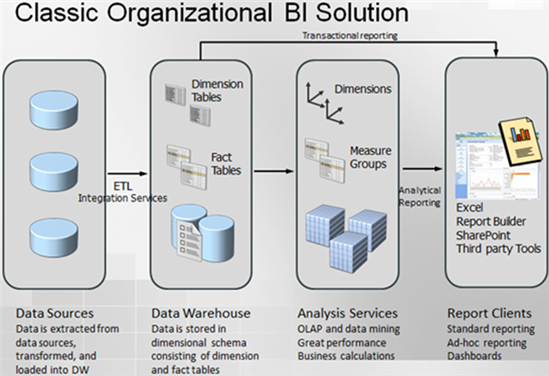
Query Options for Analytical Models and Transactional Reporting
Requesting both historical and transactional reports is a very common requirement. As they stand, neither Multidimensional nor Tabular are designed to support well transactional (detail-level) reporting with large datasets, as I discussed in my Transactional Reporting with Tabular blog post. There are two query options that might provide some relief with transactional reporting and they both have limitations.
DRILLTHROUGH QUERIES
You can use a DRILLTHROUGH query to request data at the lowest level. The syntax differs somewhat between Multidimensional and Tabular. Here is a sample drillthrough query to Adventure Works cube:
DRILLTHROUGH MAXROWS 1000
SELECT FROM [Adventure Works]
WHERE ([Measures].[Reseller Sales Amount],[Product].[Category].[Accessories],[Date].[Calendar Year].&[2006])
RETURN
[$Product].[Product],
[$Date].[Date],
[Reseller Sales].[Reseller Sales Amount],
[Reseller Sales].[Reseller Tax Amount]
And a similar query to Adventure Works Tabular:
DRILLTHROUGH MAXROWS 1000
SELECT FROM [Model]
WHERE ([Measures].[Reseller Total Sales],[Product].[Category].[Category].&[Accessories],[Date].[Calendar].[Year].&[2005])
RETURN
[$Product].[Product Name],
[$Date].[Date],
[$Reseller Sales].[Sales Amount],
[$Reseller Sales].[Tax Amount]
Notice that the WHERE clause specifies the coordinate that is drilled through. The optional RETURN statement enumerates the columns you need in the output with dimensions prefixed with a dollar sign. Since Tabular doesn’t have measure groups, you treat all tables as dimensions.
Drillthrough queries are very fast. They honor the data security (both dimension data security in Multidimensional and Row Filters in Tabular). Not allowed members simple don’t exist as far as DRILLTHROUGH is concerned. For example, attempting to request a dimension member outside the allowed set would return the following error:
Drillthrough failed because the coordinate identified by the SELECT clause is out of range.
This is the same error you will get if your request a non-existent or wrong dimension member.
DRILLTHROUGH queries have limitations:
- You can’t request measures from different measure groups in Multidimensional, such as Internet Sales and Reseller Sales. If you attempt to do so, you’ll get the following error:
Errors from the SQL query module: Drillthrough columns must belong to exactly one measure group. The columns requested by the drillthrough statement are referencing multiple measure groups. - The WHERE coordinate must resolve to a single coordinate. In other words, you can’t specify a set, such as {[Product].[Category].[Accessories],[Product].[Category].[Bikes]. You can avoid the error by using SUBSELECT instead of WHERE but you’ll find that the SUBSELECT clause doesn’t set the default member and you’ll get all products. This limitation will prevent you from using multi-select parameters in SSRS.
- Related to the previous item, you can’t specify FILTER conditions either, e.g. where the transaction date is between a range of dates. Again, you can only use a tuple in the WHERE clause.
- You must use the Analysis Services OLE DB provider in SSRS. If you need to parameterize the query, you need to use an expression-based query statement.
SQL QUERIES
You can also use SQL-like queries as Chris Webb explains in the “Can I run SQL against an Analysis Services cube?” blog. Here is a SQL query against the Adventure Works cube:
select
[Adventure Works].[$Customer].[City],
[Adventure Works].[Internet Sales].[Internet Sales Amount]
from [Adventure Works].[Internet Sales]
natural join [Adventure Works].[$Date]
natural join [Adventure Works].[$Customer]
where [Adventure Works].[$Date].[Calendar Year] = ‘CY 2008’
SQL queries have limitations as well:
- You must specify SQLQueryMode=DataKeys in the connection string if you connect to Tabular.
- SQL queries don’t work with data security (row filters) in Tabular but they appear to work with dimension data security in Multidimensional. Attempting to execute a SQL query against a Tabular model with row filters will throw the following exception:
Tabular queries are not supported with row level security. - Unlike T-SQL, SSAS SQL queries support only the equal operator. Anything else and you’ll get the following error. This limitation precludes more complicated filtering, such as returning only transactions within a given date range.
Errors from the SQL query module: There is an unexpected operator in the WHERE clause. Only the Equals operator ( = ) is supported. - You must use the Analysis Services OLE DB provider in SSRS. Unlike DRILLTHROUGH, you can use AND in the WHERE clause to support multi-valued parameters. However, since the Analysis Services OLE DB provider doesn’t support parameters, you must resort to using an expression-based query statement.
Feel-free to join me to escalate this issue to Microsoft because historical and transactional reporting are both very common scenarios. Thanks to its in-memory nature and more relaxed schema requirements, Tabular is best positioned to support both in a long run so I hope that Microsoft will make improvements in this area. For now, when SSAS doesn’t give you the performance you need, consider delegating transactional reporting to the Database Engine.