Atlanta BI fans, please join us for the next meeting on Monday, August 7th, at 6:30 PM ET. James Serra (Data & AI Solution Architect at Microsoft) will join us remotely to introduce us to Microsoft Fabric. For more details and sign up, visit our group page.
PLEASE NOTE A CHANGE TO OUR MEETING POLICY. WE HAVE DISCONTINUED ONLINE MEETINGS VIA TEAMS. THIS GROUP MEETS ONLY IN PERSON. WE WON’T RECORD MEETINGS ANYMORE. THEREFORE, AS DURING THE PRE-PANDEMIC TIMES, PLEASE RSVP AND ATTEND IN PERSON IF YOU ARE INTERESTED IN THIS MEETING.
Presentation: Introducing Microsoft Fabric
Delivery: Speaker will join us remotely via Teams
Date: August 7th
Time: 18:30 – 20:30 ET
Level: Beginner
Food: Sponsor wanted
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
ONSITE
Improving Office
11675 Rainwater Dr
Suite #100
Alpharetta, GA 30009
Overview: Microsoft Fabric is the next version of Azure Data Factory, Azure Data Explorer, Azure Synapse Analytics, and Power BI. It brings all these capabilities together into a single unified analytics platform that goes from the data lake to the business user in a SaaS-like environment. Therefore, the vision of Fabric is to be a one-stop shop for all the analytical needs for every enterprise and one platform for everyone from a citizen developer to a data engineer. Fabric will cover the complete spectrum of services including data movement, data lake, data engineering, data integration and data science, observational analytics, and business intelligence. With Fabric, there is no need to stitch together different services from multiple vendors. Instead, the customer enjoys end-to-end, highly integrated, single offering that is easy to understand, onboard, create and operate.
This is a hugely important new product from Microsoft, and I will simplify your understanding of it via a presentation and demo.
Speaker: James Serra works at Microsoft as a big data and data warehousing solution architect where he has been for most of the last nine years. He is a thought leader in the use and application of Big Data and advanced analytics, including data architectures, such as the modern data warehouse, data lakehouse, data fabric, and data mesh. Previously he was an independent consultant working as a Data Warehouse/Business Intelligence architect and developer. He is a prior SQL Server MVP with over 35 years of IT experience. He is a popular blogger (JamesSerra.com) and speaker, having presented at dozens of major events including SQLBits, PASS Summit, Data Summit and the Enterprise Data World conference. He is the author of the upcoming book “Deciphering Data Architectures: Choosing Between a Modern Data Warehouse, Data Fabric, Data Lakehouse, and Data Mesh”.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-08-01 11:13:522023-08-01 11:13:52Atlanta Microsoft BI Group Meeting on August 7th (Introducing Microsoft Fabric)
Did I disappoint you? Or leave a bad taste in your mouth? You act like you never had love And you want me to go without
U2
In previous posts, I shared my initial impression of the recently announced Microsoft Fabric and its main engines. Now that we have the Fabric licensing and pricing, I’m ready to wrap up my review with a few parting notes. Here is how I plan to position Fabric to my clients:
Enterprise clients
These clients have complex data integration needs. More than likely, they are already on a Power BI Premium contract and highly-discounted pricing model that is reviewed and renewed annually with Microsoft. Given that Fabric can be enabled on premium capacities, you should definitely consider it selectively when it makes sense. For now, I believe a good case can be made for data lake and lakehouse if that’s your thing.
Now you have an alternative to Databricks and you can standardize BI on one platform and vendor.
I don’t have experience in Databricks to offer more in-depth comparison, but in my opinion the most compelling features to favor Fabric for now are:
No additional cost or Power BI Premium capacity upgrade if you aren’t reaching the workload limits
One platform and one vendor to avoid the blame game when things don’t work
Fast Direct Lake data access for ad-hoc analysis directly on top of files in the lakehouse
Easy data virtualization
If you decide in Fabric’s favor, you’d be wise to reduce dependencies on Microsoft proprietary and bundled features, such as Power Query dataflows and data pipelines insides Fabric (I’d use a stand-alone ADF instance once ADF supports Fabric). Hopefully, bring-your-own-lake will appear on day to circumvent the Fabric OneLake shortcomings.
Small and medium-size clients
Unfortunately, Microsoft didn’t make Fabric available with PPU (premium-per-user) licensing. This would surely put it out of reach for smaller organizations. True, you can purchase a Fabric F2 license for as little as $262/month and run it on a quarter of a core. I didn’t know a quarter of a core existed, but Microsoft did it, although you probably won’t get too far with it for production use (see results from my F2 limited performance tests here). You can opt for a higher SKU, but it would increase your bill and Fabric capacities can’t be auto-paused. For example, a “luxurious” 1 core (F8 plan) will put you in the 1K/month range, plus Power BI Pro licenses for all users (contributors and viewers).
But fear not. There is nothing in Fabric that you desperately need or can’t obtain outside Fabric in a much more cost-effective way.
Expect Microsoft to push Fabric aggressively. However, I believe Fabric has more appeal for large organizations while low-budged simple solutions with Power BI Pro or PPU licensing would likely better address your needs. And your BI solution is still going to be “modern”, whatever that means…
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-07-30 17:28:402024-01-15 15:57:49A First Look at Microsoft Fabric: Recap
In retrospect, I’d say I owe 50% of my BI career to Analysis Services and its flavors: Multidimensional, Tabular, and later Power BI. This is why I closely follow how this technology evolves. Fast forwarding to Fabric, there are no dramatic changes. Unlike the other two Fabric Engines (Lakehouse and Warehouse), Power BI datasets haven’t embraced the delta lake file format to store its data yet. The most significant change is the introduction of a new Direct Lake data access mode alongside the existing Import and DirectQuery.
