Scenario: Consider a SQL Server configured for AlwaysOn Availability Groups where a set of databases can fail over to another node. You have SSIS jobs and you created them on both nodes. However, you need to check if the current node on which the job is running is the primary node. If you don’t do this, the job fails because the database isn’t accessible.
Solution: In every SQL Server Agent Job, add a first step to check if one of the replicated databases in the AlwaysOn availability group is the primary replica:
IF sys.fn_hadr_is_primary_replica (‘<replicated dataset name here>’) = 0
BEGIN
EXEC msdb..sp_stop_job N’DW Daily Load’;
END
This script checks if the database is a primary replica. If this is not the case, the script stops the next step, which in this case is the “DW Daily Load” step.
SQL Server 2017 introduces the ability to scale out SSIS. The primary scenario is to enable customers to scale out their SSIS execution at the package level. Imagine a retail business that has about 300 packages to run at the end of the day to push transactional data/finance data from multiple stores to the centralized data warehouse for reporting. All the 300 packages need to run at night but they also need to finish by 6 AM in the morning before new business day starts. As business grows, data size grows, and it takes longer time to run the 300 packages and it is becoming more difficult for the ETL processing window to finish before 6 AM. With SSIS scale out feature, you can now set up the scale out cluster with 1 master and N workers, so that the master can automatically distribute the packages to the workers based on the worker availability, therefore, it helps parallelize the execution at package level and achieve faster completion time. You don’t have to worry about which packages will be executed by which worker, as it’s handled by the master. All you need is to deploy the 300 packages into the catalog and then trigger the ETL run.
Sounds like an easy fix to your long ETL processing times? As with any technology, my advice is to focus on improving the performance of your ETL first, then scale up, then scale out. Here are the top 5 performance issues that I see over and over in my consulting practice:
No parallelism – Packages run sequentially, e.g. dimensions are populated one by one and then fact tables one by one. Meanwhile, despite all the CPU power and cores you fought hard to secure, the server isn’t doing much. Instead, you should run things in parallel as much you can with the goal to saturate that server CPU bandwidth. Ideally, you should invest into a framework that can automatically distribute work across packages with on a configurable degree of parallelism, as the one that we use and is mentioned in my newsletter ” Is ETL (E)ating (T)hou (L)ive?”.
No incremental extraction – The less data you process, the faster your ETL will be. You should strive to extract only the rows that have changed if possible, using techniques such as LastUpdated timestamp, Temporal tables, or CDC.
ETL instead of ELT pattern – Influenced by Microsoft and expert advice, you’ve decided to use the data flow transforms. For example, in a recent ETL review, I found that a Lookup task caches all the 50 million rows from a fact table in memory to determine a row should be inserted or updated! What happens when (not if) one day the fact table swells to 500 million rows? Instead, almost always the ELT pattern that relies on stored procedures and T-SQL MERGE would be a better choice from a performance standpoint. 30 years went into improving and evolving Microsoft SQL Server. It would be naïve not to take advantage of this evaluation and its set-based processing. And as a bonus, one day if you decide to migrate your DW to the cloud, such as by using Azure SQL Data Warehouse, you’ll find that ELT is recommended (unfortunately, Azure SQL DW still doesn’t support MERGE but one day I hope it will).
Query optimization – Needless to say, your queries should be optimized. In the same recent review, I found that one query that extract data from ODS takes four hours to execute!
Excessive data movement – This goes back to incremental extraction but I often see ETL that does full load or partial load (e.g. the last six months) and copies millions of rows from source to staging table 1, staging table 2, …, and finally data warehouse.
If, after you follow the above best practices, you still find that you’re exceeding your ETL processing windows, you should consider scaling out SSIS. Before doing so, consider the following limitations in the SSIS scale-out feature in SQL Server 2017:
A best practice is to partition your ETL process in child packages that are orchestrated by a master package using the Execute Package Task (EPT). SSIS scale-out can run packages with EPT but it does not scale out the EPT packages execution on another machine. If you have a main package, which as various sub package execution with EPT, the package and all EPT sub package execution will run on the same worker machine, while other workers in your scale out cluster can handle other packages that are independent. If some order/dependency is needed, there will be extra work needed from you to design a master package on purpose (i.e. one master package to control the overall flow and trigger execution in Scale-out and wait for the result accordingly).
