Help Improve Excel as Analysis Services Front End
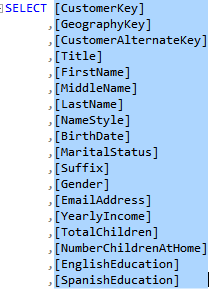
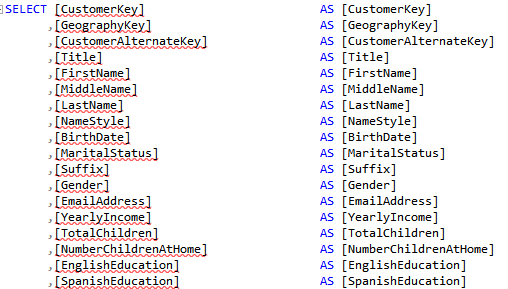
Everyone has a different opinion about what self-service BI should be. But to many people the journey starts and stops with Microsoft Excel. Excel is the self-service BI nirvana. If the user can’t see and filter the detail data, even the most sophisticated self-service BI tool cannot be trusted. And since everyone knows how to do this in Excel, why should they use other tools? To me, the best self-service BI is empowering business users to connect to an organizational semantic model, ideally with Excel as a front end. Most of my current projects use Analysis Services Tabular for implementing semantic models. Therefore, it’s so frustrating that Excel still lacks good support for Tabular. For example, it splits a Tabular table into two tables (“dimension” and “measure group”) because Excel still uses the MDX interface. To make things worse, all fields in the “dimension” table has a Text data type because it gets only the field caption and not the data type. As a result, you can’t filter and compare date and number fields from the “dimension” tables.
According to Microsoft, a better Excel-Tabular combo hasn’t yet bubbled up high based on the feedback that the Excel team gets from customers. In an attempt to get the proper attention, I just posted the “Better Support for Analysis Services Tabular” wish list on Excel User Voice. I bundled multiple items into one wish list.
Please vote if you care.
It’s about time to improve support for SSAS Tabular:
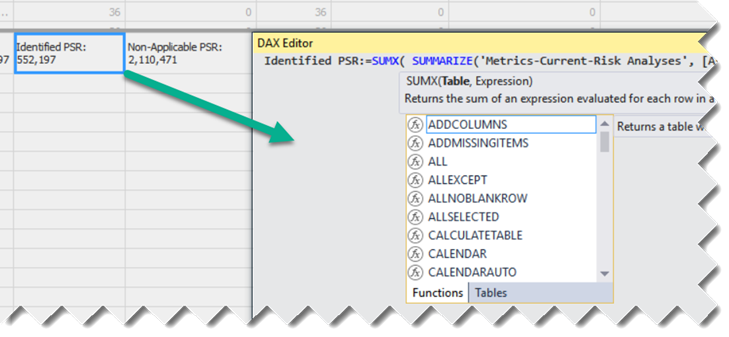
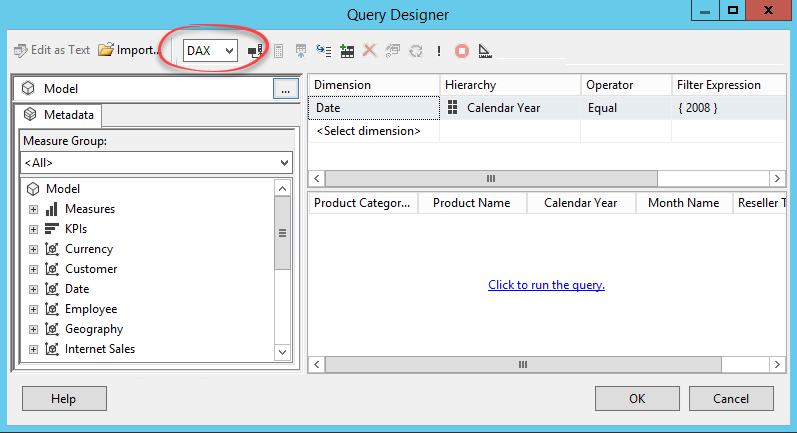
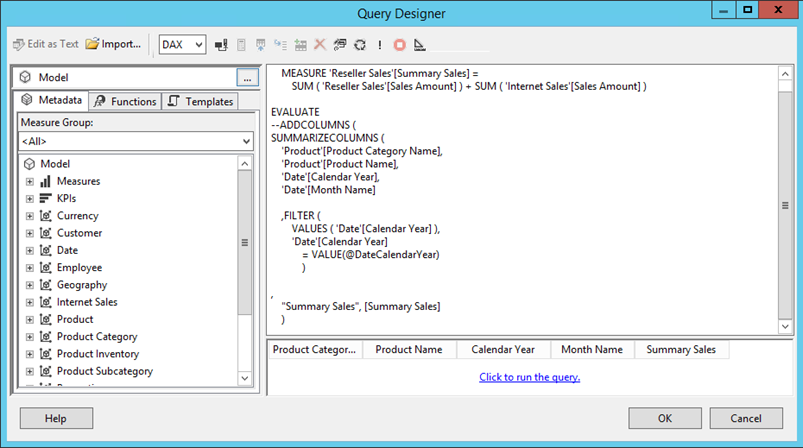
1. Auto-generate DAX.
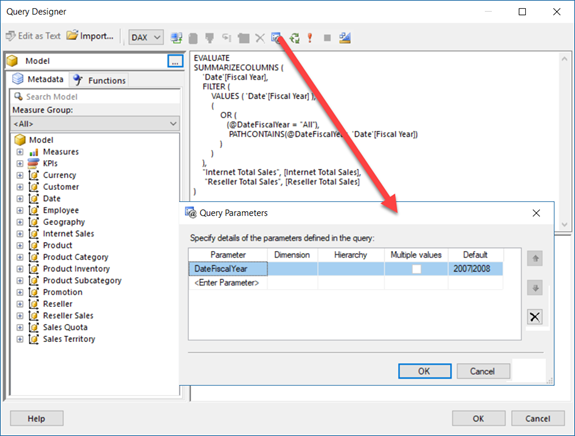
2. Avoid splitting a table into a “measure group” and “dimension”. See how PBI Desktop handles metadata.
3. Carry over data types so that users can create reports, such as show me invoices where Due Date is greater than … Currently, all dimension table fields map to Text.
4. Many customers have expressed interest in connecting Excel tables directly to Tabular, bypassing Pivot Table, so they can use the column dropdowns and other Excel Table goodness.
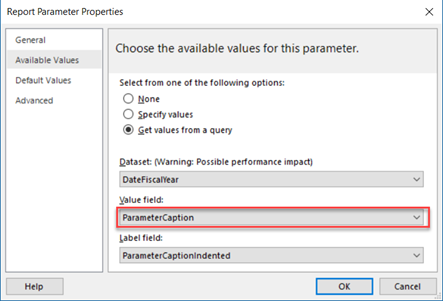
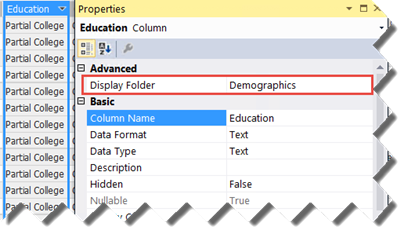
5. Support descriptions as tooltips when the user hovers on a field in the Field List.