The Good
Direct Lake will surely enable interesting scenarios, such as real-time BI on top of streaming data. It requires Parquet delta lake files and therefore it’s available only when connecting to the Lakehouse managed area (Tables folder) and Warehouse tables. Given that Parquet is a columnar format, which is what Tabular VertiPaq is, basically Microsoft has changed the engine to read Parquet files as it does with its proprietary IDF file format.
The primary usage scenario is fast analysis on top of large data volumes without importing data and without delegating the query to another server. Therefore, think of Direct Lake is a hybrid between Import and DirectQuery modes. By “large data volumes”, I mean data that otherwise won’t fit into memory and/or it will require substantial time to refresh but low latency access would be preferable.
Microsoft has accomplished this feat by using the following existing and new Analysis Services features:
Vertiscan – The ability for Analysis Services to query columnar storage. Instead of using the IDF file format to store the Vertipaq data, DirectLake instead uses the Parquet file format in Lakehouse or Warehouse. The AS engine loads the data from the Parquet files (with some extra effort) and maps the column values into (mostly) the same data structures that would have been used if the data was coming from IDF files. After that, Vertiscan is querying the data as if it was Import data, so query performance should be at par with Import mode.
On-demand data loading – The ability to page in and out data that was introduced in 2021 for imported data. If the data needs to be paged in, there will be some delay but after that it will be fast until and unless it gets paged out later on. Chris Webb covers on-demand loading in his post On-Demand Loading Of Direct Lake Power BI Datasets In Fabric.
V-order – an extension to the Parquet file format to get a better compression like VertiPaq
The Bad
Naturally, I’d like to see Direct Lake available outside Fabric.
Currently, here is what needs to happen to connect to external Delta Parquet files, such as files located in ADLS:
Create a lakehouse.
Create a shortcut in OneLake to the external source table.
Create the dataset on top of the lakehouse
As you can see, you can’t escape the Fabric gravitational pull to get Direct Lake. Further, the Parquet files produced by the Fabric workloads (Lakehouse/DW/etc.) will typically be faster and more compressed because of the V-order compression.
The Ugly
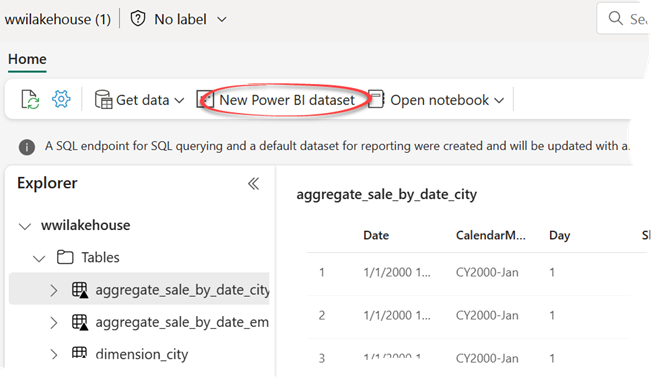
Among the Direct Lake limitations, the most significant for me is that not only you need Fabric to get Direct Lake, but also you must create the dataset online using the “New Power BI dataset” feature in Lakehouse/Warehouse, which has its own limitations.
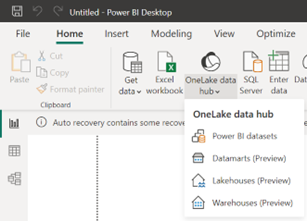
Therefore, for now you can’t use Power BI Desktop to create your semantic model that uses Direct Lake connectivity. This will require Write support to be added to the Analysis Services Power BI XMLA endpoint. However, once you create the Direct Lake dataset, you can use Power BI Desktop to connect to it using the OneLake Data Hub connector.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-07-14 17:52:182023-07-14 18:16:23Fabric Semantic Modeling: The Good, the Bad, and the Ugly
Is it getting better? Or do you feel the same? Will it make it easier on you now? You got someone to blame
U2
Likely influenced by the Gartner’s Fabric vision, Microsoft Fabric is eclipsing all things Power BI nowadays to the extent of replacing the strong Power BI brand and logo with Fabric’s. Now that the red star Synapse has imploded into a black hole, Fabric has taken its place and it’s engulfing everything in its path.
But to digress from Fabric, let’s take a look at two developer-oriented and frequently requested features that fortunately doesn’t require Fabric: Power BI Desktop projects and workspace integration with Git. The video in the link is a good starting point to understand how these features work.
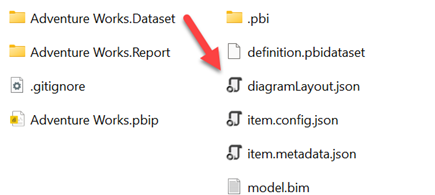
Basically, the first feature lets you save a Power BI Desktop file as a *.pbip file which generates a set of folders with human-readable text files, such as the model.bim file (has the model definition described in JSON). Next, you can put these files under source control using any source control-enabled tool, such as Visual Studio Code or Visual Studio. Currently in preview, Power BI projects is an experimental feature (in fact, the Publish button is disabled so you can’t publish a project to Power BI Service).
The second feature (workspace integration with Git) lets you configure a workspace to keep Power BI reports and datasets published to the workspace under source control. No other items are currently supported (even paginated reports). This feature is independent of the client-side project mode and it doesn’t require saving Power BI Desktop files as projects.
