Atlanta MS BI and Power BI Group Meeting on October 30
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on October 30th, Tuesday at 6:30 PM at the Microsoft office in Alpharetta. Neal Waterstreet will tackle the important and pervasive issue of bad data quality. ZAP BI will sponsor the event. And your humble correspondent will introduce you to Power BI Home and data profiling. For more details, visit our group page and don’t forget to RSVP (use the RSVP survey on the main page) if you’re planning to attend.
| Presentation: | Data Quality – Plain and Simple |
| Date: | October 30, 2018, Tuesday |
| Time | 6:30 – 8:30 PM ET |
| Place: | Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900
|
| Overview: | Data quality is a subject that comes up repeatedly in many organizations. Most executives are concerned about the quality of the information used in their decisions. We talk about “good data” and “bad data” but what do those terms mean? In this presentation, we will first define what data quality is and look at how to measure it with data quality dimensions. Then, we’ll explore common causes for data quality issues and how to perform a data quality assessment. Finally, we’ll review the results and discuss some strategies and tools that can help improve the quality of the data in your organization. |
| Speaker: | Neal Waterstreet is a BI Architect/Consultant with Prologika (https://prologika.com) ad he has more than 20 years of industry experience. Neal is skilled in the entire BI spectrum, including dimensional modeling, ETL design and development using Integration Services (SSIS), designing and developing multidimensional cubes and Tabular models using Analysis Services (SSAS) and Master Data Management using Microsoft Data Services (MDS). He’s also involved with the database community with the Atlanta BI and Power BI User Group and the Atlanta Modern Excel User Group. |
| Sponsor: | ZAP’s mission is clear: to connect your business with data. Game-changing insight that impacts business performance only happens when you analyze data by business process or team objective, as opposed to by file type or IT system. This is what ZAP enables. https://www.zapbi.com/ |
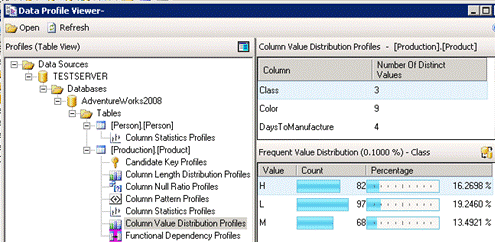
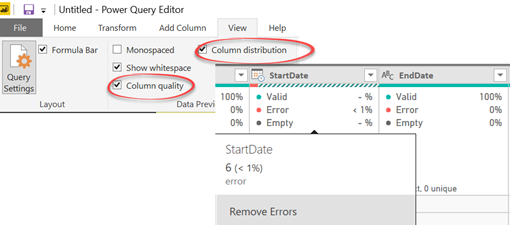
| Prototypes with Pizza | “Power BI Home and data profiling” by Teo Lachev |