Prologika Newsletter Winter 2014
 After an appetizer of embedded Power View reports , Microsoft proceeded to the main course that is a true Christmas gift – a pubic preview of what’s coming in its Power BI offering. For the lack of a better term, I’ll call it Power BI.NEXT. In this newsletter, you’ll see why Power BI.NEXT is much more than just an incremental release of the Office 365 Power BI, as you might have thought after reading the Microsoft announcement. As a participant in the private preview, I’m really excited about the new direction and the capabilities it opens.
After an appetizer of embedded Power View reports , Microsoft proceeded to the main course that is a true Christmas gift – a pubic preview of what’s coming in its Power BI offering. For the lack of a better term, I’ll call it Power BI.NEXT. In this newsletter, you’ll see why Power BI.NEXT is much more than just an incremental release of the Office 365 Power BI, as you might have thought after reading the Microsoft announcement. As a participant in the private preview, I’m really excited about the new direction and the capabilities it opens.
WHY POWER BI.NEXT?
What do the United States of America and Microsoft BI have in common? They both decided to become independent for the welfare of their community. USA by choice. Microsoft BI by market conditions.
After more than a decade working with BI technologies and a variety of customers, I do believe that Microsoft BI is the best BI platform on the market. However, you and I both know that it’s not perfect. One ongoing challenge is that various product groups have had a stake in Microsoft BI since Microsoft got serious about BI (circa 2004). Microsoft management promoted SharePoint as a platform for sharing BI artifacts. Major effort underwent to extend SharePoint with SSRS in SharePoint integration mode, PerformancePoint, Power Pivot, etc. But the hefty price tag of SharePoint and its complexity barred the adoption of BI on premises. Power BI for Office 365 alleviated some of these issues but many customers find its kitchen sink approach too overwhelming and cost-prohibitive if all they want is the ability to deploy BI artifacts to the cloud.
Similarly, seeking more market share and motivation for customers to upgrade, Excel added Power Pivot and Power View and was promoted as the Microsoft premium BI tool on the desktop. But adding new BI features to Microsoft Office turned out to be a difficult proposition. A case in point – it’s been two years since DAXMD got released and Power View in Excel 2013 still doesn’t support Multidimensional. In addition, because self-service BI was added to Excel later on, business users find it difficult to navigate the cornucopia of features. For example, there are at least three ways to import data in Excel (Excel native data import capabilities, Power Pivot, and Power Query).
Meanwhile, new self-service BI players entered the marketplace which was previously dominated by mega players. Although lacking technologically in their offerings, they gain in agility, simplicity, vendor neutrality, and aggressive pre-sales support. It appears that these market conditions caused a major shift in the Microsoft BI cloud vision that culminated in POWER BI.NEXT.
WHAT’S DIFFERENT?
