Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, May 3rd, at 6:30 PM. James Serra will overview Azure Synapse for implementing a data lakehouse. And I’ll cover the Power BI latest enhancements. For more details and sign up, visit our group page.
Presentation:
Azure Synapse Analytics Overview: A Data Lakehouse
Azure Synapse Analytics is Azure SQL Data Warehouse evolved: a limitless analytics service that brings together enterprise data warehousing and Big Data analytics into a single service. It gives you the freedom to query data on your terms, using either serverless on-demand or provisioned resources, at scale. Azure Synapse brings these two worlds together with a unified experience to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. In this presentation, James will talk about the new products and features that make up Azure Synapse Analytics and how it fits in a modern data warehouse, as well as provide demonstrations.
Speaker:
James Serra is a Data Platform Architecture Lead at EY. He is a thought leader in the use and application of Big Data and advanced analytics. Previously, James was an independent consultant working as a Data Warehouse/Business Intelligence architect and developer. He is a prior SQL Server MVP with over 35 years of IT experience. James is a popular blogger (JamesSerra.com) and speaker. He is the author of the book “Reporting with Microsoft SQL Server 2012”.
Prototypes without pizza:
Power BI Latest
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2021-04-28 11:36:312021-04-28 11:36:31Atlanta MS BI and Power BI Group Meeting on May 3rd
Cloud deployments are the norm nowadays for new software projects, including BI. And Azure Synapse Analytics shows a great potential for modern cloud-based data analytics platform. Here are some high-level pros and cons to keep in mind for implementing Azure Synapse-centered solutions that I harvested from my real-life projects and workshops.
What’s to Like
There is plenty to like in Azure Synapse which is the evaluation of Azure SQL DW. If you’re tasked to implement a cloud-based data warehouse, you might be evaluating three Azure SQL Server-based PaaS offerings: Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse. However, Azure SQL Database and Azure SQL MI are optimized for OLTP workloads. For example, they have full logging enabled and replicate each transaction across replicas. Full logging is usually a no-no for decent size DW workloads because of the massive ETL changes involved.
In addition, to achieve good performance, you’ll find yourself moving up the performance tiers and toward the price point of the lower Azure Synapse SKUs. Further, unlike Azure SQL Database, Azure Synapse can be paused, such as when reports hit a semantic layer instead of DW, and this may offer additional cost cutting options.
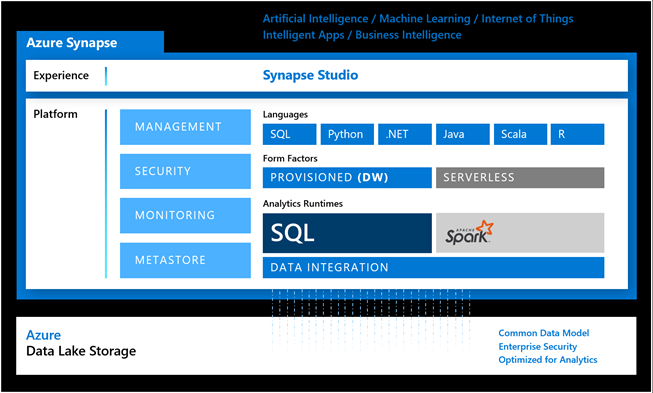
To get started with Synapse, you need to create a workspace. A workspace can host two analytics runtimes, SQL and Spark. These runtimes are hosted in pools. For example, you might have one pool Pool for your enterprise data warehouse, and other SQL pool for a departmental data mart, all provisioned within the same workspace.
A SQL Pool (previously known as Azure SQL DW) hosts your SQL relational database. As an MPP system, it can scale to petabytes of data with proper sizing and good design. The obvious benefit is that for the most part (see the Ugly section discussing exclusions) you can carry your SQL Server skills to Azure Synapse.
As a general rule of thumb, Azure Synapse should be at the forefront of your modern cloud DW with data loads starting with 500 GB.