The Good
Although the primary target of PBI Desktop projects is to enable source control, a more useful side effect to me is that we can now get to and edit the report schema.
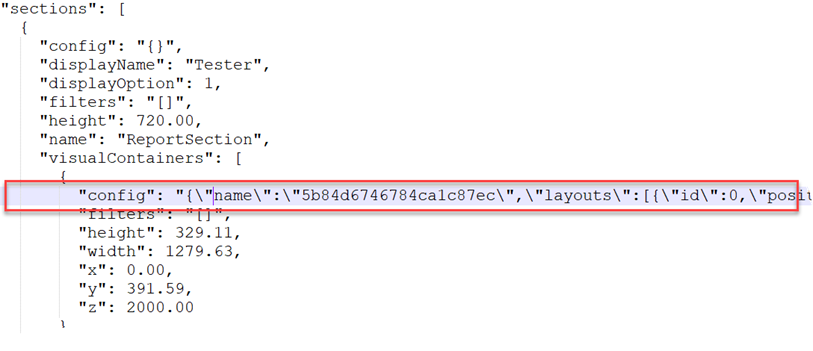
The other day someone asked me how you can apply conditional settings of one field in a visual to another. Or, how can you replace the field that has conditional settings applied without loosing them. Well, with some JSON wizardry, you can open the report.json file and make the changes there. At your risk of course because the report schema is ugly and not documented.
I also commend Microsoft for supporting Power BI workspace Git integration in Premium Per User (PPU) licensing to make it more accessible (unfortunately, it’s not available to the masses operating on Power BI Pro). I like the two-way integration in a Git-enabled workspace. It works like Azure Data Factory, so I don’t have to configure source control on the client.
The Bad
The report JSON schema is not documented and as such source code compare is difficult. Parsing a name-value collection in the visual’s config section is required to get to the useful staff.
I hope at some point Microsoft will simplify and document the report schema to let the community take over where Microsoft left off and create tools to compare the report definition.
Naturally, I’d like to see Git integration supporting all workspace items, such as paginated reports, dashboards, and Fabric artifacts.
The Ugly
If you follow my blog, you know that I’m not a big fan of Power BI Desktop for semantic modeling. Instead, I rely on Tabular Editor. When in pbix mode, changes saved in Tabular Editor appear in Power BI Desktop (the reverse is not true). That’s because Tabular Editor connected to a pbix file actually connects to the running instance of the Analysis Services engine and applies changes there. It edits the same in-memory model that PBI Desktop is connected to, thus allowing PBI Desktop to automatically refresh metadata changes.
By contrast, changes made in Tabular Editor in project mode are not reflected in Power BI Desktop.
That’s because changes made in Tabular Editor in project mode are written to the model.bim file and you need to close and open PBI Desktop for these changes to appear. This can get tedious very quickly. My recommendation would be for Power BI Desktop to listen to file changes and automatically refresh the metadata.
Summary
I’ll wait for the project mode feature to mature on the client. Meanwhile, I’ll continue with *.pbix and enable source control integration at the workspace level for clients on PPU or higher licensing. With Power BI Pro licensing, I’ll continue putting the model.bim file from Tabular Editor under source control (no source control for reports).
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-07-09 13:31:252023-07-18 14:01:40Power BI Projects and Git Integration: The Good, the Bad, and the Ugly
Oops, I did it again I played with your heart Got lost in the game…
Britney Spears
In previous posts, I shared my thoughts about Fabric OneLake, Lakehouse, and Data Warehouse. They are of course useless if there is no way to get data in and out of Fabric. Data integration and data quality is usually the most difficult part of implementing a BI solution, accounting for 60-80% of the overall effort. Therefore, this post is about Fabric data integration options.
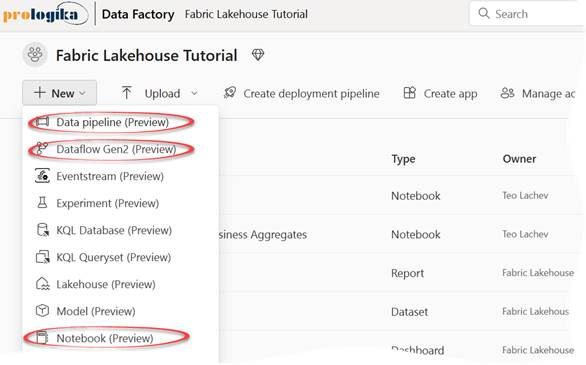
Fabric supports three options for automated data integration: Data Pipeline (Azure Data Factory pipeline), Dataflow Gen2 (Power BI dataflow), and Notebook (Spark). I summarize these three options in the following table, which loosely resembles the Microsoft comparison table but with my take on it.
Data pipeline
(ADF pipeline/copy activity)
Dataflow Gen2
(Power BI dataflow)
Notebook
(Spark)
Primary user
BI developer
Business analyst
Data scientist, Developer
Patterns supported
ETL/ELT
ETL
ETL
Primary skillset
SQL
Power Query
Spark
Data volume
High
Low to medium
High
Primary code language
SQL
M
Scala, Python, Spark SQL, R
Complexity
Medium
Low
High
Vendor lock-in
Medium (minimize with ELT pattern)
High
Low
The Good
We have three options for data integration to support different personas and skillsets. Unlike other “a notebook with a blinking cursor” vendors, data pipeline and dataflow provide no code/low code options.
Power BI dataflows are now supposedly more scalable, which apparently justifies the Gen2 tag. They finally support destinations although the list is limited to Azure SQL Database and the Fabric engines (Lakehouse, Warehouse, and KQL Database).
