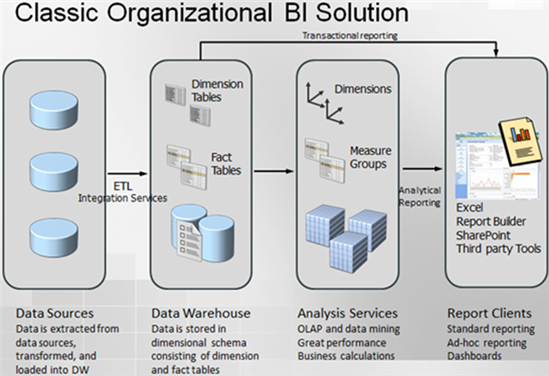
Improving Tabular Design Experience
When you develop an organizational Tabular model in SSDT, there is always an implicit processing phase for each action you perform, such as renaming columns, creating hierarchies, changing formatting, and so on. This “data-driven” paradigm could be both a blessing and a curse. A blessing, because you always work with data and you don’t have to explicitly process the model to see the effect of the changes. And a curse, because each time you make a change the UI blocks until the change is committed and this can get old pretty soon.
Note: As long as you don’t use the Table Properties dialog or explicitly refresh the data, all changes are done directly in the Tabular database and Tabular doesn’t re-query the data source to refresh the data.
While waiting for Microsoft to make the necessary changes, here are a few tips to improve your Tabular design experience:
- In my experience, the size of the dataset doesn’t affect the duration of the “refresh” step. However, I always use a small dataset during development for faster processing. To do this, if you have a large table, partition the table in Tabular and load only one (e.g. the smallest) partition. If you have already loaded all partitions, you can clear all but one with Process Clear. Now, you have a small dataset to work with during development. Once you deploy to the QA or production server, you can process all partitions.
- Disable Automatic Calculation – To do this, go to the Model menu and click Calculation Options -> Manual Calculation. Sometimes (depending on model/calculation complexity) disabling automatic calculation in SSDT may help make modeling operations more responsive. To update the calculated columns, once you’re done with the changes, do Model->Calculate Now. Thanks to Marius for this tip.
- While the size of the dataset doesn’t affect the refresh duration, the hardware configuration of your development machine does. Suppose you have an underpowered company laptop and a more powerful personal laptop (lots of memory, solid state drive, many cores, etc.) If your company policy allows using your personal laptop, follow these steps to temporarily switch development during the change-intensive part of the design process:
- Copy the source from the first laptop to your personal laptop.
- Back up and restore the workspace database to your local Analysis Services Tabular instance. If you follow my first tip, the workspace database should be fairly small.
- Load the project in SSDS and double-click the Model.bim file to initialize your environment. This will create a second empty workspace database to your local Tabular instance. Close the solution in SSDT. Now, open the Model.bim_<your name>.settings file in Notepad, find the <Database>element and change it to the name of the original workspace database. Open the solution in SSDT. Now you should see the data in your original workspace database.
- Perform the design changes. As a comparison, it takes about 5 seconds to commit a change on my laptop vs. 15 seconds on an underpowered laptop.
- Once you’re done with the changes, replace Model.bim and Model.bim.layout files on your company’s laptop.