I like the integration with Azure Data Lake Storage (ADLS). Previously, you had to set up external tables to access files in ADLS via PolyBase. This is might redundant now thanks to the serverless (on-demand) endpoint which also replaces the Gen1 U-SQL with T-SQL. All you have to do is link your ADLS storage accounts and use the T-SQL OPENROWSET construct to query your ADLS files and exposed them as SQL datasets. Not only does this opens new opportunities for ad hoc reporting directly on top of the data lake, but it also can help you save tons of ETL effort to avoid staging the ADLS data while loading your DW.
As the diagram shows, you can also provision an Azure Spark runtime under a Synapse workspace. This opens the possibility for using Azure Spark/Databricks for data transformation and data science. For example, a data scientist can create notebooks in Synapse Studio that use a programming language of their choice (SQL, Python, .NET, Java, Scala, and R are currently supported).
What Needs Improvement
You have two coding options to implement artifacts for Azure Synapse, such as ETL and reports:
You can use the respective development environment, such as Azure Data Factory Studio for ADF development and Power BI Desktop for Power BI report development.
You can use Synapse Studio which attempts to centralize coding in one place.
Besides the ADLS integration and notebooks, I find no advantages in the Synapse Studio “unified experience”, which is currently in preview. In fact, I found it confusing and limiting. The idea here is to offer an online development environment for coding and accessing in one place all artifacts surrounding your DW project. Currently, these are limited to T-SQL scripts, notebooks, Azure Data Factory pipelines, and Power BI datasets and reports. However, I see no good reason to abandon the ADF Studio and do ETL coding in Synapse Studio. In fact, I can only see reasons against doing so. For example, Synapse Studio lags in ADF features, such as source code integration and wrangling workflows. For some obscure reason, Synapse Studio separates data flows from ADF pipelines in its own Data Flows section in the Development Hub. This is like putting the SSIS data flow outside the package. Not to mention that inline data flows should be deemphasized since ELT (not ETL) is the preferred pattern for loading Azure Synapse. To make things worse, once you decide to embrace Synapse Studio for developing ADF artifacts, you can use only Synapse Studio because the ADF pipelines are not available outside Synapse.
On the Power BI side of things, you can create a Power BI dataset in Synapse Studio. All this saves is the effort to go through two Get Data steps in Power BI Desktop to connect to your Azure Synapse endpoint. You can also create Power BI reports using Power BI Embedded in Azure Synapse. Why would I do this outside Power BI Desktop is beyond me. Perhaps, I’m missing the big picture and more features might be coming as Synapse evolves. Speaking of evolution, as of this time, only SQL pools are generally available. Everything else is in preview.
What’s Not to Like
Developers moving from on-prem BI implementations to Azure Synapse, would naturally expect all SQL Server features to be supported, just like moving from on-prem SSAS to Azure AS. However, they will quickly find that Azure Synapse is “one of a kind” SQL Server. The nice user interface in SSMS for carrying out admin tasks, such as creating logins and assigning logins to roles, doesn’t work with Azure Synapse (all changes require T-SQL). SQL Profiler doesn’t work (tip: use the Profiler extension in Azure Data Studio for tracing queries in real time).
Because Azure Synapse uses Azure SQL Database, it’s limited to one physical database, so you must rely on using schemas to separate your staging and DW tables. There are also T-SQL limitations, such as my favorite MERGE for ELT-based UPSERTs is not yet supported (currently in preview for hash and round-robin distributed tables but not for replicated tables, such as dimension tables). So, don’t assume that you can seamlessly migrate your on-prem DW databases to Synapse. Also, don’t assume that your SQL Server knowledge will suffice. Prepare to seriously study Azure Synapse!
Teo Lachev
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
Cloud deployments are the norm nowadays for new software projects, including BI. And Azure Synapse shows a great potential for modern cloud-based data analytics. Here are some high-level pros and cons to keep in mind for implementing Azure Synapse-centered solutions that I harvested from my real-life projects and workshops.
