The moment you add a calculation group to your model, Power BI sets DiscourageImplicitMeasures = True on the model. Although this property can trick you to be believe that they are still supported, you can’t create implicit measures, such as by dragging a numeric field on the report to summarize that field. That’s because implicit measures are created as inline calculations which calculation groups don’t support.
Also, there is a current issue where when you add a column from a calculation group to a filter, “Require single selection” is set to on and it can’t be changed. Therefore, you won’t be able to filter multiple calculation items, such as to present t only MTD, QTD, and YTD from a list of many items in your calculation group. As a workaround, you add a calculated column that flags the desired values and filter on it. You can vote to expedite the fix here.
I’ve noticed severe performance degradation after refreshing a Power BI Desktop model with some five million rows. The Power BI Desktop process showed a sustained 50-60 % utilization for minutes in the Windows Task Manager. I did a profiler trace and I saw expensive DAX queries like these:
As it turned out, Power BI Desktop autogenerates these queries when building a Q&A index. The 100-size limit is because Power BI wants to keep the index small. In addition, values that are longer than 100 characters are unlikely to be asked by the user. Why not check thd the maximum column value and skip the column? Power BI wants to skip instances that are too long but still index the remaining instances of the column.
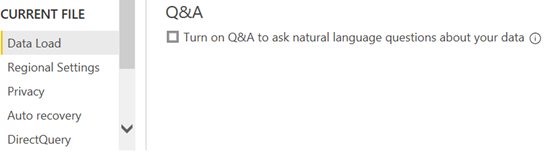
To avoid this performance degradation when modeling on the desktop you could disable the Q&A feature. This will also disable smart narratives because they depend on Q&A.
To do this, go to the File, Options and Settings, Options, and turn off the Q&A option.
If Power BI Desktop is connected to a remote model, such as a published Power BI dataset, you’ll see also an option to create a local index. This option was added because Power BI needs to ask user permission to query data from remote sources, build the data index, and store it on user’s machine. By default, it’s disabled until the user explicitly turns on Q&A. For import models, as the data is already on user’s machine, Power BI doesn’t need to ask the permission to query data anymore. That’s why the option to build a local index is not applicable to models with imported data.
Disabling the Q&A in Power BI Desktop affects the local file only. When you publish the model, you reenable Q&A from the data settings if you want end users to use Q&A features. For remote models, if you leave the first option, “Turn on Q&A to ask …”, on, but disable the second option, “Create a local index….”, and publish the model to the service, then Q&A will be enabled in the service by default. That is, you don’t have to go to dataset settings to enable Q&A for that model. For import models, you have to disable the first option, and then after publishing the model to the service, you have to go to dataset settings to enable Q&A there.
I’m excited to announce the availability of the sixth edition of my Applied Microsoft Power BI book! When the first edition was published in January 2016, it was the first Power BI book at that time and it had less than 300 pages. Since then, I helped many companies adopt or transition to Power BI and taught hundreds of students. It’s been a great experience to witness the momentum surrounding Power BI and how the tool has matured over time. As a result, the book also got thicker and it almost doubled in size. However, I believe what’s more important is that this book provides systematic, yet dependent, view by showing what Power BI can do for four types of users (business users, analysts, pros, and developers).
To my understanding, this is the only Power BI book that gets annual revisions to keep it up to date with this ever changing technology! Because I had to draw a line somewhere, Applied Microsoft Power BI (6th edition) covers all features that are in preview or released by December 2020. As with my previous books, I’m committed to help my readers with book-related questions and welcome all feedback on the book discussion forum on the book page. While you are there, feel free to check out the book resources (sample chapter, front matter, and more). I also encourage you to follow my blog at https://prologika.com/blog and subscribing to my newsletter at https://prologika.com to stay on the Power BI latest.
Bring your data to life for the sixth time! Keep on reading and learning!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2021-01-02 08:46:342021-01-02 08:46:34Applied Power BI Book (6th Edition)
Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, January 4th, at 6:30 PM. James Serra (Big Data/Data Warehouse Evangelist at Microsoft) will share best practices around staging data in an organizational data lake. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
The data lake has become extremely popular, but there is still confusion on how it should be used. In this presentation I will cover common big data architectures that use the data lake, the characteristics and benefits of a data lake, and how it works in conjunction with a relational data warehouse. Then I’ll go into details on using Azure Data Lake Store Gen2 as your data lake, and various typical use cases of the data lake. As a bonus I’ll talk about how to organize a data lake and discuss the various products that can be used in a modern data warehouse.
