Prologika Newsletter Spring 2015
 A while back I met with a client that was considering overhauling their BI. They asked me if the traditional data warehousing still makes sense or should they consider a logical data warehouse, Big Data, or some other “modern variant”. This newsletter discusses where data warehousing is going and explains how different data architectures complement instead of compete with each other.
A while back I met with a client that was considering overhauling their BI. They asked me if the traditional data warehousing still makes sense or should they consider a logical data warehouse, Big Data, or some other “modern variant”. This newsletter discusses where data warehousing is going and explains how different data architectures complement instead of compete with each other.
QUO VADIS DATA WAREHOUSE?
The following diagram illustrates the “classic” BI architecture consisting of source data, data staging, data warehouse, data model, and presentation layers (click to enlarge the image).
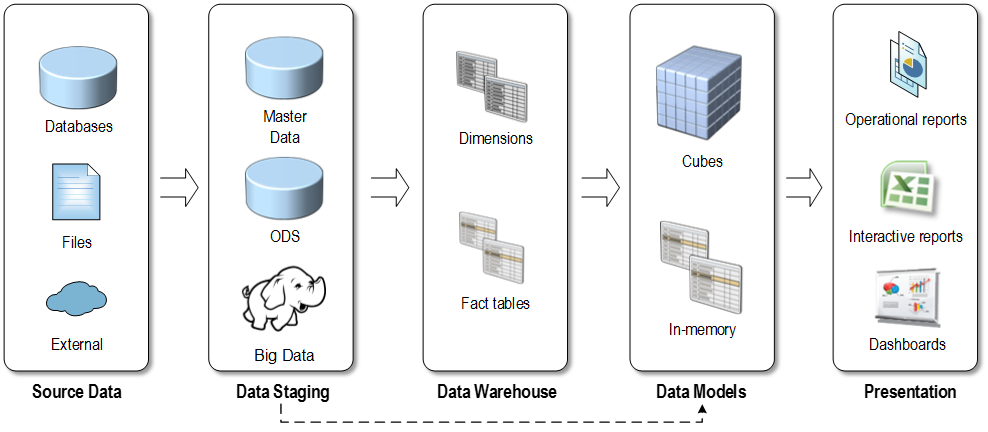
Yes, not only is the data warehouse not obsolete, but it plays a central role in this architectural stack. Almost always data needs to be imported, cleansed and transformed before it can be analyzed. The ETL effort typically takes 60-80% percent of BI implementation effort. And, currently there isn’t a better way to store the transformed data than to have a central data repository, typically referred to as a “data warehouse”.
That’s because a data warehouse database is specifically designed for analytics.
Ideally, most or even all of dimensional data should be centrally managed by business users (data stewards) outside the data warehouse. However, the unfortunate truth is that not many companies invest in master data management. Instead, they kick the data quality can down the road and pay much higher data quality later but this is a topic for another newsletter. A well-thought architecture should also include a data model (semantic) layer, whose purpose and advantages I’ve outlined in my “Why Semantic Layer?” newsletter.
BIG DATA
Irrespective of the huge vendor propaganda surrounding Big Data, based on my experience most of you still tackle much smaller datasets (usually in the range of millions or billions at worst). This is not Big Data since a single (SMP) database server can accommodate such datasets. This is a good news for you because Big Data typically equates big headaches. For those of you who truly have Big Data, its implementation should complement, instead of replace, your data warehouse. Even though the advancements in the popular Big Data technologies are removing or mitigating some of the Big Data concerns, such as slow queries, these technologies are still “write-once, read many”, meaning that they are not designed for ETL and data changes.
Moreover, a core tenant of data warehousing is providing a user-friendly schema that supports ad-hoc reporting and self-service BI requirements. By contrast, BI Data is typically implemented as a “data lake” where data is simply parked without any transformation. For more information about Big Data and how it can fit into your BI architecture, read my Big Data newsletter.
LOGICAL DATA WAREHOUSE
Recently, logical data warehouses (LDW) have gained some traction and backing from vendors, including Composite (acquired by Cisco), Denado, and others. Logical data warehousing is also known as data federation and data virtualization. The idea is simple – consolidate and share the data in a controlled manner to all users and applications across the enterprise. Data is made available as virtual views on top of existing data sources, with additional features, such as discovery and caching. Again, the goal here is not to replace the traditional data warehouse, but make its data, plus the data from other systems, readily available for self-service BI and/or custom applications.
