Power BI Sharing Is Getting Better
A Power BI training or assessment won’t be complete unless I get hammered on the Power BI sharing limitations. So far, I could only mumble something to the extent of “I agree that Power BI sharing sucks big time”, look for the exit and suggest an unplanned break. Fortunately, it looks like quantitative accumulations from unhappy corporate customers have resulted in qualitative changes as Microsoft is getting serious about addressing these limitations. To me, as it stands today, the Power BI sharing is a classic example of overengineering. Something that could have been easily solved with the conventional and simple folders a la SSRS, morphed into some farfetched “cool” vision of workspaces and apps without much practical value. Let’s revisit the current Power BI sharing limitations to understand why change was due:
- Workspace dependency on Office 365 groups – This results in explosion of workspaces as Power BI is not the only app that creates groups.
- Any Power BI Pro user can create a workspace – IT can’t put boundaries. I know of an organization that resorted to an automated script that nukes workspaces which aren’t on the approved list.
- You can’t add security groups as members – As I discussed in my blog “Power BI Group Security“, different Power BI features have a different degree of support for groups. For example, workspaces didn’t support AD security groups.
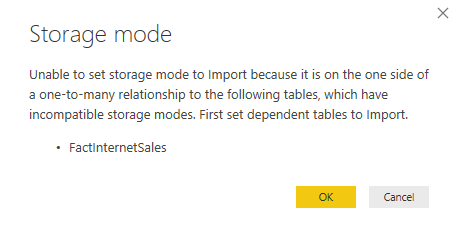
- Coarse content access level – A workspace could be configured for “edit” or “view only” at the workspace level only. Consequently, it wasn’t possible to grant some members view access while others edit permissions.
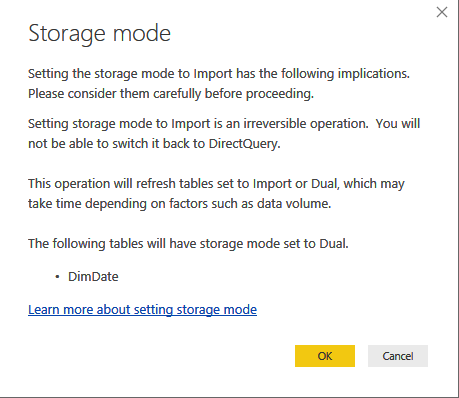
- (UPDATE 6/9/2019: A dataset can now be shared across workspaces)
Content sharing limitations – Content can’t be copied from one workspace to another. Worse yet, content can’t be reused among workspaces. For example, if Teo deploys a self-service semantic model to the Sales workspace, reports must be saved in the same workspace. - No nesting support – Workspace can’t be nested, such as to have a global Sales workspace that breaks down in to Sales North America, Sales Europe, etc. Again, this is a fundamental requirement that any server-side reporting tool supports but not Power BI. You can’t organize content hierarchically and there is no security inheritance. Consequently, you must resort to a flattened list of workspaces.
- (UPDATE 6/9/2019: A dataset can now be promoted and certified).
No IT oversight – There is no mechanism for IT to certify workspace content, such as a dataset. There is no mechanism for users to discover workspace content. - UPDATE 6/27: The new Viewer role supports sharing with viewers.
Sharing with “viewers” – You can’t just add Power BI Free users to share content in a premium workspace. This would have been too simple. Instead, you must share content out either using individual report/dashboard sharing or apps. - One-to-one relationship with apps – Since broader sharing requires apps (why?), an app needs to be created (yet another sharing layer) to share out workspace content. But you can’t publish multiple apps from a workspace, such as to share some reports with one group of users and another set with a different group.
Enough limitations? Fortunately, the new workspace experience immediately solves the first four (highlighted) issues!
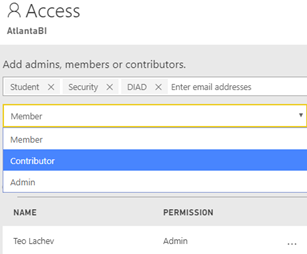
For example, the screenshot below shows how I can add all the O365 group types as members of a workspace (Student is individual member, Security is a security group, and DIAD is a O365 group). Moreover, two new roles, Contributor and Viewer (the Viewer role is not yet available), would further limit the member permissions. So, we finally have member-level security instead of workspace-level security.
What about the other limitations? Microsoft promises to fix them all, but it will take a few more months. Meanwhile, watch the “Distribute insights across the organization with Microsoft Power BI” presentation. So, hopefully by the end of the year I’ll have a much better sharing story to tell after all.