Speaker:
James Serra is a big data and data warehousing solution architect at Microsoft. He is a thought leader in the use and application of Big Data and advanced analytics. Previously, James was an independent consultant working as a Data Warehouse/Business Intelligence architect and developer. He is a prior SQL Server MVP with over 35 years of IT experience. James is a popular blogger (JamesSerra.com) and speaker. He is the author of the book “Reporting with Microsoft SQL Server 2012”.
Prototypes without pizza:
Power BI Latest
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-12-31 08:47:562021-02-16 01:50:24Atlanta MS BI and Power BI Group Meeting on January 4th
The cloud is supposed to make things easier, right? Well, not necessarily, as a client and I have recently discovered. They use Dynamics Online 365 and they are facing long refresh times for Power BI datasets that import data from Dynamics. Dynamics saves its data in an Azure SQL Database, which now goes by the name Dataverse (previously known as Common Data Service for Apps or CDS-A). I wrote two years ago about the pros and cons of CDS-A. The ugly award back then went to getting the data out of Dynamics. I wrote “For years people were complaining that after migrating from the on-premises Dynamics to the cloud, they lost the ability to connect to its database directly and they had to rely on the REST APIs (slow) or Data Export Service to export the data to an SQL Server Database (fast but requires additional effort and budget).”
Have things changed in the past two years? Yes, but not necessarily for better. Microsoft now has three ways of getting the data out of Dynamics (staging to Azure SQL Database has been deprecated).
Option
Pros
Cons
Connect to Dynamics REST APIs
Ability to pass predicates on the REST API call, such as column lists, joins, and filters
Slow, no query folding
Staging to ADLS
Microsoft preferred approach, automatic data synchronization
No query folding, no DirectQuery, not enough compute resources
DTS endpoint
Import and DirectQuery modes, query folding works
Not enough compute resources, not a strategic option
Let’s take a more in-depth look at the new options: staging to ADLS and the DTS endpoint.
Staging to ADLS
Microsoft invests heavily and recommends staging the Dynamics data out to Azure Data Lake Storage Gen 2 (ADLS). Once you set up your data lake, you go to the Power Platform Admin Center and specify which entities you want to stage out. Once the initial snapshot completes, changes to Dynamics entities are automatically propagated in almost real time. From there, you can use the Power BI “Azure Data Lake Storage Gen 2” connector (make sure to expand the “cdm” folder) to import the data. Microsoft explains the process in more detail in this video. What a clumsy solution though! From a perfect store (SQL Server) that supports querying, joining, query folding, etc, we stage the data out and save it as flat files and lose all of these. You would think that the Power BI refreshes will be blazingly fast. After all, we read from a bunch of CSV files. Unfortunately, I ran some tests to import an entity that had around 1 million rows and I had to cancel it after one hour. By comparison, the original query that used the REST API clocked at 30 minutes. How come?
The moment you stage data to flat files you embrace a very inefficient way of consuming that data. Since there is no “server”, Power Query can’t pass predicates to the data source. So, if you have an entity with a million rows and you need only a few columns and a subset of rows, Power Query would load all the data from the data lake before it applies the predicates.
As we’ve found, ADLS will not cut through this much data as it does not have the compute and Power Query itself does not bring enough compute for large datasets and joins, etc. Microsoft’s solution? Throw in more compute by using the Synapse SQL on-demand connector so the architecture now becomes Dynamics -> ADLS -> Synapse (OD) -> Power BI! Of course, this will entail an additional investment on your part in the “compute” layer, but this is the price to pay when you want your data fast, right?
Consider the ADLS staging only for small entities unless you want to invest in Synapse. I personally decided against pursuing this path as it’s an overkill for the simple request to get access to the data.
TDS Endpoint
I rejoiced when I recently learned that we know have a TDS endpoint to Dataverse. TDS is the native protocol that SQL Server uses to communicate with the client app. The TDS endpoint is essentially a wrapper on top of the Dataverse Azure SQL Database. And Power BI has a Dataverse connector that supports import and DirectQuery modes. Time to celebrate, right? This is exactly what we wanted since now we don’t have to worry about staging the data out and running out of compute thanks to the horribly inefficient way of loading data from ADLS. We now have real-time access to data and Power Query can pass predicates to SQL Server.
