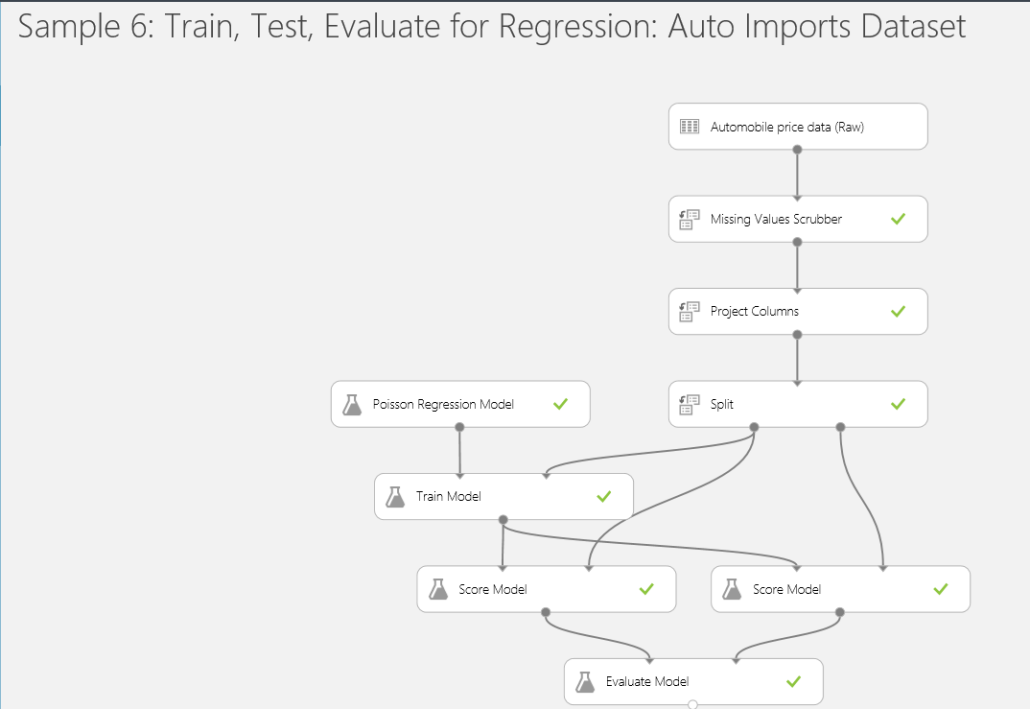
Excel Timeline Slicers
In an attempt to improve visualizations of Excel-based dashboards, Excel 2013 introduced a Timeline filter. Specifically designed to visualize dates, the Timeline filter works similarly to regular slicers which were introduced in Excel 2010. Similar to a regular slicer, Timeline connects at the connection level and is capable of filtering multiple reports. It supports also extended selections, such as to select multiple years.
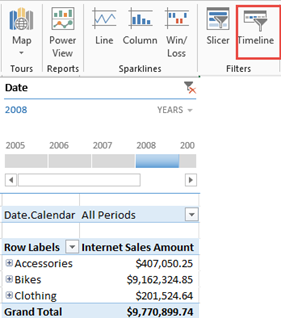
However, there are important differences between Timeline and regular slicers which become important when you connect to Multidimensional.
- The Timeline slicer always generates a subselect clause in the resulting MDX query even if a single value is selected. Because of this, the CurrentMember of the Date dimension is not set and any time calculations that dependent on [Date].[Hierarchy].CurrentMember won’t work. By contrast, a regular slicer is more intelligent. If the user selection results in a single value, a WHERE clause is generated and CurrentMember works. If multiple values are selected then it generates a subselect and CurrentMember won’t work.
- If the report has a report-specific filter, such as in the example above, Timeline forces the filter to its default value (All Periods if the All member is the default member or whatever the default member is set to in the cube). If the default filter is overwritten in the cube, such as to default the date to the last date with data, the report-specific filter and the Timeline selection might result in an exclusive filter and then no results will be shown. By contrast, a regular slicer always passes the user selection to the report filters.
Here is a sample MDX query generated by Excel when Timeline is set to year 2007.
SELECT NON EMPTY Hierarchize({DrilldownLevel({[Product].[Product Categories].[All Products]},,,INCLUDE_CALC_MEMBERS)}) DIMENSION PROPERTIES PARENT_UNIQUE_NAME,HIERARCHY_UNIQUE_NAME ON COLUMNS FROM (SELECT Filter([Date].[Date].Levels(1).AllMembers, ([Date].[Date].CurrentMember.MemberValue>=CDate(“2007-01-01”) AND [Date].[Date].CurrentMember.MemberValue<CDate(“2008-01-01”))) ON COLUMNS FROM [Adventure Works]) WHERE ([Date].[Calendar].[All Periods],[Measures].[Internet Sales Amount]) CELL PROPERTIES VALUE, FORMAT_STRING, LANGUAGE, BACK_COLOR, FORE_COLOR, FONT_FLAGS
And here is the resulting MDX from a regular slicer set to year 2007 (notice the WHERE clause):
SELECT NON EMPTY Hierarchize({DrilldownLevel({[Product].[Product Categories].[All Products]},,,INCLUDE_CALC_MEMBERS)}) DIMENSION PROPERTIES PARENT_UNIQUE_NAME,HIERARCHY_UNIQUE_NAME ON COLUMNS
FROM [Adventure Works] WHERE ([Date].[Calendar].[Calendar Year].&[2007],[Measures].[Internet Sales Amount])
CELL PROPERTIES VALUE, FORMAT_STRING, LANGUAGE, BACK_COLOR, FORE_COLOR, FONT_FLAGS
If you decide to use Timeline, use it only with reports that don’t include calculations that rely on date current member. Ideally, a future Excel enhancement would make Timeline behave as a regular slicer to increase its usefulness and align its behavior with regular slicers.