Formatting Calculated Members
Consider the following calculated member definition added to the script in an Analysis Services cube:
CREATE
MEMBER
CURRENTCUBE.[Measures].[Revenue TTM] AS ([Measures].[Revenue Amount USD], [Relative Date].[TTM]), FORMAT_STRING = “Currency”, VISIBLE = 1;
When you browse the member in Excel, you’ll find that the member is not formatted as currency. However, when you use SSMS and query the member, when you double-click the member cell in the query results, you’ll see that the value is formatted as expected. Clearly, Excel has an issue with formatting calculated members and there is a connect bug report that has been quietly sitting in the Excel bucket for years. To Microsoft credit, we have a KB article “Description of the LANGUAGE cell property in SQL Server 2005 Analysis Services”.
“However, SQL Server 2005 Analysis Services cannot determine the value of the LANGUAGE cell property or of the currency symbol for calculated members from the query context. You must specify the LANGUAGE cell property if you want to obtain a nondefault currency symbol. If you do not specify the LANGUAGE cell property, the numeric value of the cell value and the currency symbol of the cell value may not match.”
I think what they meant was specifying the Language property in the calculated member definition. Indeed, the following change causes Excel to show the calculated member formatted as currency (USD in this case):
CREATE
MEMBER
CURRENTCUBE.[Measures].[Revenue TTM] AS ([Measures].[Revenue Amount USD], [Relative Date].[TTM]), FORMAT_STRING = “Currency”, VISIBLE = 1, LANGUAGE=1033;
What about dynamic formatting based on the selected currency? Assuming that you have a Destination Currency dimension and includes a Locale column with the integer locale identifier, e.g. 1033 for USD, 1031 for EUR, and so on), the following script overwrites the member language and the value will be formatted based on the destination currency selected by the user:
Scope (
[Destination Currency].[Currency].[Currency].Members,
{
[Measures].[Revenue TTM]
}
);
Language( this ) = [Destination Currency].[Currency].Properties( “Locale” );
End
Scope;
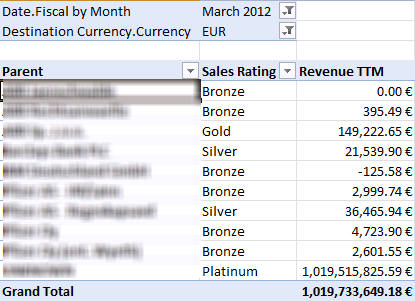
TIP On the subject of formatting, you might need to “pin” a calculated member to a particular currency format to avoid the OLAP browser changing the format. As a fist attempt, you might try hardcoding the currency sign, such as “$0,0.00′”. Unfortunately, Excel will ignore it and overwrite it based on the regional settings. For example, a UK user will still see “£100.00”. Hrvoje Piasevoli suggested escaping the currency symbol to prevent this from happening, e.g. create member currentcube.measures.test as 1000.01, format_string=”\$0,0.00″, language=1033;
Since I live in the USA, I have to admit I’m somewhat shielded from the localization complexities surrounding currency and date formatting. Chris Webb wrote a blog “Currency formats: should they be tied to language?” a while back that you should check as well.