Unfortunately, no luck importing that entity as the refresh timed out. As it turned out, TDS endpoint is meant for real-time reporting over relatively smaller (no definition from Microsoft about “smaller”) datasets. With large datasets and joins involved queries would require even more compute and processing time. So, back to square one. We don’t have enough compute there too and there is no workaround. And Microsoft doesn’t plan to invest in the TDS endpoint since staging to ADLS is their preferred solution.
I failed to understand what prevents Microsoft from assigning more “compute” to the TDS endpoint. Surely, customers spending millions in licensing fees deserve an option for a dedicated environment with enough compute like Power BI offers with premium capacities. If the concern is that direct access can impact production loads, this is something the client should worry about and address, such by connecting to the read-only replica of the Azure SQL Database, which I’m sure it’s privately available.
I always consider it a travesty when SaaS apps don’t give you access to the data in its native storage, which usually is a relational database, and therefore a perfect store. Join my quest to persuade Microsoft in providing direct access with enough compute to your data in the cloud as you have with their on-prem offerings.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-12-30 15:09:002021-01-03 21:49:54Microsoft Dataverse: A Verse Without Rhymes
I hope you’re enjoying the holidays. In this newsletter, I’ll discuss a very important enhancement to Power BI that lets business users extend semantic models. But before I get to it, a quick announcement. I’m putting the finishing touches of the sixth edition of my “Applied Microsoft Power BI”! It should be available on Amazon in the first days of 2021. I’ve been updating this book thoroughly every year since 2015 to keep it up to the date with this fast-changing technology.
I’ve written extensively on the important role that EDW and organizational semantic models have for delivering the “Discipline at the core and flexibility at the edge” tenant for effective data analytics. Analysis Services Tabular is available in three SKUs: Power BI, Azure Analysis Services, and SSAS, and it’s the workhorse of Power BI Service. When you publish a Power BI desktop file, it becomes a database hosted in some Analysis Services Tabular server managed by Microsoft.
How live connections work
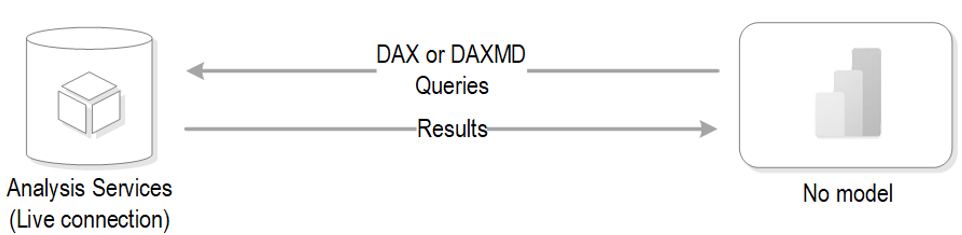
As the diagram below shows, Power BI uses a special live connectivity option when you connect live to Analysis Services in all its flavors (Multidimensional, Tabular, and Power BI published datasets) and SAP (SAP Hana and SAP Data Warehouse). In this case, the xVelocity engine isn’t used at all and the model is absent. Instead, Power BI connects directly to the data source and sends native queries. For example, Power BI generates DAX queries when connected to Analysis Services .
There is no Power Query in between Power BI Desktop and the data source, and data transformations and relationships are not available. In other words, Power BI becomes a presentation layer that is connected directly to the source, and the Fields pane shows the metadata from the model. This is conceptually very similar to connecting Excel to Analysis Services.
Unfortunately, once you connected Power BI Desktop to a multidimensional data source, that remote model was the only data source available for you.
Understanding the change
Power BI Desktop (December 2020 release) removes this long-standing limitation for live connections to Tabular. In the special case of connecting to a dataset published to Power BI Service and Azure Analysis Services (on-prem SSAS is not supported), you can switch from live connectivity to DirectQuery and add external data to build a composite model. This feature is very important because it allows business users to extend semantic models that could be sanctioned by someone else in the organization!