The Good
There is plenty to like in Azure Synapse which is the evaluation of Azure SQL DW. If you’re tasked to implement a cloud-based data warehouse, you have a choice among three Azure SQL Server-based PaaS offerings, including Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse. In a nutshell, Azure SQL Database and Azure SQL MI are optimized for OLTP workloads. For example, they have full logging enabled and replicate each transaction across replicas. Full logging is usually a no-no for decent size DW workloads because of the massive ETL changes involved.
In addition, to achieve good performance, you’ll find yourself moving up the performance tiers and toward the price point of the lower Azure Synapse SKUs. Further, unlike Azure SQL Database, Azure Synapse can be paused, such as when reports hit a semantic layer instead of DW, and this may offer additional cost cutting options.
At the heart of Azure Synapse is the SQL Pool (previously known as Azure SQL DW) which hosts your DW. As an MPP system, it can scale to petabytes of data with proper sizing and good design. The obvious benefit is that for the most part (see the Ugly section discussing exclusions) you can carry your SQL Server skills to Azure Synapse.
As a general rule of thumb, Azure Synapse should be at the forefront of your modern cloud DW with data loads starting with 500 GB.
I liked the integration with Azure Data Lake Storage (ADLS). Previously, you had to set up external tables to access files in ADLS via PolyBase. This is now unnecessary thanks to the serverless (on-demand) endpoint which also replaces the Gen1 U-SQL with T-SQL. All you have to do is link your ADLS storage accounts and use the T-SQL OPENROWSET construct to query your ADLS files and exposed them as SQL datasets. Not only does this opens new opportunities for ad hoc reporting directly on top of the data lake, but it also can help you save tons of ETL effort to avoid staging the ADLS data while loading your DW.
As the diagram shows, you can also provision an Azure Spark runtime under a Synapse workspace. This opens the possibility for using Azure Spark/Databricks for data transformation and data science. For example, a data scientist can create notebooks in Synapse Studio that use a programming language of their choice (SQL, Python, .NET, Java, Scala, and R are currently supported).
The Bad
You have two coding options with Synapse.
You can use the respective development environment, such as Azure Data Factory Studio for ADF development and Power BI Desktop for Power BI report development.
You can use Synapse Studio which attempts to centralize coding in one place.
Besides the ADLS integration and notebooks, I find no advantages in the Synapse Studio “unified experience”, which is currently in preview. In fact, I found it confusing and limiting. The idea here is to offer an online development environment for coding and accessing in one place all artifacts surrounding your DW project. Currently, these are limited to T-SQL scripts, notebooks, Azure Data Factory pipelines, and Power BI datasets and reports.
However, I see no good reason to abandon the ADF Studio and do ETL coding in Synapse Studio. In fact, I can only see reasons against doing so. For example, Synapse Studio lags in ADF features, such as source code integration and wrangling workflows. For some obscure reason, Synapse Studio separates data flows from ADF pipelines in its own Data Flows section in the Development Hub. This is like putting the SSIS data flow outside the package. Not to mention that inline data flows should be deemphasized since ELT (not ETL) is the preferred pattern for loading Azure Synapse. To make things worse, once you decide to embrace Synapse Studio for developing ADF artifacts, you can use only Synapse Studio because the ADF pipelines are not available outside Synapse.
On the Power BI side of things, you can create a Power BI dataset in Synapse Studio. All this saves is the effort to go through two Get Data steps in Power BI Desktop to connect to your Azure Synapse endpoint. You can also create Power BI reports using Power BI Embedded in Azure Synapse. Why would I do this outside Power BI Desktop is beyond me. Perhaps, I’m missing the big picture and more features might be coming as Synapse evolves. Speaking of evolution, as of this time, only SQL pools are generally available. Everything else is in preview.
The Ugly
Developers moving from on-prem BI implementations to Azure Synapse, would naturally expect all SQL Server features to be supported, just like moving from on-prem SSAS to Azure AS. However, they will quickly find that Azure Synapse is “one of a kind” SQL Server. The nice user interface in SSMS for carrying out admin tasks, such as creating logins and assigning logins to roles, doesn’t work with Azure Synapse (all changes require T-SQL). SQL Profiler doesn’t work (tip: use the Profiler extension in Azure Data Studio for tracing queries in real time).
