Tableau Prep vs. Power Query
After a few years of extensive development and beta testing, Tableau announced its data preparation tool (Tableau Prep) for “redefining your data prep experience”. Previously, Tableau relied on other vendors, such as Alteryx, for self-service data preparation. Naturally, I wanted to take it for a spin and compare it with the Microsoft Power Query (available for free in Power BI Desktop and Excel), which has been around since January 2013. Power Query was initially introduced as an Excel add-on but now it’s available in both Excel and Power BI Desktop. For those of you pressed for time, here is the gist:
| Criteria | Power Query | Tableau Prep |
| Price | Free | $70/user/month for Creator bundle |
| Integration | Integrated with Power BI and Excel | Stand-alone (with preview in Tableau Desktop) |
| Prepackaged Connectors | 70 | 26 |
| Custom Connectors | Yes | No |
| Row-level transformations | Keep rows, remove rows, remove duplicates, promote headers, group by, merge, append, pivot, transpose, combine files | Pivot, join, union |
| Column-level transforms | Copy, remove, duplicate, column from example, calculated column, remove, remove duplicates, remove errors, change type, rename, transform (lower, upper, trim, etc.), replace values, replace errors, split column, index column, group by, fill, pivot, move, format, extract, number column (statistics, standard, scientific, math), date and time column, R script | Filter (formula required), group and replace, clean (upper, lower, trim, remove characters), split, rename, remove, calculated field |
| Interactive graphical step flow | No (static Query Dependencies diagram) | Yes |
| Parameters | Yes | No |
| Use R for data prep | Yes | No |
| User-created tables | Yes | No |
| Detect and expand relationships in data source | Yes | No (one data source at the time) |
| Functions (to centralize common logic) | Yes | No |
| Script (all transformations in one place) | Yes | No |
| Calculation language | Power Query M language | Tableau calculation language |
| Output destination | Directly into PBI data model, Excel sheet (Power Query in Excel only) | Save as TDE, Hyper, CSV, preview in Desktop |
| Output options | One table in the model per query (typically) | One output from Tableau Prep file (Tableau model can’t handle multiple tables) |
It’s clear that Tableau Prep is far behind the Power Query capabilities and has a lot of catching up to do. I took Tableau Prep for a quick ride to do simple data prep. The goal was to cleanse the geo table in the bi_dimensions Excel file that Microsoft provides as sample data for Dashboard in a Day (DIAD) workshops.
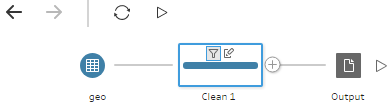
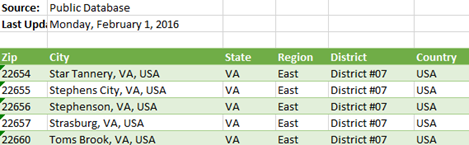
The geo table has a small (but common) issue because it has some extra rows that appear before the main dataset. These rows needs to be removed and the labels in the forth row needs to be promoted as column headers. Simple right?
In Power Query, you can quickly filter out top or bottom rows. No formulas or functions required. There wasn’t such a feature in Tableau Prep. I had to use a column filter (requires an expression) to filter out the top three rows. So much about “a drag-and-drop visual experience” and “no scripting required”. I also couldn’t find a feature to quickly promote column headers. In my opinion, Power Query is by far more user friendly than Tableau Prep.
After enough wrangling to do what’s simple in Power Query but complicated in Tableau Prep, I wanted to save the results. In Power BI Desktop and Excel, you can conveniently load the transformed data directly into the data model. Then, to reflect the changes in the data source, such as when you get a new file with the same spec, you just refresh to re-import and transform the data. No such integration with Tableau Prep. It’s designed to run the flow manually. And to me the biggest limitation of the tool, which stems from the limitation in the Tableau modeling capabilities, is that everything falls apart when you need multiple tables in your data model. Tableau’s mentality remains “one dataset at the time”.
I’ve noticed people excited about the Tableau Prep graphical interface. While it does help visualizing the flow I’m not sure how much value it really adds given that the steps are sequential, and the tool doesn’t support conditional constraints and branches. But you have pretty icons…without much behind.
While testing the tool, I couldn’t help but ask myself “Why pay hundreds of dollars per user/per year for Tableau Creator when Power BI Desktop is better and free?”
I shared more thoughts about Tableau vs Power BI in my blogs Power BI vs. Tableau (Part 1), Power BI vs. Tableau (Part 2), Power BI vs. Tableau (Part 3), and Tableau Hyper vs. Power BI xVelocity. As usual, I welcome your comments. Tableau fans are welcome too.