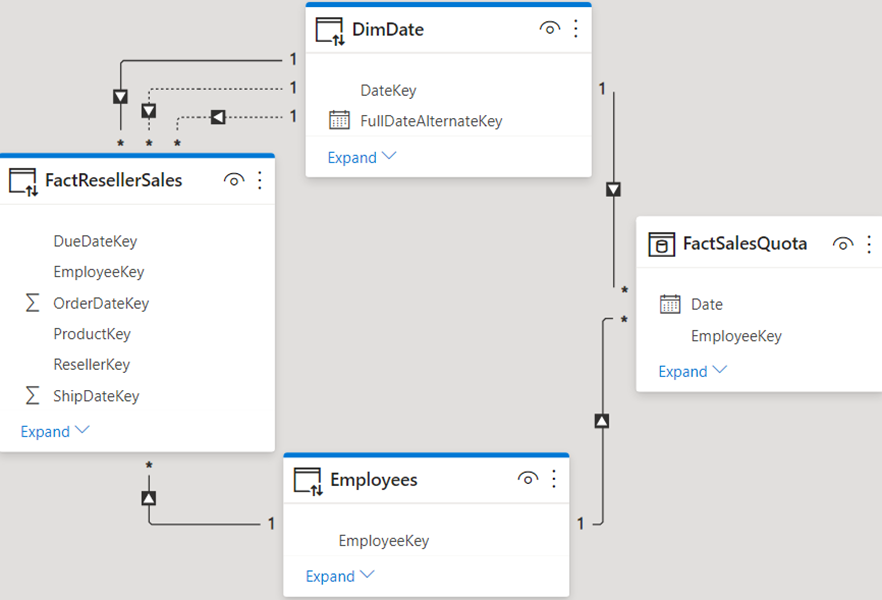
If the first connection you make is to the remote model then the connection will use Live Connect. The Power BI Desktop file will not store any metadata or data, expect for the connection string. The moment you use “Get Data” to connect to another source and accept the prompt, Power BI Desktop replaces permanently the live connection with a local DirectQuery layer and imports the metadata of the remote model. Even if you remove all external tables, you won’t be able to “undo” the change and switch back the file to Live Connect. In the diagram below, FactResellerSales, DimDate, and Employees tables are hosted in the remote model while FactSalesQuota is an external table that is imported (could be in DirectQuery mode).
What happens behind the scenes
In a nutshell, DirectQuery to Analysis Services Tabular is like other DirectQuery sources where DAX queries generated by Power BI are translated to native queries. However, in this case Power BI either sends the DAX queries directly to the remote model when possible or breaks them down into lower-level DAX queries. In the latter case, the DAX queries are executed on the remote model and then the results are combined in Power BI to return the result for the original DAX query. So, depending on the size of the tables involved in the join, this intermediate layer may negatively impact performance of visuals that mix fields from different data sources.
Applying your knowledge about composite models, you might attempt to configure the dimensions in dual storage, but you’ll find that this is not supported. Behind the scenes, Power BI handles the join automatically, so you do not need to set the storage mode to Dual. It’s interpreted as Dual internally. You can make metadata changes on top of the remote model. For example, you can format fields, create custom groups, implement your own measures, and even calculated columns (calculated columns are now evaluated at runtime and not materialized). The changes you make never affect the remote model. They are saved locally in the DirectQuery model.
Currently, row-level security (RLS) doesn’t propagate from the remote model to the other tables. For example, the remote model might allow salespersons to see only their sales data by applying RLS to the Employees table. However, the user will be allowed to see all the data in the FactSalesQuota table because it’s external to the remote model and RLS doesn’t affect it.
Teo Lachev
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
I’m watching the witness testimonies for election irregularities in Georgia (the state where I live). I’m shocked about how this election became such a mess and international embarrassment. United States spent 10 billion on the 2020 election. Georgia alone spent more than 100 million on some machines the security experts said can be hacked in minutes. If we add the countless number of manhours, investigations, and litigations, these numbers will probably double by the time the dust settles down.
What did we get back? Based on what I’ve heard, 50% of Americans believe this election is rigged, just like 50% believed so in 2016. The 2020 election added of course more options for abuse because of the large number of mail-in ballots. It’s astonishing how manual and complicated the whole process is, not to mention that each state does things differently. But the more human involvement and moving parts, the higher the attack vector and probability for intentional or unintentional mishandling due to “human nature”, improper training, or total disregard of rules. I casted an absentee ballot without knowing how it was applied.
