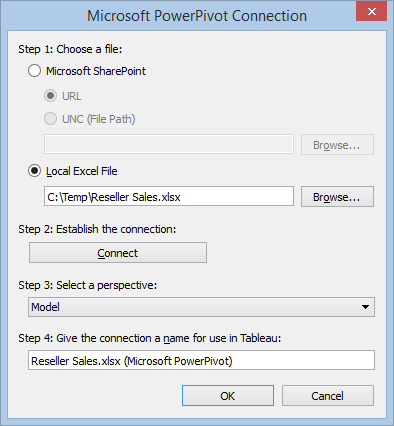
BISM Drillthrough Capabilities
All the three BISM flavors (Multidimensional, Tabular, and Power Pivot) supports default drillthrough to allow the end user to see the level of details behind an aggregated measure by just double-clicking the cell. However, the implementation details differ. Multidimensional supports default drillthrough on regular measures only, that is, measures that bind to columns in fact tables. Multidimensional doesn’t support drillthrough on calculated measures, even if these measures are simple tuples, such as ([Measures].[Sales Amount], [Product].[Product Category].[Some Category]).
On the other hand, Power Pivot and Tabular don’t have the concept of regular measures and they support only calculated measures. Even if the user drags a column to the Values zone on a pivot or Power View report, the tool creates an implicit measure with a DAX formula behind the scenes, such as =SUM(ResellerSales[Sales Amount]). Because of this, Power Pivot and Tabular appears to allow drillthrough on any measure. However, the drillthough action only picks the filter context. It does not parse the calculated measure. So, if you have an explicit measure with a DAX formula that filters the results, such as =CALCULATE( SUM( ResellerSales[Sales Amount] , FILTER(SalesTerritory, SalesTerritory[Country] = “USA” ) ), the drillthrough action won’t return the rows where country=’USA’. Instead, it will return the rows from the ‘home’ table within the default context inferred by rows, columns, and filters on the report.
While we are on the subject of drillthrough, Multidimensional allows the modeler to specify custom actions, such as an action that runs an SSRS report or opens a web page. As it stands, Power Pivot and Tabular don’t provide UI for custom actions although the drillthrough functionality is there. As a workaround, you can use the BIDS Helper Tabular Actions Editor feature to implement custom drillthrough actions.