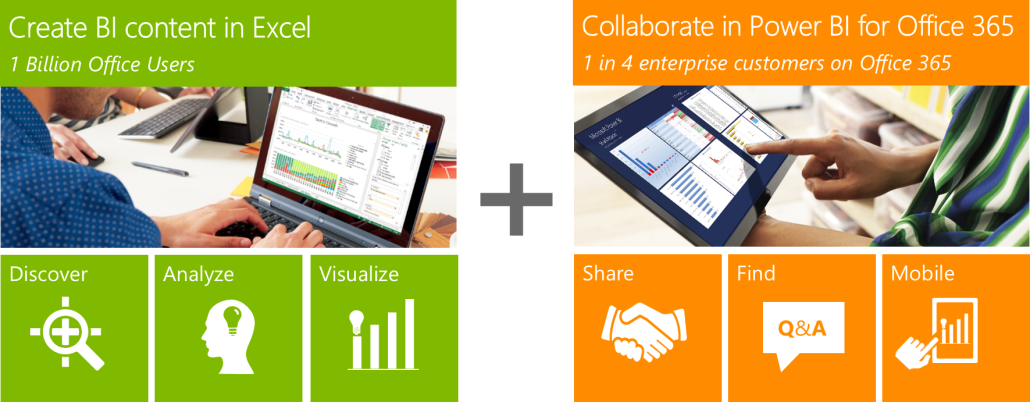
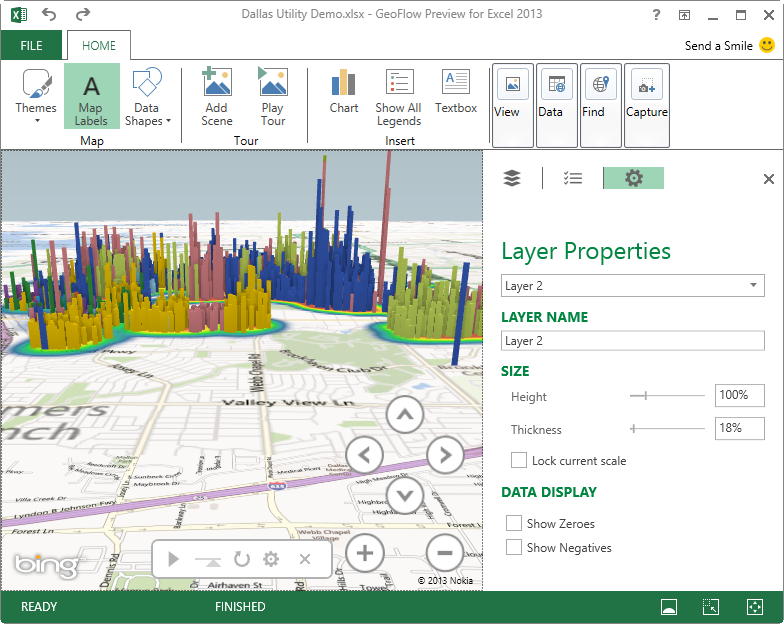
In my opinion, the main difference between Power BI.NEXT and Power BI for Office 365 is that Power BI.NEXT removes the Excel, SharePoint, and Office 365 adoption barriers. On the desktop, it introduces the Power BI Designer – a new BI design tool that unifies Power Query, Power Pivot, Power View and Power Map in a single environment that runs completely outside Excel (Excel BI features are still available for Excel users). Power BI Designer targets business users willing to create self-service data models and dashboards. Powered by Power Query, the designer simplifies data acquisition from a plethora of data sources.
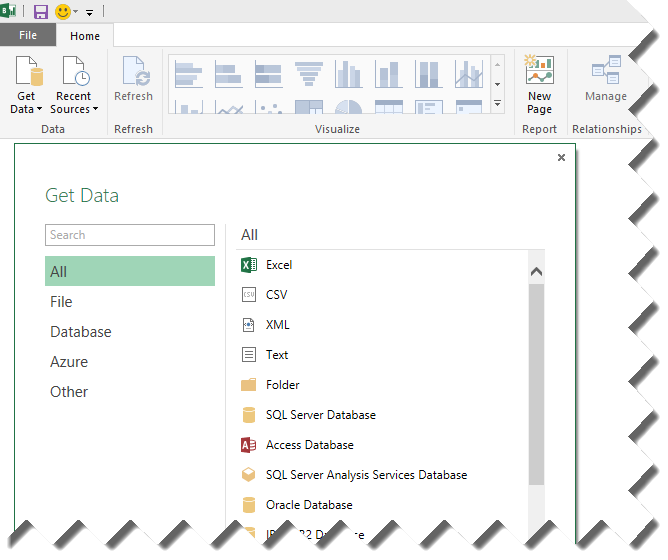
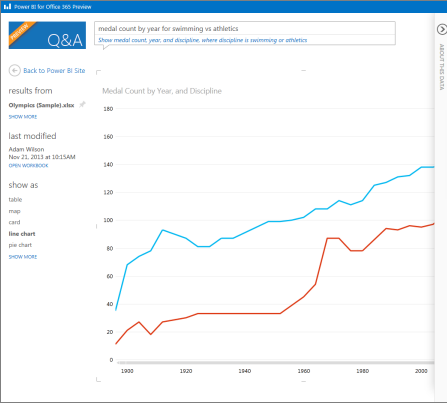
Similar to Power Pivot, Power BI Designer imports data (it seems that the preview version always imports data) into the xVelocity in-memory store backed up by a file in a zip format for durable storage (*.pbix file extension). For reporting, it uses integrated Power View reports that now render by default in HTML5 (if you inspect the page source of a deployed dashboard you’ll see that it uses jquery, angular, and the rest of the mobile dev stack) and natural Q&A (first introduced in Power BI for Office 365).
