Divorce Your Methodology
At the Atlanta BI meeting last night, there was a question from the audience about differences between Inmon and Kimball and which methodology should be followed when implementing a data warehouse. I’ll recapture my thoughts and the feedback I shared.
As BI practitioners, most of us use methodologies and it’s easy to fall in love with a specific methodology. But sometimes methodologies conflict each other. So, don’t feel very strongly about methodologies. Instead, study them and try to synthetize their best. The best methodology is the one that delivers a business solution in the most practical and simple way. Back to Inmon vs Kimball, I have deep respect for both of them. They both contributed a lot to data warehousing that forms the backbone of modern BI. Both of these two methodologies aim to consolidate data and promote a single version of the truth. Both of them are “pure” database-focused and vendor-neutral methodologies for designing data structures. But they also differ in significant ways. This table summarizes the high level differences between the two methodologies.
| Inmon | Kimball | |
| APPROACH | Top-down Data warehouse first, data marts later |
Bottom-up Data marts first, data warehouse later |
| SCHEMA | Normalized (3NF) schema | Denormalized (star) schema |
| HISTORY | All history needs to be captured | Depends on business requirements Type 1 vs Type 2 dimensions |
So, which one to follow? My answer is that there is a place for both. Consider the following BI architectural view.
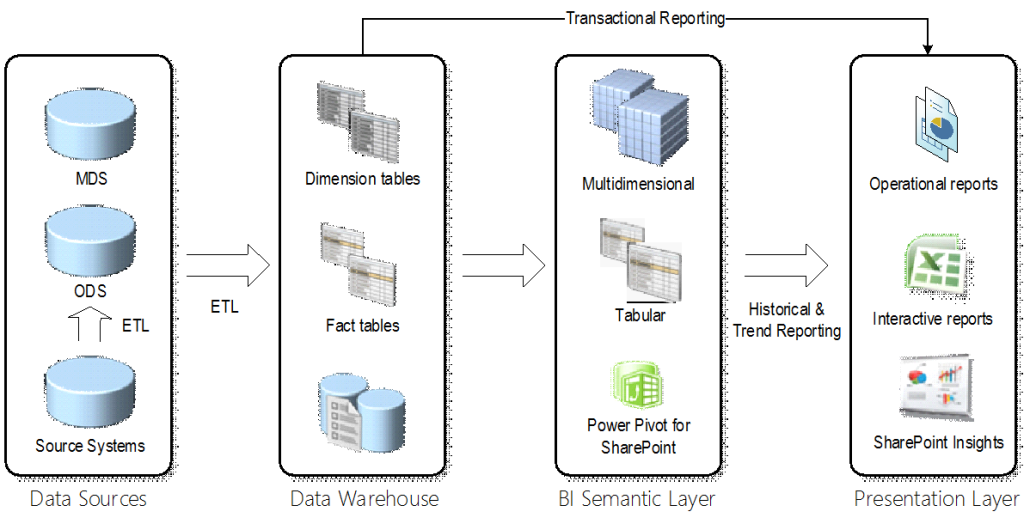
Data comes from veriety of data sources. Some data, such as Products, Customers, Organizations, represents master data that should be ideally maintained in a separate repository, e.g. in Master Data Services. However, most of the source data is not master data and must be staged before it’s imported in the data warehouse. Instead of a transient staging database whose data is truncated with each ETL run, consider an ODS-style staging database that maintains historical changes.
| Start_Date | End_Date | Store | Product | Deleted_Flag |
| 1/1/2010 | 5/1/2010 | Atlanta | Mountain Bike 1 | |
| 5/2/2010 | 3/8/2012 | Atlanta | Mountain Bike 2 | |
| 3/9/2012 | 12/31/9999 | Norcross | Mountain Bike 2 |
The Start_Date and End_Date columns are used to record the lifespan of each record and create row new versions each time the source row is changed. The example shows three changes that a given product has undergone. This design offers two main benefits:
1. It maintains a history of all changes that were made to all columns to all tables. Typically, OLTP systems don’t keep track of changes so the staging database can be used to record changes.
2. It maintains a full backup of the data. If a data warehouse needs to be reloaded, its history can be recreated from the staging database.
This ODS design is effectively your Inmon methodology in practice. For the data warehouse, I’d go with Kimball dimensional modelling. Dimensional modelling is a practical design technique whose goal is to produce a simple schema that is optimized for reporting. As far as data marts, I’m not so excited about moving data in or out of the data warehouse. In most cases, the most practical approach would be to implement a single data warehouse database and extend it as more subject areas come onboard. However, large organizations might benefit from data marts. For example, a large organization might have an enterprise data warehouse but for whatever reasons (usually IT not having enough resources), it might be difficult or not practical to extend it with a new subject areas. Then, this department might spin off its own data mart, such as on a separate database server (even from a different vendor, e.g. DW on Oracle and DM on SQL Server).
Ideally, the data mart should be able to reuse some of conformant dimensions from the data warehouse instead of implementing them anew. In reality, though, the enterprise bus could remain a wishful thinking. Having been left on his own devices, that department would probably need to implement the dimensions from the data they work with. For example, if this is an HR data mart, they would probably source an Organization dimension from PeopleSoft which is where their core data might come from.
With the risk of repeating myself, I want to reemphasize the role of the semantic layer which plays a critical role in every BI architecture. If you are successful implementing an enterprise bus consisting of a data warehouse and data marts (hub and spokes architecture), the semantic layer can provide a unified view the combines these data structures. For more information about the semantic layer benefits, refer to my newsletter “Why Semantic Layer“.