If you opt for the ELT pattern as I suggested, scaling out might not help all that much. Your gain will depend on where the performance bottleneck is. If the bottleneck is already in the database, scaling out ETL across multiple nodes will be a futile effort. But if the bottleneck is not the database, then the scale-out can still help to take advantage of multiple machines.
When a package is scheduled in scale-out, by default it is possible for it to be assigned to any worker node to be executed. But if needed, you can also specify which worker node(s) you want the package execution to be assigned to when triggering the execution. The master node doesn’t monitor the worker utilization. Instead the worker node does its own CPU or Memory’s monitoring and tells the master if it can take more packages.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2017-06-11 16:54:172017-06-11 16:54:17Scaling out SSIS in SQL Server 2017
It’s a good practice to have a custom ETL framework that augment the SSIS capabilities. ETL frameworks come in different shapes and sizes but what I’d like to see in a framework is:
Configurable parallelism – Does your ETL take hours? The chances are that your packages run sequentially. Or, disconnected flows in the master package’s control flow support limited parallelism, while your server probably has much bigger pipeline. By contrast, the framework we use support configuring the degree of parallelism and automatically distributes packages to be executed on different threads.
Target and actual package execution duration – You must proactively monitor when the actual package execution exceeds its target duration. See my newsletter “Is ETL (E)ating (T)hou (L)ive?” of a real-life example of what could happen if you don’t do this. Plan to implement an ETL dashboard for monitoring the package execution against its target and to let the users know what date the data is current as by every source system.
Restartability – Resume package execution from the point of failure.
Sufficient auditing checks to ensure data quality – This is usually done by recording row counts of extracted, inserted, updated, and deleted rows. I’d also like to see ETL packages doing some quality checks to ensure the data is consistent as it moves through the pipeline (source, staging, DW, cubes).
I’m currently auditing an ETL implementation where the original developers didn’t record row counts. Citing regulatory requirements, such as The Sarbanes-Oxley Act, the ETL was later”enriched” to record before and after row counts of every possible DML operation. If this is the stated business requirement, then that’s fine but before you start on this this path, consider that the SSIS catalog provides counts for data flow tasks. Before SQL Server 2016, collecting these counts would require enabling Verbose logging. This wasn’t a recommended practice because of the additional overhead. However, in SQL Server 2016 you can create a custom logging level to record only the things you need. Follow these steps to create custom logging level in order to capture row counts:
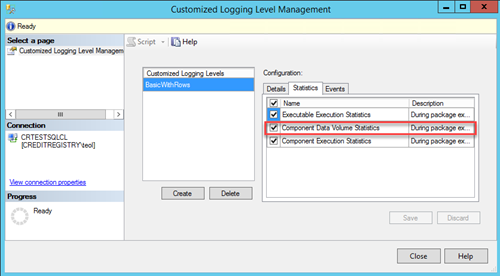
Right-click the SSIS catalog and then click Customized Logging Level. Click the Create button and choose which of the system-defined logging levels you want to use as a base, e.g. Basic.
To record the row counts, make sure to select Component Data Volume Statistics in the Statistics tab.
When configure your job with SQL Server Agent, go to the Configuration tab, click the Advanced Tab, and then select the custom logging level you created in the “Logging level” drop-down.
Because the row counts are recorded for each buffer in the data flow task, in SSMS connect to the SSISDB database and execute this query to group by package, task, and component to see how many rows has gone through each component over time:
SELECT package_name, task_name, [source_component_name] , max(created_time) as created_time, SUM([rows_sent]) AS rows_sent
FROM [catalog].[execution_data_statistics]
GROUP BY package_name, task_name, [source_component_name]
order by 4
As useful as this is, it captures only the row counts in data flow tasks. It won’t record DML operations that are taking place in the Control Flow, such as in Execute SQL Tasks that are calling stored procedures. If capturing row counts in Control Flow is required, you have to do so on your own.
It’s unlikely that capturing row counts alone would satisfy stringent auditing requirements, such as when was the row changed, what change was made and what was the old values. Instead, consider using another feature introduced in SQL Server 2016 Database Engine: temporal tables. By configuring your destination tables as temporal, you let SQL Server to capture data changes in a history table. Now you have a rich audit trail.