From Prompt to Insight: My Daily Dance with AI
“I go checking out the reports, digging up the dirt
You get to meet all sorts in this line of work
And when I find the reason, I still can’t get used to it
And what have you got at the end of the day?
What have you got to take away?”
Private investigations, Dire Straits
Here we go
Me: “Write code to do this and that.”
LLM: “I’m glad to help. Here is the code.”
Me: “It doesn’t work because of this error <nasty error message follows>”
LLM: “You get this error because…Here is the correct code.”
Me: “Doesn’t work again because of this new error <nastier error message follows>.”
LLM: “You get this error because…Here is the correction of the corrected code.”
After N iterations and mutual blame, we either get eventually to working code or give up and start cursing each other. LLM usually quits first, claiming I have exhausted my quota, so I start harassing the next vendor.
Me: “Why didn’t get it right the first time?”
LLM: “That’s rude…I’m learning and I can make mistakes…don’t hurt my feelings.”
Teo’s top 5 LLM professional wishes
These typical exchanges inspired by top 5 LLM wishes:
- If you are still learning, why can’t you be more humble and less assertive? This reminds me of some members of my family whose level of assertiveness is a reverse correlation with their knowledge of the subject. But it could be that LLMs are designed to act as humans in this regard too.
- When it comes to code generation, can we use the latest versions, class signatures, etc.? We all know how quickly programing interfaces evolve.
- Even better, can you compile the code to ensure that at least I don’t get compile errors?
- Best, can you actually run the code instead of claiming that the code will produce the desired outcome?
- When you substantiate your claims with references, can you ensure that they do what I asked you to do? Can you display a warning that you’re reasoning over some code example that is N years old?
Admiration lives on
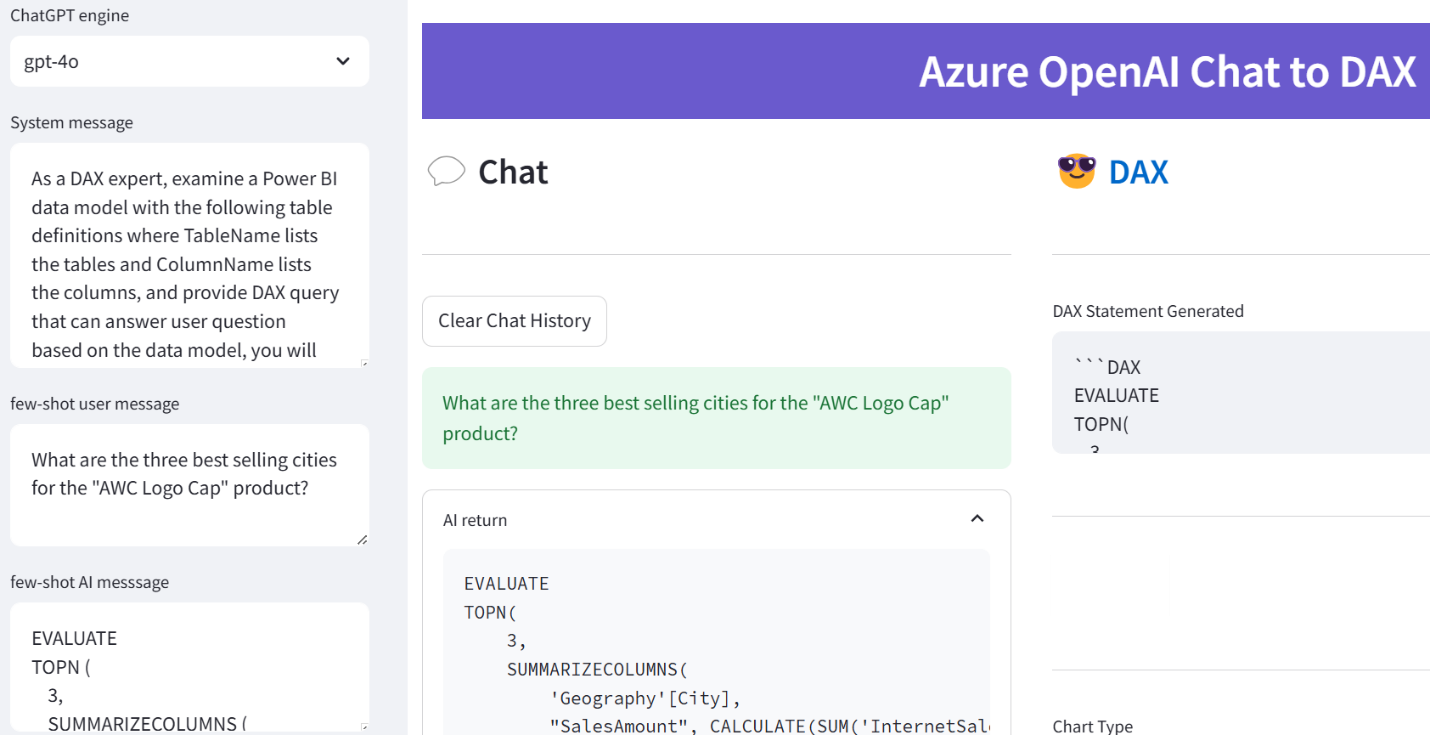
Other than that, I keep on being impressed with LLMs. Specifically, I’m impressed by their reasoning and code generation capabilities, especially when it comes to pioneering languages that have decided to plant their flag in lands unknown, such as Power BI DAX, Power Query M, and Azure Data Factory (whatever bizarre expression language it adopted).