So, your humble correspondent thinks that it’s about time to computerize voting. Where humans fall short, machines take over. Unless hacked, algorithms don’t make “mistakes”. How about a modern Federal Internet Voting system that can standardize voting in all states? If the Government can put together a system for our obligations to pay taxes, it should be able to do it for the right to vote. If the most advanced country can get a vaccine done in six months, we should be able to figure out how to count votes. Just like in data analytics, elections will benefit from a single version of truth. Despite the security concerns surrounding a web app, I believe it will be far more secure that this charade that’s going on right now. In this world where no one trusts anyone, we can’t apparently trust bureaucrats to do things right.
Other advantages:
Anybody can vote from any device so no vote “suppression”
Better authentication (face recognition and capture, cross-check with other systems, ML, etc.)
Vote confirmation
Ability to centralize security surveillance and monitoring by an independent committee
Report results in minutes
Additional options for analytics on post-election results
Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, December 7th, at 6:30 PM. Patrick LeBlanc (A Guy in the Cube) will share techniques to optimize your Power BI data models. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
When working with your Power BI Data Model/Dataset there are certain that can be done to optimize the size of the model. With that, there are certain thing that can be done that wreaks havoc on your Data Model. In this session we will walk you through several things that can be done to ensure that your data model is optimize for the best performance. We will discuss and demonstration how items such as data types, model properties, and DAX calculations and adversely affect the size of the model. That’s just a small list of items, join the meeting to learn all the tips and tricks.
Speaker:
Patrick LeBlanc is a currently a Principal Program Manager at Microsoft and a contributing partner to Guy in a Cube. Along with his 15+ years’ experience in IT he holds a Masters of Science degree from Louisiana State University. He is the author and co-author of five SQL Server books. Prior to joining Microsoft he was awarded Microsoft MVP award for his contributions to the community. Patrick is a regular speaker at many SQL Server Conferences and Community events.
Prototypes without pizza:
“Power BI Latest” by Teo Lachev
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-12-03 14:43:442021-02-17 01:01:43Atlanta MS BI and Power BI Group Meeting on December 7th
In its early days, Power BI introduced an endpoint to support Analyze in Excel (AIXL). Later, the “Power BI datasets” connector relied on this endpoint to support connecting to published datasets. The AIXL endpoint was never intended to support other clients. It has a few limitations, such as it doesn’t support long running requests and write operations. Also, it doesn’t support importing data as you’ve probably found when connecting to published datasets.
Later, Power BI Premium added the XMLA endpoint to support external clients connected to datasets in a premium capacity. If you’re on Premium, you should use the XMLA endpoint to connect external clients by using the Azure Analysis Services connector. Unfortunately, if you do so in PBI Desktop, “Get Data” won’t give you the nice UX that shows you which datasets are certified.
It will be nice if Microsoft adds a mechanism in the future where the client libraries will automatically take the new style of connection string (workspace + dataset name) and redirect to the AIXL endpoint if the dataset is hosted in a shared capacity or the XMLA endpoint if the dataset is in Premium. Or even better, support the XMLA endpoint for both shared and premium capacities.
In summary:
AIXL and PBI Desktop use the AIXL connections.
You should never use AIXL connection strings directly.
Business users should continue using the “Power BI datasets” connector.
Other external clients should use the XMLA endpoint to connect to a dataset in a premium capacity.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-11-29 09:54:212020-11-29 09:54:21Understanding Power BI Endpoints
A Happy Thanksgiving to all of you! I’m thankful for your interest in and support of my work.
I’m glad that Microsoft has recently updated the Power BI tenant export settings and thus mitigated the the complaints I had in my “A False Sense of Data Security” blog. Disabling the “Export to …” settings, which now applies also to paginated reports, no longer disables live connections to published datasets and features that depend on it, such as connecting to published datasets in Power BI Desktop, accessing the Power BI Premium XMLA endpoint, and Analyze in Excel. Instead, there is a clear distinction and now there two separate settings that affect external connectivity (for XMLA connectivity, the XMLA Endpoint capacity setting must be enabled in Read-Only or Read-Write modes):
Allow live connections – This is a catch-all setting for allowing the live connectivity features.
Allow XMLA endpoints and Analyze in Excel with on-premises datasets — Microsoft felt that there should be a separate setting (besides “Allow live connections”) for connecting to on-prem datasets. However, just like disabling “Allow live connections”, this setting also effectively disables the Power BI Premium XMLA endpoint preventing other tools, such as Visual Studio or SSMS, to connect to published datasets.