Because Azure Synapse uses Azure SQL Database, it’s limited to one physical database, so you must rely on using schemas to separate your staging and DW tables. There are also T-SQL limitations, such as my favorite MERGE for ELT-based UPSERTs is not yet supported (currently in preview for hash and round-robin distributed tables but not for replicated tables, such as dimension tables). So, don’t assume that you can seamlessly migrate your on-prem DW databases to Synapse. Also, don’t assume that your SQL Server knowledge will suffice. Prepare to seriously study Azure Synapse!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-08-23 12:48:212020-08-25 11:01:52Azure Synapse: The Good, The Bad, and The Ugly
In partnership with Microsoft, I’m delivering a complimentary, one-day, Analytics in a Day virtual workshop on August 20th, 9 AM – 5 PM Eastern Time. Targeting BI developers, architects and technology decision makers interested in achieving a single version of truth with organizational BI, this workshop is designed to guide and accelerate your journey towards a modern data warehouse to power your business with Azure Synapse, Azure Data Factory, Azure Data Lake, and Power BI.
The first half of the day from 9 am – 1 pm will help you better understand how to:
Create an analytics solution that goes from data ingestion to insights using Azure Synapse Analytics and Power BI
Empower self-service analytics
Enable a truly data-driven culture in your business
Part of the workshop will be dedicated to hands-on training to help you get started on your cloud analytics journey.
The second half of the day from 1 pm – 5 pm is optional and will focus on best practices around designing Power BI + Azure Synapse Analytics BI solutions to enable “Discipline at the core and flexibility at the edge“.
Say goodbye to data silos. Analytics in a Day is designed to simplify and accelerate your journey towards a modern data warehouse to power your business. Reserve your seat today at http://bit.ly/aid202008.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-08-11 14:49:432020-08-11 14:49:43Presenting Analytics in a Day Workshop on August 20th
I’m preparing to teach the brand new Analytics in a Day course by Microsoft. This course emphasizes the business value and technical fundamentals for implementing a modern cloud DW using Azure Synapse, ADF, Data Lake, and Power BI. The second half of the class is focused on Power BI and its role for creating organizational semantic models and self-service models from Synapse. I liked the best practices that Microsoft shares based on how they’ve adopted BI over years and challenges they faced with self-service BI, including:
Inconsistent data definitions, hierarchies, metrics, KPIs
Analysts spending 75% of their time collection and compiling data
78% of reports being creating in “offline environments”
Over 350 centralized finance tools and systems
Approximately $30M annual spend on “shadow applications”
Indeed, many vendors tout only self-service BI which can quickly lead to chaos. By contrast, I have found that most successful data-driven organizations have both organizational and self-service BI.
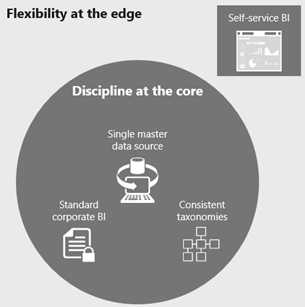
Microsoft calls the collection of these best practices “Discipline at the Core, Flexibility at the Edge“.
“Discipline at the Core” is organizational BI where IT retains control to:
Deliver standardized and performant corporate BI (single version of truth)
Define consistent taxonomies, hierarchies, and KPIs
Enforce data permissions centrally.
“Flexibility at the Edge” is self-service BI where data analysts:
Quickly create reports sourced from trusted data
Mashup core data with departmental data
Create new metrics and KPIs relevant to their part of the business
I further recommend the 80/20 rule as a rough guideline, where most of the effort (as much as 80%) goes into integration and curating the data, implementing enterprise models, and enforcing security, and 20% is left for the agility of self-service BI.
Is your organization disciplined at the core, or is the core missing as a result of blind adherence to the self-service BI mantra?
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-08-06 12:02:122020-08-06 14:04:19Discipline at the Core, Flexibility at the Edge