As of now, I believe that experts and architects who have solid foundation skills are in position to gain the most as I won’t trust AI to make architectural or design decisions.
Speaking of being impressed, the latest gem I’ve discovered was Microsoft Copilot Screen Sharing. I used it recently to analyze charts from the Fabric Capacity Metrics app whose primary design goal appears to be leaving the user utterly confused or convinced that it’s time to upgrade their Fabric capacity (see these red spikes? time for upgrade!). In my humble opinion, its output could have been much more useful if it had a chart showing the average resource utilization instead of actual, but I digress. However, the Screen Sharing feature saved taking screenshots and intelligently pointed out what the issue was.
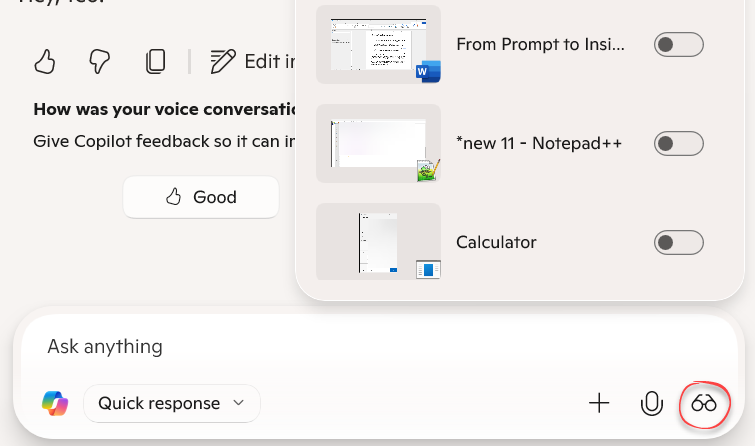
On the downside, ChatGPT did a better job with screenshots. For example, it correctly identified ‘AS’ as Analysis Services workload and came up with better conclusions. Luckily, having multiple assistants it’s not an issue and they don’t complain unless you start abusing them…



 Looking for easy ways to create intelligent bots or Retrieval-Augmented Generation (RAG) apps?
Looking for easy ways to create intelligent bots or Retrieval-Augmented Generation (RAG) apps? 

 When it comes to Generative AI and Large Language Models (LLMs), most people fall into two categories. The first is alarmists. These people are concerned about the negative connotations of indiscriminate usage of AI, such as losing their jobs or military weapons for mass annihilation. The second category are deniers, and I must admit I was one of them. When Generative AI came out, I dismissed it as vendor propaganda, like Big Data, auto-generative BI tools, lakehouses, ML, and the like. But the more I learn and use Generative AI, the more credit I believe it deserves. Because LLMs are trained with human and programming languages, one natural case where they could be helpful are code copilots, which is the focus of this newsletter. Let’s give Generative AI some credit!
When it comes to Generative AI and Large Language Models (LLMs), most people fall into two categories. The first is alarmists. These people are concerned about the negative connotations of indiscriminate usage of AI, such as losing their jobs or military weapons for mass annihilation. The second category are deniers, and I must admit I was one of them. When Generative AI came out, I dismissed it as vendor propaganda, like Big Data, auto-generative BI tools, lakehouses, ML, and the like. But the more I learn and use Generative AI, the more credit I believe it deserves. Because LLMs are trained with human and programming languages, one natural case where they could be helpful are code copilots, which is the focus of this newsletter. Let’s give Generative AI some credit!