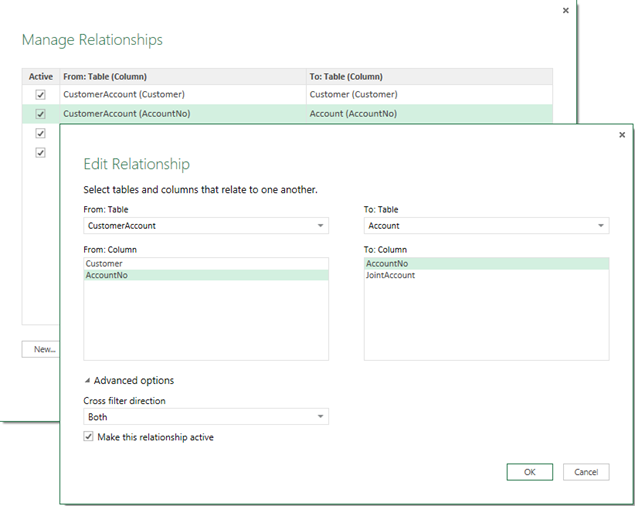
Demystifying Clustered Columnstore Indexes
Non-clustered columnstore indexes (NCCI) were introduced in SQL Server 2012 to improve the performance of large aggregate queries (common for data warehousing) with the caveat that there were read-only. Consequently, the ETL process has to drop NCCI, load the data, and recreate the columnstore index.
NOTE Building an index (columnstore or regular) should be a highly-parallel operation. Building a columnstore index in particular should max out all licensed cores. Currently, we have an open support case with Microsoft where a columnstore index allows adding a computed column (while it shouldn’t). Consequently, SQL Server builds the index using a single thread which may lead to excessive index creation times.
SQL Server 2014 introduced clustered columnstore indexes (CCI) which offer two main advantages:
- CCI is updatable — Therefore, you don’t have to drop and recreate the index anymore.
- Storage is greatly reduced — For example, you might have a fact table of 100 GB. Assuming x10 compression, your table space with NCCI will be 110 GB. However, if you create CCI the table space will be only 10 GB. This is why Analytics Platform System (previously known is PDW) uses CCI.
On the downside, CCI doesn’t support any other indexes that you might need to optimize ETL or speed up joins. Basically, CCI is the only index you can have on a table. However, CCI is not designed for equality and short-range queries that are typical for detail-level SELECT or MERGE queries. It’s a common misconception that you don’t need such indexes with CCI but this is not the case. I hope a future release of SQL Server enhances CCI to support regular indexes as well.