The Copy activity in Fabric data pipelines now supports creating delta tables although it doesn’t support merges.
The Bad
Microsoft is pushing dataflows to “data engineer, data integrator, and business analyst”. My guidance is to consider dataflows only if you want to open data ingestion to business users (something you must carefully think about and definitely surround it with a log of supervision). As its predecessor (Power BI dataflows), Power Query is notoriously difficult to troubleshoot or optimize. It doesn’t support the ELT pattern (my favorite), such as to handle Type 2 changes. This could be partially ramified by implementing a pipeline that mixes dataflows with other ADF artifacts, such as calling stored procedures in Fabric Warehouse. Moreover, I consider Power Query as a Microsoft proprietary tool, irrespective that the M language is documented. If one day you decide to leave Fabric, you’d need to rewrite your flows. Finally, the only output options supported are append or replace (no update).
Moving to ADF, the copy activity supports only append or replace (no update). Outside Fabric, Azure Data Fabric doesn’t have connectors to connect to Fabric yet.
I personally abhor the idea to put all BI artifacts in Fabric, if not for anything else, but to have a better way out if one day a client decides to part ways with Fabric.
Haven’t we learned anything from Synapse pipelines? Ask Microsoft how to migrate them to Fabric if you have fallen for that “best practice”. I’d carefully weight going all the way with Fabric (I know that bundles are a big incentive) instead of being more independent and use Fabric more selectively.
For data warehousing, which is the primary scenario I personally care about in Fabric, I primarily rely on the ELT pattern for a variety of reasons. I shall miss T-SQL MERGE in Fabric Warehouse, but I plan to leave it to marinate for a year or so anyway.
The Ugly
After all the push to use ADF mapping data flows in Synapse, where are they hiding in Fabric? Alas, they haven’t made it and they were superseded by Power BI dataflows.
This underscores another important reason to use the ETL pattern whenever you can. At least you can salvage your SQL code as a vendor “evolves” or “revolutionizes” their offerings. Which is another way of a vendor saying “oops, we did it again…” and we shall go back to the drawing board.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-07-08 15:49:492023-07-08 15:49:49Fabric Data Integration: The Good, the Bad, and the Ugly
Atlanta BI fans, please join us for the next meeting on Tuesday, July 11th, at 6:30 PM ET. Stacey Jones (Cross Solution Architect at Microsoft) will join us in person to present OpenAI and Copilot. Your humble correspondent will demo the newly released PBI Desktop project format. For more details and sign up, visit our group page.
PLEASE NOTE A CHANGE TO OUR MEETING POLICY. EFFECTIVE IMMEDIATELY, WE ARE DISCONTINUING ONLINE MEETINGS VIA TEAMS. THIS GROUP MEETS ONLY IN PERSON. WE WON’T RECORD MEETINGS ANYMORE. THEREFORE, AS DURING THE PRE-PANDEMIC TIMES, PLEASE RSVP AND ATTEND IN PERSON IF YOU ARE INTERESTED IN THIS MEETING.
Presentation: Azure OpenAI – Answers to Your Natural Language Questions
Date: July 11th (Please note that because of the July 4th holiday, this meeting is on Tuesday)
Time: 18:30 – 20:30 ET
Level: Intermediate
Food: As of now, food won’t be available for this meeting. We are welcoming suggestions for a sponsor.
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
ONSITE
Improving Office
11675 Rainwater Dr
Suite #100
Alpharetta, GA 30009
Overview: We will overview and explore Azure OpenAI, a fusion of OpenAI with the Azure cloud. Understand what OpenAI and CoPilot are as well as how they can help you with your natural language questions. We will also address questions about AI, such as will AI take over the world?
Speaker: Stacey Jones is a Cross Solution Architect specializing in all things Data, AI and Power BI. He is Evangelist at Microsoft’s Technology Center (MTC) in Atlanta, GA. He has 30+ years of industry experience in technology management spanning data architecture, data modeling, database development, tuning, and administration in both Oracle and SQL Server. He is active on LinkedIn and has plenty of real-life experience putting out database performance fires.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-07-05 07:41:242023-07-05 07:41:24Atlanta Microsoft BI Group Meeting on July 11th (Azure OpenAI – Answers to Your Natural Language Questions)
“Patience my tinsel angel, patience my perfumed child One day they’ll really love you, you’ll charm them with that smile But for now it’s just another Chelsea [TL: BI] Monday” Marrillion
Continuing our Power BI Fabric journey, let’s look at another of its engines that I personally care about – Fabric Warehouse (aka as Synapse Data Warehouse). Most of my real-life projects require integrating data from multiple data sources into a centralized repository (commonly referred to as a data warehouse) that centralizes trusted data and serves it as a source to Power BI and Analysis Services semantic models. Due to the venerable history of relational databases and other benefits, I’ve been relying on relational databases powered by SQL Server to host the data warehouse. This usually entails a compromise between scalability and budget. Therefore, Azure-based projects with low data volumes (up to a few million rows) typically host the warehouse in a cost-effective Azure SQL Database, while large scale projects aim for Synapse SQL Dedicated Pools. And now there is a new option on the horizon – Fabric Warehouse. But where does it fit in?
