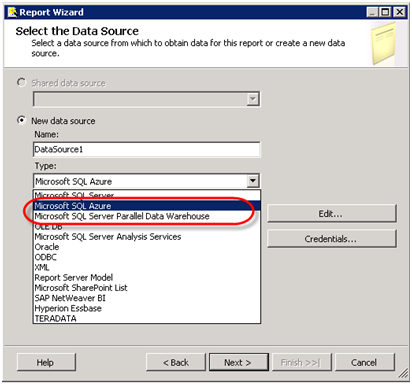
Where is RDLOM in R2?
After covering the cool new stuff in R2, it’s time to talk about the uncool. One R2 change that really vexes me is RDLOM. RDLOM, short for Report Definition Language Object Model, lets developers program RDL in object-oriented way as opposed to using XML. RDLOM could save you a lot of effort when you have to meet more advanced requirements that involve pre-processing RDL. For example, in one of my projects we had to implement a wizard that would walk business users through steps to generate an ad-hoc report. Behind the scenes, the wizard would generate the report definition by using a custom RDLOM which we developed since back then Microsoft didn’t have their own. I included a scaled-down version of our implementation in my TechEd 2007 code sample. Although it took us a while to get our RDLOM implemented, it turned out to be invaluable down the road. Since we didn’t have to use XML API to manipulate RDL, it simplified programming RDL. For another project, we used RDLOM to let the customer specify which sections they want to see on the report. Once the selection was made, we would remove the unwanted sections from a report template. The list of real-life scenarios that could take advantage of RDLOM goes on …
Apparently, I wasn’t the only one bugging Microsoft about RDLOM that ships with SSRS and they promised that this will happen at TechED 2007 USA. Sure enough, SSRS 2008 brought us an unsupported version which I blogged about and covered more extensively in my Applied SSRS 2008 book. Although unsupported, the SSRS 2008 RDLOM was very useful. It was implemented in a single assembly (Microsoft.ReportingServices.RdlObjectModel.dll), exposed all RDL elements as objects, and supported serializing and deserializing RDL.
Alas, this will come to pass with R2. Upgrading to R2, you’ll find that the classes in Microsoft.ReportingServices.RdlObjectModel are marked as internal so you cannot use this assembly. Instead, RDLOM got moved into the Microsoft.ReportingServices.Designer.Controls.dll assembly. The good news is that there are rumors that RDLOM may get documented. Now the bad news:
- Clearly, R2 RDLOM was not meant to be distributed. While you need to reference explicitly only Microsoft.ReportingServices.Designer.Controls and Microsoft.ReportingServices.RichText assemblies you’ll find that they are dependent on other assemblies and you need to distribute a total of 25 assemblies resulting in a whopping 25 MB of referenced code. One way to avoid shipping so many assemblies to deploy your application in the BIDS or Report Builder 3.0 folders.
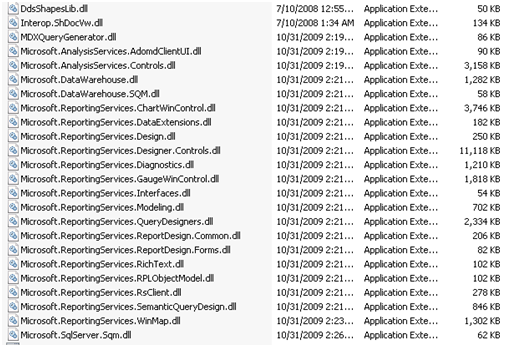
- R2 RDLOM will be 32-bit only because BIDS and Report Builder are 32-bit only.
- R2 RDLOM doesn’t support serializing the object model. I found a hack that uses .NET reflection to invoke the internal Serialize method of the old RDLOM 2008.
The RDLOM R2 C# console application bundled in this code sample demonstrates how you can use the “new” RDLOM. Besides referencing the new assemblies, you need to use the Load method to deserialize RDL to the object model:
report = Report.Load(fs);
And the above-mentioned hack to serialize it back to disk or stream.
using (FileStream os = new FileStream(ReportPath, FileMode.Create)) {
Assembly assembly = Assembly.GetAssembly(typeof(Report));
object mc = assembly.CreateInstance(“Microsoft.ReportingServices.RdlObjectModel.Serialization.RdlSerializer”);
Type t = mc.GetType();
MethodInfo mi = t.GetMethod(“Serialize”, new Type[] { typeof(Stream), typeof(Report) });
report = (Report)mi.Invoke(mc, new object[] { os, report });
}
Other than that, RDLOM remains virtually unchanged from 2008 excluding that it now supports the R2 enhancements to RDL. What if you don’t need this overhead but you need to make small changes to RDL that don’t necessarily require an object-oriented layer. I’ve found that the easiest way to do this and avoid XML programming is to use LINQ to XML. The LINQ to XML project included in the same sample demonstrates this approach. For example, the following code changes the data source reference of the first data source.
static void Main(string[] args) {
XElement report = XElement.Load(“report.rdl”);
string dns = “{“ + report.GetDefaultNamespace() + “}”;
XElement ds = report.Element(dns + “DataSources”).Element(dns + “DataSource”).Element(dns + “DataSourceReference”);
ds.Value = “/Data Sources/AdventureWorksAS2008”;
report.Save(“report1.rdl”); }
Not happy about the RDLOM story? Join the movement and vote for my suggestion on connect.microsoft.com to have a supported RDLOM.