Logical data warehousing is at a very early stage of adoption. In my opinion, the companies that will benefit most of it are large organizations with many data repositories, where data availability is a major barrier for enabling self-service BI. If you believe that your organization might benefit from a Logical Data Warehouse, you might not need to make a major investment. If your organization has an Office 365 Power BI subscription, your first step could be leveraging the Power Query capabilities for dataset sharing and discovery. This process can work like this:
- Designated users promote virtual views in the form of Power Query queries to Office 365.
- A data steward verifies and approves these datasets.
- Once signed in to Office 365, other users can search, preview these queries, and import the associated data in self-service BI models.
The following snapshot shows how a business user can search and preview a published query that returns Product List data.
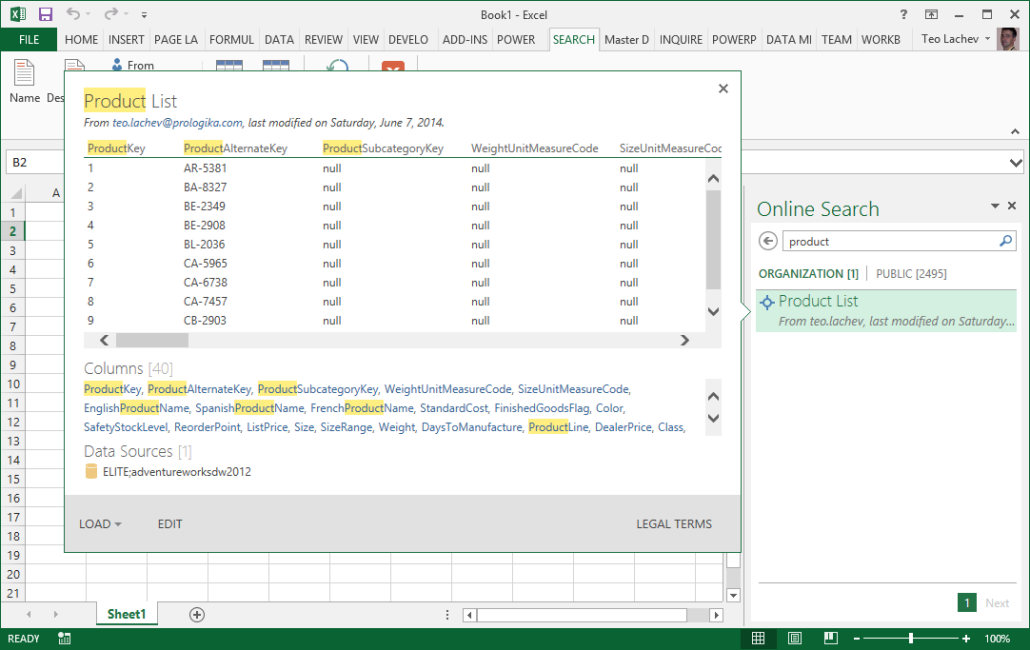
One caveat is that these shared queries are currently Power Query-specific and they can only consumed by Microsoft self-service BI tools, which currently include Excel and Power BI Designer. I recommended to Microsoft to expose shared queries as ODATA feeds to enable additional integration scenarios.
SELF-SERVICE BI
Self-service BI allows power users to create their own data models by using specialized tools, such as Power Pivot, Tableau, QlikView, and so on. Despite what some “pure” self-service BI vendors proclaim, self-service BI is not a replacement for data warehousing. In fact, a data warehouse is often a prerequisite and a major enabler for self-service BI. That’s because a data warehouse provides consumers with clean and trusted data that can be further enriched with external data
As you’d agree, the BI landscape is fast-moving and it might be overwhelming. As a Microsoft Gold Partner and premier BI firm, you can trust us to help you plan and implement your data analytics projects.
Regards,
Teo Lachev
President and Owner
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
EVENTS & RESOURCES
 PASS Data Analytics Conference, April 20-22, Santa Clara, California
PASS Data Analytics Conference, April 20-22, Santa Clara, California
Atlanta BI Group: Overview of R by Neal Waterstreet on March 30th
Friendlier Data Profiling with the SSIS Data Profiler Task by Julie Smith on April 27th
SQL Saturday Atlanta on May 16th