The Good
Why would you care about Fabric Warehouse given that Microsoft has three (and counting) Azure SQL SKUs: Azure SQL Database, Azure SQL Managed Instance, and Synapse SQL Dedicated Pools (based on Azure SQL Database)? Ok, it saves data in an open file format in OneLake (delta tables), but I personally don’t quite care much about how data is saved. We could say that SQL Server is also (although proprietary) a file-based engine that served us well for 30+ years. I care much more about other things, such as performance, budget, and T-SQL parity. However, as I mentioned in the previous Fabric-related blogs, the common delta format across Fabric enables data virtualization, should you decide to put all your eggs in one basket and embrace Fabric for all your data needs. Let’s say you have some files in the lakehouse managed zone. You can shortcut lakehouse delta tables to the Data Warehouse engine and avoid data movement. By contrast, previously you had to spin more ETL to move data from the Synapse serverless endpoint to the Synapse dedicated pools.
A big improvement is that you can also cross-query data warehouses and lakehouses, which wasn’t previously possible in Azure Synapse.
You can do this by writing familiar T-SQL queries with three-part-naming, such as querying a lakehouse table in your warehouse:
SELECT TOP (100) * FROM [wwilakehouse].dbo.dimension_customer
In fact, the elimination (or rather fusion) of Synapse Dedicated Pools and Serverless is a big plus for me. The infinite scale and instantaneous scalability that resulted from decoupling compute and store sounds interesting. I don’t know how Fabric Warehouse will evolve over time but I really hope that at some point, it will eliminate the afore-mentioned Azure SQL SKU decision for hosting relational data warehouses. I hope it will support the best of both worlds – the ability to dynamically scale (as serverless Azure SQL Database) up to the large scale of Synapse Dedicated Pools.
The Bad
Now that Azure SQL SKUs are piling up, Microsoft owes us serious benchmarks for Fabric Warehouse analytical and transactional loads.
Speaking of loads and considering that Fabric Warehouse saves data in columnar structures (Parquet files), this is not a tool to use for heavy OLTP loads. Columnar formats fit data analytics like a glove when data is analyzed by columns, but they will probably perform poorly for heavy transactional loads. Again, benchmarks could help determine where that cutoff point is.
Unlike Power BI Premium (P) capacities, Fabric capacities acquired by purchasing an Azure F plan can be scaled up or down (like Power BI Embedded A* plans). However, like A* plans, this requires manual intervention. I was hoping for dynamically scaling up and down workloads within a capacity to meet more demand and reduce cost. For example, I should be able to configure the capacity to auto-pause Fabric Warehouse when it is not in use and the data is imported in a Power BI dataset.
As I mentioned in my Fabric Lakehouse: The Good, The Bad, and the Ugly post, given that both saves data in the same format, I find the Lakehouse and Warehouse engines redundant and confusing. Currently, ADLS shortcomings are implicated for this separation and my hope is that at one point they will merge. If you are a SQL developer, you should be able to use SQL, and if you prefer notebooks for whatever reason, you can use Python or whatever language you prefer on the same data. This will be really nice and naturally resolve the lakehouse-vs-warehouse decision point.
The Ugly
Due to the fact that it’s completely rewritten, a work in progress, and therefore subject to many limitations, as it stands Fabric Warehouse is unusable for me.
After the botched Synapse saga, Microsoft had the audacity to call this offering the next generation of Synapse warehouse (in fact, the Fabric architecture labels is as Synapse Data Warehousing, I guess to save face) despite the fact that they pretty much start from scratch at least in terms of features. I call it “Oops, we did it again, overpromised and underdelivered, got lost in the game, Ooh, baby, baby…” I’ll give Fabric Warehouse a year or so before I revisit. If my hope for Fabric Warehouse as a more straightforward choice for warehousing materializes, I also wish Microsoft decouples it from Fabric and makes it available as a standalone Azure SKU offering. Which is pretty much my wish for all tools in the Fabric bundle. Bundles are great until you decide to opt out and salvage pieces…
Finally, after all the push and marketing hoopla, Synapse SQL Dedicated Pools seems to be on an unofficial deprecated path. I guess Microsoft has seen the writing on the wall from competing with other large-scale DW vendors. The current guidance is to consider them for high-scale performance while the “evolved” and “rewritten” Fabric Synapse Warehouse should be at the forefront for future DW implementations. And there is no migration path from Dedicated SQL Pools.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-07-03 13:42:312024-06-18 16:19:47Fabric Data Warehouse: The Good, The Bad, and the Ugly
“Hey, I got this lake house, you should see it It’s only down the road a couple miles I bet you’d feel like you’re in Texas I bet you’ll wanna stay a while” Brad Cox
Continuing our Fabric purview, Lakehouse is now on the menu. Let’s start with a definition. According to Databricks which are credited with this term, a data lakehouse is “a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.” Further, their whitepaper “argues that the data warehouse architecture as we know it today will wither in the coming years and be replaced by a new architectural pattern, the Lakehouse, which will (i) be based on open direct-access data formats…” In other words, give us all of your data in a delta lake format, embrace our engine, and you can ditch the “legacy” relational databases for data warehousing and OLAP.
The Microsoft’s Lakehouse definition is less ambitious and exclusive. “Microsoft Fabric Lakehouse is a data architecture platform for storing, managing, and analyzing structured and unstructured data in a single location. It is a flexible and scalable solution that allows organizations to handle large volumes of data using a variety of tools and frameworks to process and analyze that data. It integrates with other data management and analytics tools to provide a comprehensive solution for data engineering and analytics”. In other words, a lakehouse is whatever you want it to be if you want something better than a data lake.
The Good
I like the Microsoft lakehouse definition better. Nobody forces me to adopt an architectural pattern that probably won’t stand the test of time anyway.