Another welcome addition is new visualizations that have been demonstrated in many public events, including funnel charts, tree maps, gauges, and others. Although the designer still doesn’t support this feature, the deployed dashboards demonstrate navigation to other report views for more detailed analysis. Unfortunately, action-based drillthrough and conditional formatting are not supported at this point).
Yet another great feature is the ability to connect dashboards deployed to the cloud to on-premise organizational Tabular models (support for Multidimensional is expected at a later time). This is great news for Office 365 customers who aren’t willing to move their data to the cloud yet but are OK with having reports in Power BI. This is accomplished by installing a new bridge connector called Analysis Services Connector Preview that runs independently from the Power BI Data Management Gateway which you might have used to refresh Power Pivot models deployed to Power BI for Office 365.
Another indication of the management shift that reflects market realities is the initial focus on native mobile applications for iPad (already available on the Apple Store) and Android.
Last but not least, always catering to developers, Microsoft has big plans. The Power BI Developer page describes the initial REST APIs that are currently in preview. I’m particularly interested in these APIs that will allow us to “integrate rich analytics into your application by embedding Power BI dashboards, tiles and reports” so we don’t have to rely on third-party controls.
WHAT’S NOT TO LIKE?
Although I’m very excited about Power BI.NEXT, there are some important features lacking in the preview. Currently, it’s a cloud-only offering and you can’t deploy it on premise. I hope we don’t have to wait for another management shift for this to happen given that the majority of my customers are not ready for the cloud yet.
Continuing down the list, the preview customization capabilities of Power View are still limited. To meet dashboard requirements more effectively, we need at least basic customization, such as conditional formatting and action-based drillthrough (as supported in SSRS).
As I mentioned previously, the ability to embed reports on web pages, such as to provide customer-facing reporting, is a must too. I hope the new Power BI will be more agile and add these features soon. Meanwhile, give your feedback and vote for the features you need!
As you’d agree, the BI landscape is fast-moving and it might be overwhelming. As a Microsoft Gold Partner and premier BI firm, you can trust us to help you plan and implement your data analytics projects.
Regards,
Teo Lachev
President and Owner
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
EVENTS & RESOURCES
 “Microsoft BI 2014 Review” presentation by Teo Lachev
“Microsoft BI 2014 Review” presentation by Teo Lachev
Applied Excel and Analysis Services e-learning course by Teo Lachev
Atlanta BI Group: “Success in Business Intelligence requires Emotional Intelligence” by Javier Guillen on Jan 26th
 As I’m enjoying my vacation in tropical Cancun, Mexico, I hope you’ve been enjoying the holidays and planning your BI initiatives in 2014. Speaking of planning, you may have heard that Microsoft is working hard on next release of SQL Server, version 2014, which is expected in the first half of next year. Naturally, you may wonder what’s new in the forthcoming release in the BI arena. If so, keep on reading.
