I’m setting SQL Server 2019 PolyBase for ODBC to JDBC access to a vendor data lake to virtualize entities as SQL tables. Overall, a smooth experience with a few gotchas:
Data type mappings
The vendor lake uses Oracle data types TIMESTAMP AT TIME ZONE and BOOLEAN that Java doesn’t know how to map. The solution was to set up a view in the data lake (luckily the vendor supports that) to cast these data types to NVARCHAR and INTEGER.
NullPointerException
Once the table is finally set up what do we get when querying it?
How do we fix this horrible issue? Upgrade SQL Server and PolyBase to the latest cummulative update (CU).
The final mystery that I haven’t been able to crack yet is that for some obscure reason, PolyBase adds quite a bit of performance overhead to the query execution. So, if a query in DBeaver directly connected to the lake (or Power BI Desktop directly corrected to the ODBC driver) takes eight seconds, PolyBase expands it to a minute. Examining the DMVs shows that the actual query does execute in line with DBeaver, but there is some additional overhead from PolyBase that would require a support case with Microsoft.
Let’s face it, the larger the company, the more difficult is to achieve the dream of single enterprise data warehouse (EDW). In a typical mid-size to large organization, data is found in many data repositories and integrating all this data is difficult. I’m doing an assessment and strategy engagement now for a unit in a large organization, and they need access to at least 10 other on-premises systems, including two very large repositories. Naturally, they don’t want to import all of this data, which could be millions of rows per day, and recreate their own copy of these large corporate repositories. So what to do?
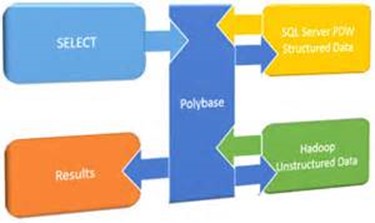
In my “QUO VADIS DATA WAREHOUSE?” newsletter, I defined a logical data warehouse (LDW), also known as data virtualization, is an emerging technology that allows you to access the data where it is. Don’t we have linked servers in SQL Server that do this? We do and they might work to a point. But what if you want scale out distributed queries to achieve better performance? In today’s SQL PASS SUMMIT keynote, Day 1 Keynote “A.C.I.D. Intelligence” (A.C.I.D stands for Algorithms, Cloud, IoT, Data), Rohan Kumar showed something that I think it’s very important and it deserves much more attention than occasional references in blogs. It showed where Microsoft is bringing PolyBase and how this technology could be the Microsoft implementation for data virtualization.
In SQL Server 2016, PolyBase allows you to access data in on-premises Hadoop cluster and in Azure Blob Storage. For example, you can store some files in HDFS and define an external PolyBase table. Then, you can have a query with heterogeneous join between a local SQL Server table and the external table. Rohan showed that Microsoft will extend PolyBase to other popular SQL and NoSQL databases. More importantly, it showed that just like an MPP appliance, such as Microsoft Analytics Platform System (APS) or Azure SQL Data Warehouse, a SQL Server node would allow you to combine multiple SQL Server instances as compute notes so that you scale out access to these data sources. For example, if you have two SQL Server compute nodes and you use PolyBase to access an Oracle database, you’ll be essentially spreading the query across these nodes in parallel and then combine the results. Of course, just like linked servers, there are technical challenges, such as cases where SQL Server might need to move data to the other node. Rohan mentioned that the SQL Server query optimizer will have smarts to optimize heterogeneous joins.
If you’re in the market for a logical data warehouse vendor, don’t rule out Microsoft. Stay tuned for more news around PolyBase and the investments Microsoft makes in this area after the Metanautix acquisition.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2016-10-26 21:06:152016-11-12 16:53:38The Future of Microsoft Logical Data Warehouse