Prologika Newsletter Q3 2012
Big Data
 Big Data is getting a lot of attention nowadays. My definition of Big Data is a dataset (or a collection of datasets) that is so large that exceeds the capabilities of a single symmetric multiprocessing (SMP) server and traditional software to capture, manage, and process it within a reasonable timeframe. The boundaries of what defines a “large set” are always shifting upwards, but currently it’s the range of 40-50 terabytes.
Big Data is getting a lot of attention nowadays. My definition of Big Data is a dataset (or a collection of datasets) that is so large that exceeds the capabilities of a single symmetric multiprocessing (SMP) server and traditional software to capture, manage, and process it within a reasonable timeframe. The boundaries of what defines a “large set” are always shifting upwards, but currently it’s the range of 40-50 terabytes.
Big Data can originate from various sources, including web logs (a popular website might generate huge log files), sensors (a motion sensor or temperature sensor, for example), devices (a mobile phone generates plenty of data as you move), and so on. Since data is the new currency of our times, you might not want to throw your data as someone might be willing to pay for it. However, Big Data means also a big headache. You need to decide how to store, manage, and analyze it. In general, the following deployment scenario emerges as a common pattern:
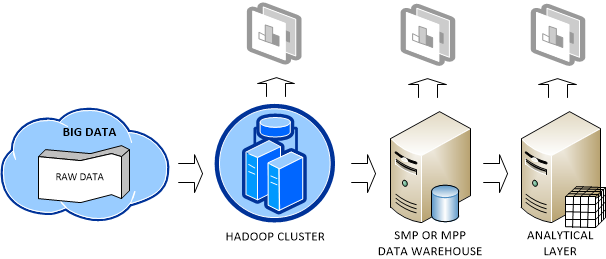
As data accumulates, you might decide to store the raw data in the Hadoop fault-tolerant file system (HDFS). As far as cost, RainStor published an interesting study about the cost of running Hadoop. It estimated that you need an investment of $375 K to store 300 TB which translates to about $1,250 per terabyte before compression. I reached about the same conclusion from the price of single PowerEdge C2100 database server, which Dell recommends for Hadoop deployments.
Note I favor the term “raw data” as opposed to unstructured data. In my opinion, whatever Big Data is accumulated, it has some sort of structure. Otherwise, you won’t be able to make any sense of it. A flat file is no less unstructured than if you use it as a source for ETL processes but we don’t call it unstructured data. Another term that describes the way Hadoop is typically used is “data first” as opposed to “schema first” approach that most database developers are familiar with.
Saving Big Data in a Hadoop cluster not only provides a highly-available storage but it also allows the organization to perform some crude BI on top of the data, such as by analyzing data in Excel by using the Hive ODBC driver, which I discussed in my previous blog. The organization might conclude that the crude BI results are valuable and might decide to add them (more than likely by pre-aggregating them first to reduce size) to its data warehouse running on an SMP server or MPP system, such as Parallel Data Warehouse. This will allow the organization to join these results to conformant dimensions for instantaneous data analysis by other subject areas then the ones included in the raw data.
The important point here is that Hadoop and RDBMS are not competing but completing technologies. Ideally, the organization would add an analytical layer, such as an Analysis Services OLAP cube, on top of the data warehouse. This is the architecture that Yahoo! and Klout followed. See my Why an Analytical Layer? blog about the advantages of having an analytical layer.
The world has spoken and Hadoop will become an increasingly important platform for storing Big Data and distributed processing. And, all the database mega vendors are pledging their support for Hadoop. On the Microsoft side of things, here are the two major deliverables I expect from the forthcoming Microsoft Hadoop-based Services for Windows whose community technology preview (CTP) is expected by the end of the year: A supported way to run Hadoop on Windows. Currently, Windows users have to use Cygwin and Hadoop is not supported for production use on Windows. Yet, most organizations run Windows on their servers. Ability to code MapReduce jobs in .NET programming languages, as opposed to using Java only. This will significantly broaden the Hadoop reach to pretty much all developers.
Regards,
Teo Lachev, MVP (SQL Server), MCSD, MCT, MCITP (BI)
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Business Intelligence
News
 Microsoft awarded Teo Lachev with the Most Valuable Professional (MVP) award for SQL Server for eight years in a row. The Microsoft Most Valuable Professional (MVP) Award is Microsoft way of saying thank you to exceptional, independent community leaders who share their passion, technical expertise, and real-world knowledge of Microsoft products with others. There are less than 200 SQL Server MVPs worldwide.
Microsoft awarded Teo Lachev with the Most Valuable Professional (MVP) award for SQL Server for eight years in a row. The Microsoft Most Valuable Professional (MVP) Award is Microsoft way of saying thank you to exceptional, independent community leaders who share their passion, technical expertise, and real-world knowledge of Microsoft products with others. There are less than 200 SQL Server MVPs worldwide.


