppose you want to automatically stage new columns as they added to a source table. Or, columns might be deleted from the source but your ETL shouldn’t fail. You can’t do these things with SSIS which is tightly coupled with the data source schema. ADF data flows, however, can handle this.
- Parallel loops – Want to loop through some tables but load them in parallel? The ADF ForEach loop can be parallelized up to 50 concurrent threads.
- Source partitioning – Let’s say you have a big source table and you want to speed up staging. You can configure the Copy Activity to automatically create multiple threads to load the table in parallel, such as by partition (if the source table is already partitioned) or by buckets based on a primary key.
- Scalability – As I mentioned in the blog above, this was the main driver for Microsoft to start from scratch with ADF. You’d be hard pressed to run out of resources with ADF, so it wins hands down against SSIS in this area.
- Managed VNET on a horizon – Currently in preview, you can ask your helpful System Services to setup a managed virtual network and thus avoid the need to set up self-service runtimes for accessing on-prem data sources. Make sure you install a Linux VM as the tutorial demonstrates since we found the hard way that Windows won’t work.
ADF is not without idiosyncrasies of course. Why would data flows have a separate expression language and require a separate runtime? Speaking of data flows, I almost used them for their automatic file partitioning until I found that I don’t have the control over the partition names to support both full and incremental load. Long live the copy activity!