As I’m enjoying my vacation in tropical Cancun, Mexico, I hope you’ve been enjoying the holidays and planning your BI initiatives in 2014. Speaking of planning, you may have heard that Microsoft is working hard on next release of SQL Server, version 2014, which is expected in the first half of next year. Naturally, you may wonder what’s new in the forthcoming release in the BI arena. If so, keep on reading. I hope you had a great summer. The chances are that your organization has a centralized data repository, such as ODS or a data warehouse, but you might not use it to the fullest. Do you want a single version of truth? Of course, you do. Do you want to empower your business users to create their own reports and offload reporting effort from IT? I bet this is one of your top requirements. A semantic layer could help you achieve these objectives and much more… In this newsletter, I’ll discuss the importance of having a semantic layer that bridges users and data.
I hope you had a great summer. The chances are that your organization has a centralized data repository, such as ODS or a data warehouse, but you might not use it to the fullest. Do you want a single version of truth? Of course, you do. Do you want to empower your business users to create their own reports and offload reporting effort from IT? I bet this is one of your top requirements. A semantic layer could help you achieve these objectives and much more… In this newsletter, I’ll discuss the importance of having a semantic layer that bridges users and data.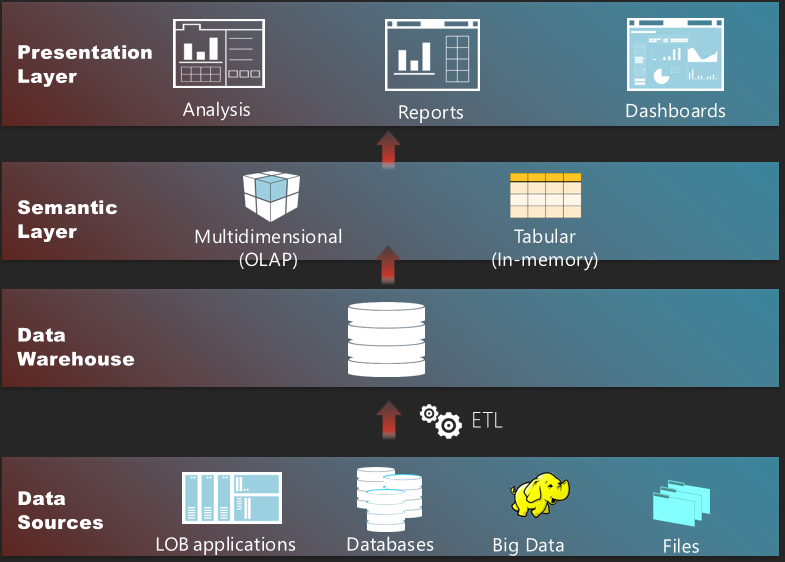

 Many organizations are considering
Many organizations are considering 
 Microsoft
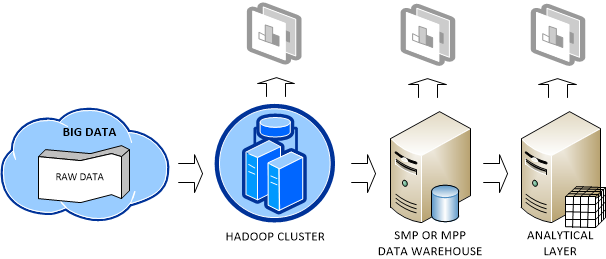
Microsoft  Big Data is getting a lot of attention nowadays. My definition of Big Data is a dataset (or a collection of datasets) that is so large that exceeds the capabilities of a single symmetric multiprocessing (SMP) server and traditional software to capture, manage, and process it within a reasonable timeframe. The boundaries of what defines a “large set” are always shifting upwards, but currently it’s the range of 40-50 terabytes.
Big Data is getting a lot of attention nowadays. My definition of Big Data is a dataset (or a collection of datasets) that is so large that exceeds the capabilities of a single symmetric multiprocessing (SMP) server and traditional software to capture, manage, and process it within a reasonable timeframe. The boundaries of what defines a “large set” are always shifting upwards, but currently it’s the range of 40-50 terabytes.