If I must deal with files, I can put them in the lakehouse unmanaged area. The unmanaged area is represented by the Files virtual view. This area somehow escapes the long-standing Power BI limitation that workspaces can’t have subfolders and therefore allows you to organize the files in any folder structure. And if I want to adopt the delta lake format, I can put my data in the lakehouse managed area, which is represented by the Tables virtual view.
Further, the Fabric lakehouse automatically discovers and registers delta lake tables created in the managed area. So, you can use a Power Query dataflow or ADF Copy Activity to write some data in a delta lake format and Fabric will register the table for you in the Spark metastore with the necessary metadata such as column names, formats, compression and more (you don’t have use Spark to register the table). Currently, the automatic discovery and registration is supported only for data written in the delta lake format.
You get two analytical engines for the price of one to query the delta tables in the managed area. Like Synapse Serverless, the SQL endpoint lets users and tools query the delta tables using SQL. And the brand new DirectLake mode in Analysis Services (more on this in a future post) lets you create Power BI datasets and reports that connect directly to the delta tables with blazing speed so you don’t have to import to get better performance.
Finally, I love the ability to shortcut lakehouse tables to the Data Warehouse engine and avoid data movement. By contrast, previously you had to spin more ETL to move data from Synapse serverless endpoint to the Synapse dedicated pools.
The Bad
As the most lake-like engine, Fabric lakehouse shares the same limitations as the Fabric OneLake which I discussed in a previous post.
Going quickly through the list, the managed area (Tables) can’t be organized in subfolders. If you try to paint outside the “canvas”, the delta tables will end up in an Unidentified folder and they won’t be automatically registered. Hopefully, this is a preview limitation since I don’t see you can implement a medallion file organization if that’s your thing. Further, while you can create delta tables from files in the unmanaged area, the tables are not automatically synchronized with changes to the original files. Automatic delta table synchronization could be very useful that I hope will make its way to the roadmap.
The Microsoft API wrapper that sits on top of OneLake is married to the Power BI security model. You can’t overwrite or augment the security permissions, such as by granting ACL permissions directly to the lakehouse folders. Even Shared Access Signature is not allowed. Storage account key is not an option too as you don’t have access to the storage account. So, to get around such limitations, you’d have to create storage accounts outside Fabric, which defeats the OneLake vision.
It’s unclear how Fabric would address DevOps, such as Development and Production environments. Currently, a best practice is to separate all services so more than likely Microsoft will enhance Power BI pipelines to handle all Fabric content.
The Ugly
Given that both the lakehouse and data warehouse (new Synapse) have embraced delta lake storage, it’s redundant and confusing to have two engines.
The documentation goes in length to explain the differences but why the separation? Based on what I’ve learned, the main reason is related to ADLS limitations to support important SQL features, including transactions that span multiple tables, lack of full T-SQL support (no updates, limited reads) and performance issues with trickle transactions. Hopefully, one day these issues will be resolved and the lakehouse and data warehouse will merge to give us the most flexibility. If you know SQL, you’d use SQL and if you prefer notebooks, you can use the Spark-supported languages to manipulate the same data.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-06-25 12:27:322023-09-01 12:42:18Fabric Lakehouse: The Good, The Bad, and the Ugly
Enterprise Resource Planning (ERP) systems capture a wealth of information from main business processes within an organization, such as Sales, Inventory, Orders, etc. Therefore, a BI journey typically starts with analyzing the ERP data, with revenue analytics usually taking the center stage because of its vital metrics, such Revenue, Margin, Profit. In fact, this scenario has repeated so often for the past few years that Prologika has developed a fast-track implementation for ERP analytics. The client presented in this case study had more complicated integration needs, but other projects for both larger and smaller clients in the same or other industries have benefited from the same methodology.
Business Needs
The client manufactures and distributes electrical components. The company has grown rapidly through acquisitions, with every business unit having its own ERP system, including Dynamics and other business-specific ERPs. Some ERPs were installed on premises, such as Dynamics that stores data in a SQL Server database on the company’s data center, and others were cloud systems.
The client realized that it’s difficult to analyze performance across business units and disperse ERP systems. They envisioned a centralized and fully automated reporting solution that will consolidate data from all ERPs into a single repository so they can track sales across business units, sales people, vendors, and customers. In addition, they wanted their developers to enhance and maintain the solution, so simplicity and knowledge transfer were paramount.
