Notes on Power BI Incremental Refresh
In my “Why Business Like Yours Choose Power BI Over Sisense” blog, I discussed how Sisense seeks a competitive advantage by offering a user-friendly designer connected to the their ElastiCube, thus claiming that Sisense is a better choice with larger datasets because business users don’t have to use professional tools (Visual Studio) or deploy to external servers. Things have changed in Power BI since then. Microsoft increased the dataset size to 1 GB (Power BI Pro) and 10 GB (Power BI Premium). A 10 GB compressed dataset is a lot of data (probably allowing you to import over a billion rows). But fully refreshing a large dataset is no fun and it can take many hours (see my blog “Processing AAS Models Asynchronously” for some stats).
Fortunately, the May release of Power BI Desktop brings incremental refresh, which a feature that was previously only available in Analysis Services. As its name suggests, the primary goal is to reduce the time required to refresh datasets with imported data by processing only data that has changed instead of the entire dataset.
I was involved and provided feedback during the prerelease testing of Power BI incremental refresh. Without reiterating the documentation, here are some things you need to pay attention to:
- Incremental refresh is a Power BI Premium feature. Although you configure it in Power BI Desktop, you can’t test it in Power BI Desktop. You must deploy the file to a premium workspace to put it in action. I provided feedback that this feature should be also available in shared capacity workspaces because its primary goal is to reduce resources in a shared environment but as it stands incremental refresh is a premium feature.
- Associate the RangeStart and RangeEnd query parameters in a custom filter to one column in the table set up for incremental refresh. During development, it makes sense to load a subset of the data, such as for only one year. So, set RangeStart and RangeEnd accordingly.
- When you define a custom filter that uses RangeStart and RangeEnd on the table you configure for incremental refresh, triple verify the filter range to ensure that rows don’t overlap. Here is an example of a correct custom filter. If I make a mistake and I change the right boundary to [OrderDate] <= RangeEnd, then I’ll get overlapping rows for the end period. So, make sure that you don’t specify the equal sign in both the left boundary and right boundary.
= Table.SelectRows(dbo_FactResellerSales, each [OrderDate] >= RangeStart and [OrderDate] < RangeEnd) - I suggested Microsoft provide a narrative that restates the configuration of the incremental refresh policy. For example, the configuration below means “This policy will load historical data from Jan 1st, 1997 to the current date. Subsequent refreshes will process only the last 10 days to the current system date (UTC time).”
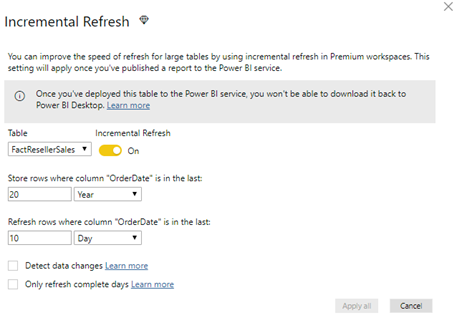
- When you deploy to *.pbix file to a premium workspace and navigate to the dataset refresh page, you’ll see that the entire Parameters section is disabled. This is a bug which should be fixed by the time incremental refresh goes out of preview. It should remove or disable only the RangeStart and RangeEnd parameters but enable other query parameters. That’s because the RangeStart and RangeEnd parameter values are not used once the model is published.
- Because incremental refresh requires a new schema comparability level, you can’t connect to Power BI Desktop models in SSMS. Incremental refresh also breaks the feature for importing Power BI Desktop files in Azure Analysis Services.
What happens behind the hood?
You should appreciate how simple Power BI incremental refresh is to set up. BI pros know that SSAS partitions take some effort to set up. It gets more complicated when you need to set up rolling partitions and merge partitions. In Power BI, you only need to configure the refresh policy and Microsoft takes care of the rest. Behind the scenes, Microsoft introduced a new partition type that has a refresh policy and parameterized query using the RangeStart and RangeEnd parameters. When the model is refreshed, Power BI expands this partition type and creates the actual table partitions. Considering the above setup, it creates 20 yearly partitions, 1 Quarter partition (for Q1 2018), and 35 daily partitions, assuming the current date is May 5, 2018. These partitions get consolidated and merged over time. For example, once Q2 is full, all daily partitions are merged into a monthly partition, and when the quarter is complete, monthly partitions get merged into a quarterly partition, then quarters get merged into years. Power BI also takes care of removing older partitions when they fall off the range (sliding window).
As the documentation mentions, a “preview” limitation is that subsequent publishing from Power BI Desktop replaces the published refresh policy and triggers a full load on the next refresh. Remember that full load happens once the first time you initiate manual or scheduled refresh of the published dataset. Once the dataset is fully loaded, subsequent refreshes load the dataset incrementally (the last 10 days with the above configuration). Currently, there isn’t a way to reload the dataset (full refresh), such as when you discover the historical data has issues and you need to reload the history, except deleting the dataset and republishing it. I hope that Microsoft will enable access to the Analysis Services Tabular management endpoint to support such scenarios. Or, a better option might be to extend the Parameters section in the refresh page to include an option for full load so that the business user can trigger a full reload.
Query Folding
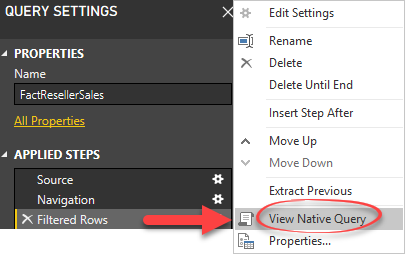
One important consideration to keep in mind is that incremental refresh works best with data sources that support query folding. Such data sources pass through some Power Query transformation steps, such as filtering and grouping, to the underlying data source to improve performance and avoid loading the entire dataset before filtering and grouping is applied. To determine if a specific step is “folded”, right-click the step, such as Filtered Rows, in the Applied Steps pane and observe if the “View Native Query” is enabled.
Although Microsoft doesn’t have an official list of data sources that support query folding and what steps are folded, typically relational data sources and data sources that can handle the SQL WHERE clause support query folding. Excel and text files do not. It’s important to check query folding because it the data source doesn’t support it, Power BI Desktop currently doesn’t prevent incremental refresh but it will load all the data before the filter is applied. Specifically, the query mashup (M) engine will apply the filter as it reads the rows before it gets loaded into the partitions. You might be able to mitigate this performance issue with non-foldable sources by applying the RangeStart/RangeEnd filter when the initial query is sent to the data source. For example, Dynamics Online supports a $filter clause that will work with incremental refresh:
= OData.Feed(“<endpoint url>/sales?$filter=CreatedDate ge ” & Date.ToText(RangeStart) & ” and CreatedDate lt ” & Date.ToText(RangeEnd)”)
Power BI incremental refresh is an important enhancement to the Power BI data architecture. A Power BI premium feature, incremental refresh brings the following benefits for tackling larger datasets: data loads are faster, data loads are more reliable (no long-running connections), and reduced resource consumption.



