Fabric OneLake: The Good, the Bad, and the Ugly
To know a tool is to know its limitations – Teo’s proverb
In a previous post, I shared my overall impression of Fabric. In this post, I’ll continue exploring Fabric, this time sharing my thoughts on OneLake. If you need a quick intro to Fabric OneLake, the Josh Caplan’s “Build 2023: Eliminate data silos with OneLake, the OneDrive for Data” presentation provides a great overview of OneLake, its capabilities, and the vision behind it from a Microsoft perspective. If you prefer a shorter narrative, you can find it in the “Microsoft OneLake in Fabric, the OneDrive for data” post. As always, we are all learning and constructive criticism would be appreciated if I missed or misinterpreted something.
What’s Fabric OneLake?
In a nutshell, OneLake is a Microsoft-provisioned storage where the ingested data and the data from the analytical (compute) engines are stored (see the screenshot below). Currently, PBI datasets (Analysis Services) are not saved in OneLake although one could anticipate that in the long run all Power BI data artifacts could (and should) end up in OneLake for Power BI Fabric-enabled workspaces.
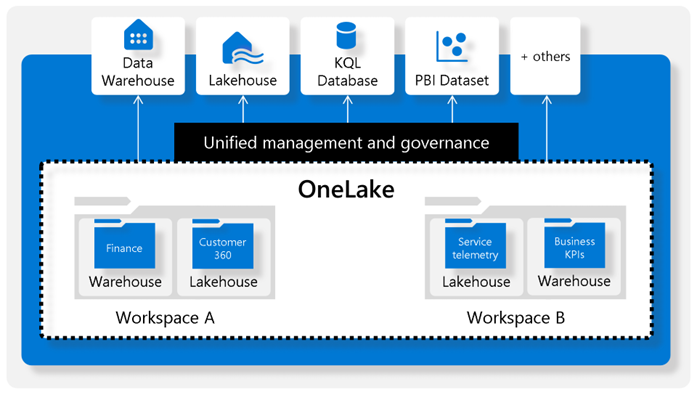
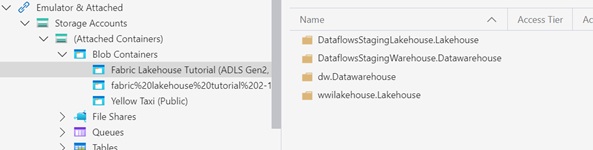
Behind the scenes, OneLake uses Azure Data Lake Storage (ADLS) Gen2, but there is an application wrapper on top of it that handles various tasks, such as management (you don’t have to provision storage accounts or external tables), security (Power BI security is enforced), and governance. OneLake is tightly coupled with the Power BI catalog and security. In fact, you can’t create folders outside the Power BI catalog so proper catalog planning is essential. When you create a Fabric workspace in Power BI, Microsoft provisions an empty blob container in OneLake for that workspace. As you provision additional Fabric Services, Fabric creates more folders and save data in these folders. For example, I can use Azure Storage Explorer to connect to a Fabric Lakehouse Tutorial workspace (https://onelake.blob.fabric.microsoft.com/fabric lakehouse tutorial) and see that I have provisioned a data warehouse called dw and a lakehouse called wwilakehouse. Microsoft has also added two additional system folders for data staging.
The Good
I like to have the data from the compute engines saved in one place and to be able to access that data as delta Parquet files. There is something serene to have this transparency after decades of not being able to pick under hood of some proprietary file format.
I also like very much the ability to use different engines to access that data (Microsoft calls this OneCopy although a more appropriate term in my opinion would be OneShare).
For example, I can query a table in the lakehouse directly from the data warehouse (such as select * from [wwilakehouse].dbo.dimension_customer) without having to create PolyBase external tables or use the serverless endpoint.
I welcome the possibility for better data virtualization both within and outside the organization. For example, in a lakehouse I can create shortcuts to other Fabric lakehouses, ADLS folders, and even external storage systems, such as S3 (Google and Dataverse coming up).
I’d like the governance aspect and the possibility it enables, such as lineage tracking and data security. In fact, OneSecurity is on the roadmap, where once you secure the data at OneLake, the data security bubbles up. It would be interesting to see how this will work and its limitations, as I’d imagine it won’t be as flexible as Power BI RLS.
The Bad
An API wrapper is a double-edged sword because it wraps and abstracts things. You really have to embrace the Power BI catalog and its security model along with their limitations, because there is no way around it.
For example, you can’t use Azure Data Explorer to change the ACL permissions on the folder or create folders where OneLake doesn’t like them (OneLake simply ignores certain APIs). Isn’t this a good thing though to centralize at a higher level, such as the Power BI workspace and prevent users to pain outside the canvas? Well, how about granting some external vendor permissions to write to OneLake, such as to upload files. From what I can see, even Shared Access Signature is not allowed. Storage account key is not an option too as you don’t have access to the storage account. So, to get around such limitations, you’d have to create separate storage accounts, but this defeats the promise of one lake.
Perhaps, this is an example that you don’t care much about. How about the lakehouse medallion architecture pattern which is getting popular nowadays for lakehouse-centric implementations. While you can create subfolders in the Lakehouse “unmanaged” zone (the Files folder), no such luck with the Tables folder to organize your delta lake tables in Bronze, Silver, and Gold zones. I can’t see another solution but to create a Power BI workspace for each zone.
Further, what if you must address data residency requirements of some litigation-prone country? The above-cited presentation correctly states that content can be geo-located but that will require purchasing more Power BI capacities irrespective of the fact that ADLS storage accounts can be created in different geo locations. Somehow, I start longing about bringing your own data lake and I don’t think that provisioning storage accounts is that difficult (in fact, a Power BI workspace already has the feature to link to BYO ADLS storage to save the output of Power Query dataflows). Speaking of accounts, I’m looking forwards to seeing how Fabric would address DevOps, such as Development and Production environments. Currently, a best practice is to separate all services so more than likely Microsoft will enhance Power BI pipelines to handle all Fabric content.
The Ugly
How can I miss another opportunity to harp again on Power BI for the lack of hierarchical workspaces? The domain feature that Microsoft shows in the presentation to logically group workspaces could be avoided to a great extent if Finance could organize content in subfolders and break security inheritance when needed, instead of ending up with workspaces, such as Finance North America, Finance EMEA, etc. Since OneLake is married to the Power BI catalog, more catalog flexibility is essential.
Given that OneLake and ADLS in general would be a preferred location for business users to store reference data, such as Excel files, Microsoft should enhance Office to support ADLS. Currently, Office apps can’t directly open and save files in ADLS (the user must download the file somehow, edit it, and then upload it back to ADLS). Consequently, business users favor other tools, such as SharePoint Online, which leads to decentralizing the data required for analytics.