Solution
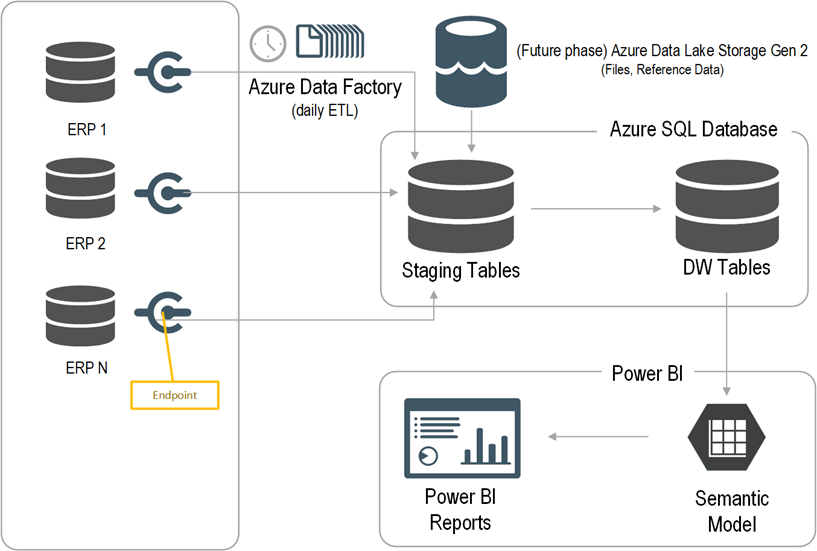
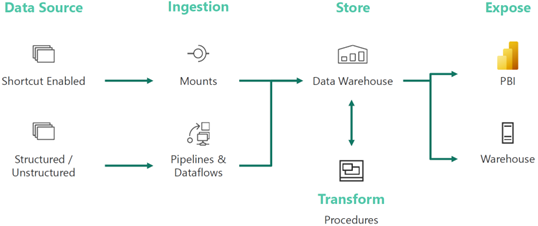
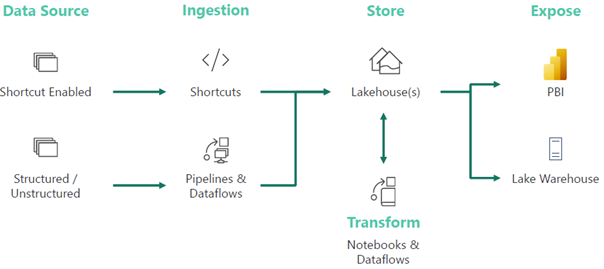
After assessing the current state and objectives, Prologika recommended and implemented the following cloud architecture:
Prologika adopted an iterative approach to integrate the data from all five ERP systems where each ERP had its own iteration. Laying out the foundation, the first iteration was the most important and had the following main deliverables:
Schema-first design – Prologika analyzed the requirements for Sales analytics and designed a star schema. The schema design was crucial because all other layers, such as ETL and semantic model, depend on it.
Endpoints – Prologika worked with the ERP subject matter expert to implement endpoints that will provide a data feed for each table in the schema.
ETL– Prologika used Azure Data Factory (ADF) no-code pipelines. The integration effort was dramatically reduced because all ERP endpoints would adhere to the same specification and hide the underlying details for each specific ERP, such as which tables would need to be joined. For best performance and fast knowledge transfer, Prologika followed the ELT pattern to transform and load the staged data using T-SQL stored procedures.
Data warehouse – Prologika staged, transformed, and loaded the data into a centralized data warehouse repository whose structure was based on the star schema design in step 1.
Semantic model – Prologika implemented a Power BI semantic model that delivered instantaneous insights and single-version of truth irrespective of the reporting tool used (Power BI, Excel, or third-party tools). The semantic model included the desired business metrics, such as time intelligence, variances, as well as data security.
Reports – Power BI report “packs”, such as Sales Analytics, Order Analytics, were developed that connected to the semantic model. Users also could use Excel and other tools to create pivot reports without extracting and duplicating data.
Benefits
The solution delivered the following benefits to the client:
Fast data integration – Each subsequent ETL iteration could benefit from the common architecture.
Data consolidation – Data was consolidated into a single repository.
Low licensing cost – The solution had a licensing cost in the range of $400/month, with the most spent in Power BI licensing.
Easy maintenance – The client was able to quickly learn, maintain, and enhance the solution.
To know a tool is to know its limitations – Teo’s proverb
In a previous post, I shared my overall impression of Fabric. In this post, I’ll continue exploring Fabric, this time sharing my thoughts on OneLake. If you need a quick intro to Fabric OneLake, the Josh Caplan’s “Build 2023: Eliminate data silos with OneLake, the OneDrive for Data” presentation provides a great overview of OneLake, its capabilities, and the vision behind it from a Microsoft perspective. If you prefer a shorter narrative, you can find it in the “Microsoft OneLake in Fabric, the OneDrive for data” post. As always, we are all learning and constructive criticism would be appreciated if I missed or misinterpreted something.
What’s Fabric OneLake?
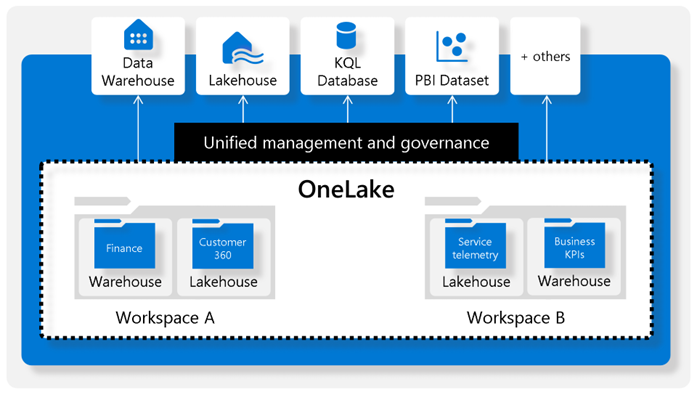
In a nutshell, OneLake is a Microsoft-provisioned storage where the ingested data and the data from the analytical (compute) engines are stored (see the screenshot below). Currently, PBI datasets (Analysis Services) are not saved in OneLake although one could anticipate that in the long run all Power BI data artifacts could (and should) end up in OneLake for Power BI Fabric-enabled workspaces.
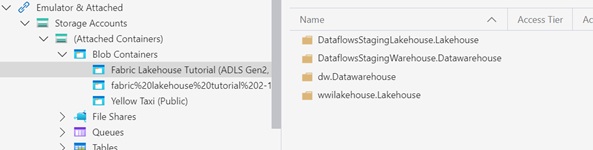
Behind the scenes, OneLake uses Azure Data Lake Storage (ADLS) Gen2, but there is an application wrapper on top of it that handles various tasks, such as management (you don’t have to provision storage accounts or external tables), security (Power BI security is enforced), and governance. OneLake is tightly coupled with the Power BI catalog and security. In fact, you can’t create folders outside the Power BI catalog so proper catalog planning is essential. When you create a Fabric workspace in Power BI, Microsoft provisions an empty blob container in OneLake for that workspace. As you provision additional Fabric Services, Fabric creates more folders and save data in these folders. For example, I can use Azure Storage Explorer to connect to a Fabric Lakehouse Tutorial workspace (https://onelake.blob.fabric.microsoft.com/fabric lakehouse tutorial) and see that I have provisioned a data warehouse called dw and a lakehouse called wwilakehouse. Microsoft has also added two additional system folders for data staging.
The Good
I like to have the data from the compute engines saved in one place and to be able to access that data as delta Parquet files. There is something serene to have this transparency after decades of not being able to pick under hood of some proprietary file format.
I also like very much the ability to use different engines to access that data (Microsoft calls this OneCopy although a more appropriate term in my opinion would be OneShare).
For example, I can query a table in the lakehouse directly from the data warehouse (such as select * from [wwilakehouse].dbo.dimension_customer) without having to create PolyBase external tables or use the serverless endpoint.
I welcome the possibility for better data virtualization both within and outside the organization. For example, in a lakehouse I can create shortcuts to other Fabric lakehouses, ADLS folders, and even external storage systems, such as S3 (Google and Dataverse coming up).
I’d like the governance aspect and the possibility it enables, such as lineage tracking and data security. In fact, OneSecurity is on the roadmap, where once you secure the data at OneLake, the data security bubbles up. It would be interesting to see how this will work and its limitations, as I’d imagine it won’t be as flexible as Power BI RLS.
The Bad
An API wrapper is a double-edged sword because it wraps and abstracts things. You really have to embrace the Power BI catalog and its security model along with their limitations, because there is no way around it.
For example, you can’t use Azure Data Explorer to change the ACL permissions on the folder or create folders where OneLake doesn’t like them (OneLake simply ignores certain APIs). Isn’t this a good thing though to centralize at a higher level, such as the Power BI workspace and prevent users to pain outside the canvas? Well, how about granting some external vendor permissions to write to OneLake, such as to upload files. From what I can see, even Shared Access Signature is not allowed. Storage account key is not an option too as you don’t have access to the storage account. So, to get around such limitations, you’d have to create separate storage accounts, but this defeats the promise of one lake.
Perhaps, this is an example that you don’t care much about. How about the lakehouse medallion architecture pattern which is getting popular nowadays for lakehouse-centric implementations. While you can create subfolders in the Lakehouse “unmanaged” zone (the Files folder), no such luck with the Tables folder to organize your delta lake tables in Bronze, Silver, and Gold zones. I can’t see another solution but to create a Power BI workspace for each zone.
Further, what if you must address data residency requirements of some litigation-prone country? The above-cited presentation correctly states that content can be geo-located but that will require purchasing more Power BI capacities irrespective of the fact that ADLS storage accounts can be created in different geo locations. Somehow, I start longing about bringing your own data lake and I don’t think that provisioning storage accounts is that difficult (in fact, a Power BI workspace already has the feature to link to BYO ADLS storage to save the output of Power Query dataflows). Speaking of accounts, I’m looking forwards to seeing how Fabric would address DevOps, such as Development and Production environments. Currently, a best practice is to separate all services so more than likely Microsoft will enhance Power BI pipelines to handle all Fabric content.
The Ugly
How can I miss another opportunity to harp again on Power BI for the lack of hierarchical workspaces? The domain feature that Microsoft shows in the presentation to logically group workspaces could be avoided to a great extent if Finance could organize content in subfolders and break security inheritance when needed, instead of ending up with workspaces, such as Finance North America, Finance EMEA, etc. Since OneLake is married to the Power BI catalog, more catalog flexibility is essential.
Given that OneLake and ADLS in general would be a preferred location for business users to store reference data, such as Excel files, Microsoft should enhance Office to support ADLS. Currently, Office apps can’t directly open and save files in ADLS (the user must download the file somehow, edit it, and then upload it back to ADLS). Consequently, business users favor other tools, such as SharePoint Online, which leads to decentralizing the data required for analytics.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-06-03 07:36:332023-06-03 13:26:18Fabric OneLake: The Good, the Bad, and the Ugly



 Enterprise Resource Planning (ERP) systems capture a wealth of information from main business processes within an organization, such as Sales, Inventory, Orders, etc. Therefore, a BI journey typically starts with analyzing the ERP data, with revenue analytics usually taking the center stage because of its vital metrics, such Revenue, Margin, Profit. In fact, this scenario has repeated so often for the past few years that Prologika has developed a fast-track implementation for ERP analytics. The client presented in this case study had more complicated integration needs, but other projects for both larger and smaller clients in the same or other industries have benefited from the same methodology.
Enterprise Resource Planning (ERP) systems capture a wealth of information from main business processes within an organization, such as Sales, Inventory, Orders, etc. Therefore, a BI journey typically starts with analyzing the ERP data, with revenue analytics usually taking the center stage because of its vital metrics, such Revenue, Margin, Profit. In fact, this scenario has repeated so often for the past few years that Prologika has developed a fast-track implementation for ERP analytics. The client presented in this case study had more complicated integration needs, but other projects for both larger and smaller clients in the same or other industries have benefited from the same methodology.